 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data Size Sensitivity in Unsupervised Rhyme Recognition
Apr 09, 2026Rhyme is deceptively intuitive: what is or is not a rhyme is constructed historically, scholars struggle with rhyme classification, and people disagree on whether two words are rhymed or not. This complicates automated rhymed recognition and evaluation, especially in multilingual context. This article investigates how much training data is needed for reliable unsupervised rhyme recognition using RhymeTagger, a language-independent tool that identifies rhymes based on repeating patterns in poetry corpora. We evaluate its performance across seven languages (Czech, German, English, French, Italian, Russian, and Slovene), examining how training size and language differences affect accuracy. To set a realistic performance benchmark, we assess inter-annotator agreement on a manually annotated subset of poems and analyze factors contributing to disagreement in expert annotations: phonetic similarity between rhyming words and their distance from each other in a poem. We also compare RhymeTagger to three large language models using a one-shot learning strategy. Our findings show that, once provided with sufficient training data, RhymeTagger consistently outperforms human agreement, while LLMs lacking phonetic representation significantly struggle with the task.
Metronome: tracing variation in poetic meters via local sequence alignment
Apr 26, 2024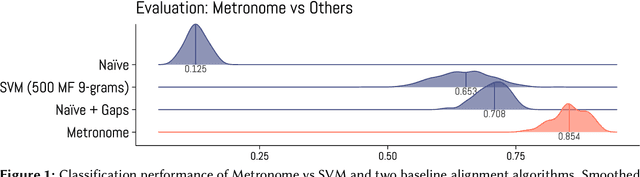
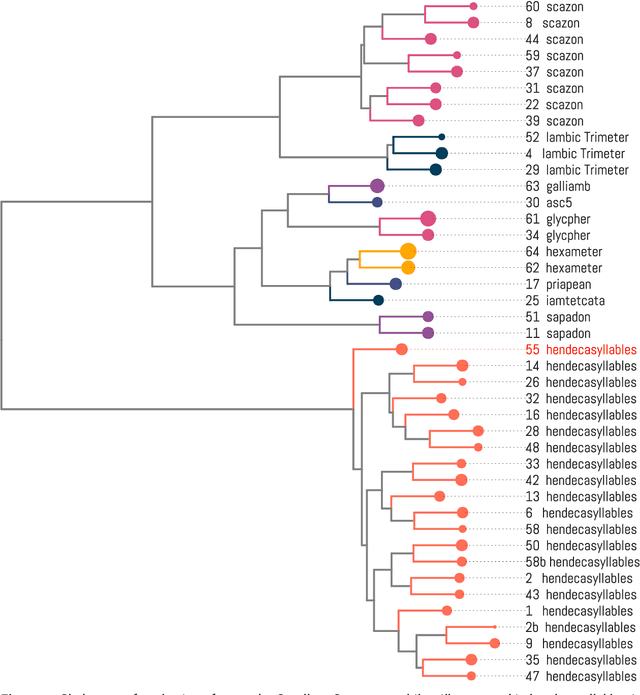

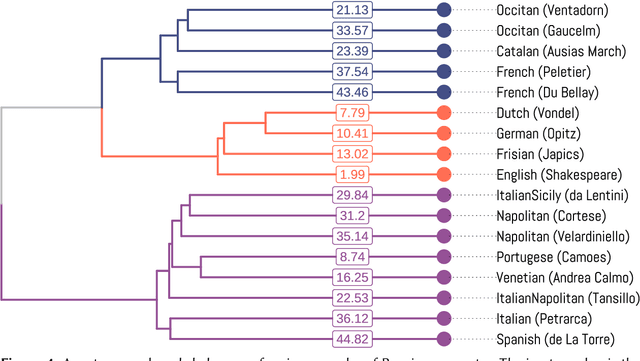
All poetic forms come from somewhere. Prosodic templates can be copied for generations, altered by individuals, imported from foreign traditions, or fundamentally changed under the pressures of language evolution. Yet these relationships are notoriously difficult to trace across languages and times. This paper introduces an unsupervised method for detecting structural similarities in poems using local sequence alignment. The method relies on encoding poetic texts as strings of prosodic features using a four-letter alphabet; these sequences are then aligned to derive a distance measure based on weighted symbol (mis)matches. Local alignment allows poems to be clustered according to emergent properties of their underlying prosodic patterns. We evaluate method performance on a meter recognition tasks against strong baselines and show its potential for cross-lingual and historical research using three short case studies: 1) mutations in quantitative meter in classical Latin, 2) European diffusion of the Renaissance hendecasyllable, and 3) comparative alignment of modern meters in 18--19th century Czech, German and Russian. We release an implementation of the algorithm as a Python package with an open license.
Computational thematics: Comparing algorithms for clustering the genres of literary fiction
May 18, 2023What are the best methods of capturing thematic similarity between literary texts? Knowing the answer to this question would be useful for automatic clustering of book genres, or any other thematic grouping. This paper compares a variety of algorithms for unsupervised learning of thematic similarities between texts, which we call "computational thematics". These algorithms belong to three steps of analysis: text preprocessing, extraction of text features, and measuring distances between the lists of features. Each of these steps includes a variety of options. We test all the possible combinations of these options: every combination of algorithms is given a task to cluster a corpus of books belonging to four pre-tagged genres of fiction. This clustering is then validated against the "ground truth" genre labels. Such comparison of algorithms allows us to learn the best and the worst combinations for computational thematic analysis. To illustrate the sharp difference between the best and the worst methods, we then cluster 5000 random novels from the HathiTrust corpus of fiction.
Scalable handwritten text recognition system for lexicographic sources of under-resourced languages and alphabets
Mar 28, 2023The paper discusses an approach to decipher large collections of handwritten index cards of historical dictionaries. Our study provides a working solution that reads the cards, and links their lemmas to a searchable list of dictionary entries, for a large historical dictionary entitled the Dictionary of the 17th- and 18th-century Polish, which comprizes 2.8 million index cards. We apply a tailored handwritten text recognition (HTR) solution that involves (1) an optimized detection model; (2) a recognition model to decipher the handwritten content, designed as a spatial transformer network (STN) followed by convolutional neural network (RCNN) with a connectionist temporal classification layer (CTC), trained using a synthetic set of 500,000 generated Polish words of different length; (3) a post-processing step using constrained Word Beam Search (WBC): the predictions were matched against a list of dictionary entries known in advance. Our model achieved the accuracy of 0.881 on the word level, which outperforms the base RCNN model. Within this study we produced a set of 20,000 manually annotated index cards that can be used for future benchmarks and transfer learning HTR applications.
From stage to page: language independent bootstrap measures of distinctiveness in fictional speech
Jan 13, 2023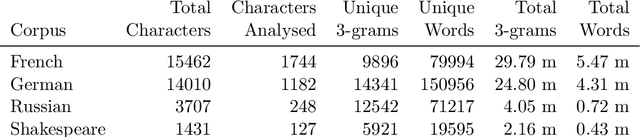
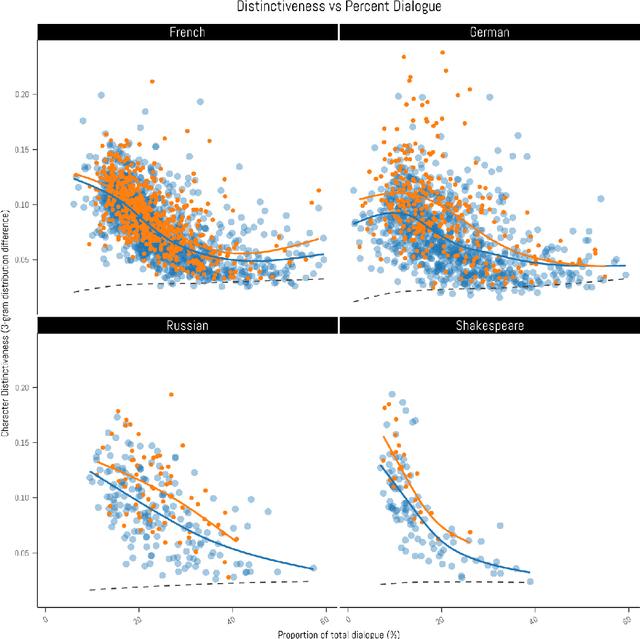
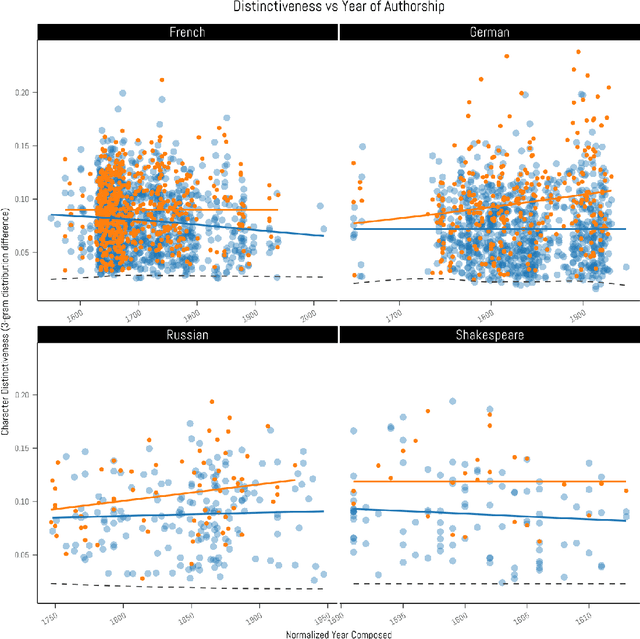
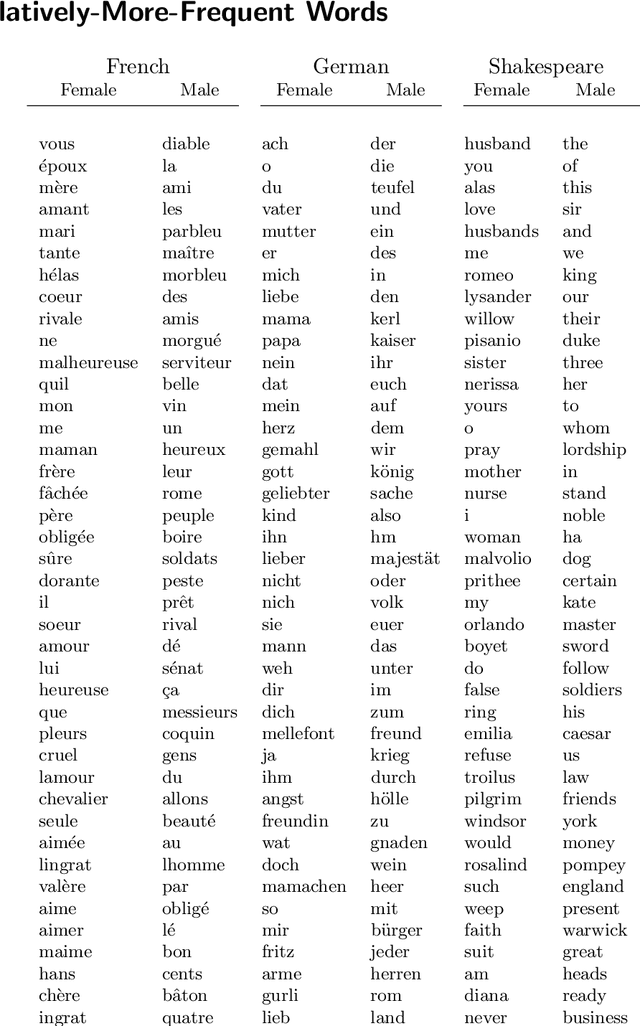
Stylometry is mostly applied to authorial style. Recently, researchers have begun investigating the style of characters, finding that the variation remains within authorial bounds. We address the stylistic distinctiveness of characters in drama. Our primary contribution is methodological; we introduce and evaluate two non-parametric methods to produce a summary statistic for character distinctiveness that can be usefully applied and compared across languages and times. Our first method is based on bootstrap distances between 3-gram probability distributions, the second (reminiscent of 'unmasking' techniques) on word keyness curves. Both methods are validated and explored by applying them to a reasonably large corpus (a subset of DraCor): we analyse 3301 characters drawn from 2324 works, covering five centuries and four languages (French, German, Russian, and the works of Shakespeare). Both methods appear useful; the 3-gram method is statistically more powerful but the word keyness method offers rich interpretability. Both methods are able to capture phonological differences such as accent or dialect, as well as broad differences in topic and lexical richness. Based on exploratory analysis, we find that smaller characters tend to be more distinctive, and that women are cross-linguistically more distinctive than men, with this latter finding carefully interrogated using multiple regression. This greater distinctiveness stems from a historical tendency for female characters to be restricted to an 'internal narrative domain' covering mainly direct discourse and family/romantic themes. It is hoped that direct, comparable statistical measures will form a basis for more sophisticated future studies, and advances in theory.
Semantics of European poetry is shaped by conservative forces: The relationship between poetic meter and meaning in accentual-syllabic verse
Sep 15, 2021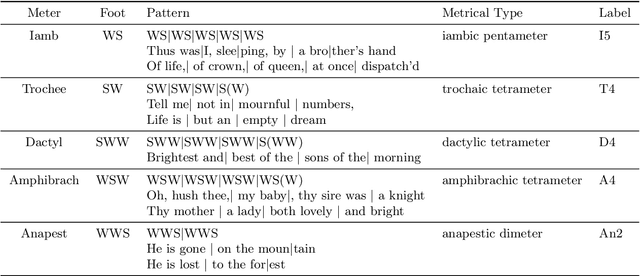
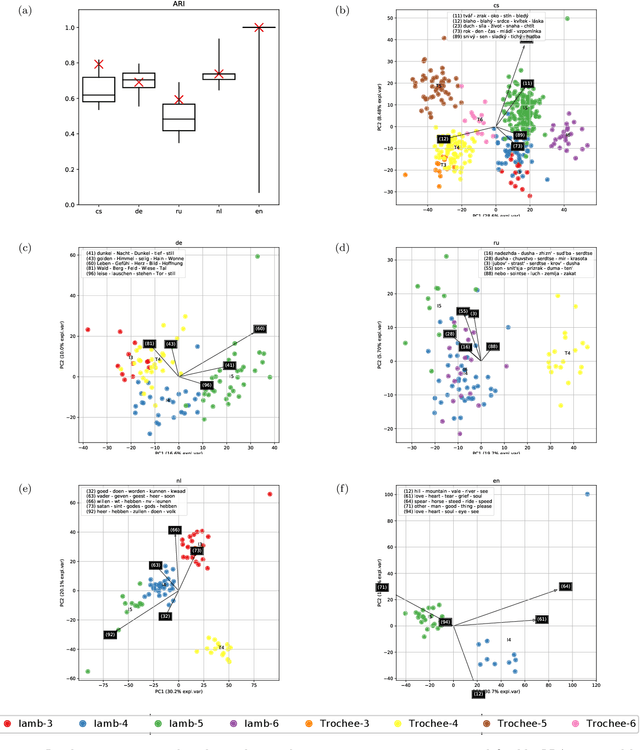
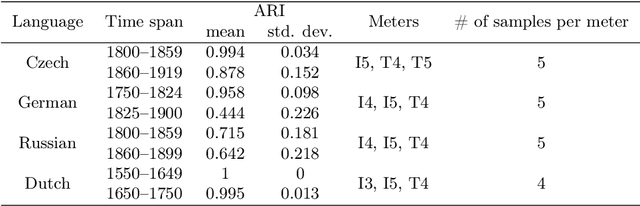
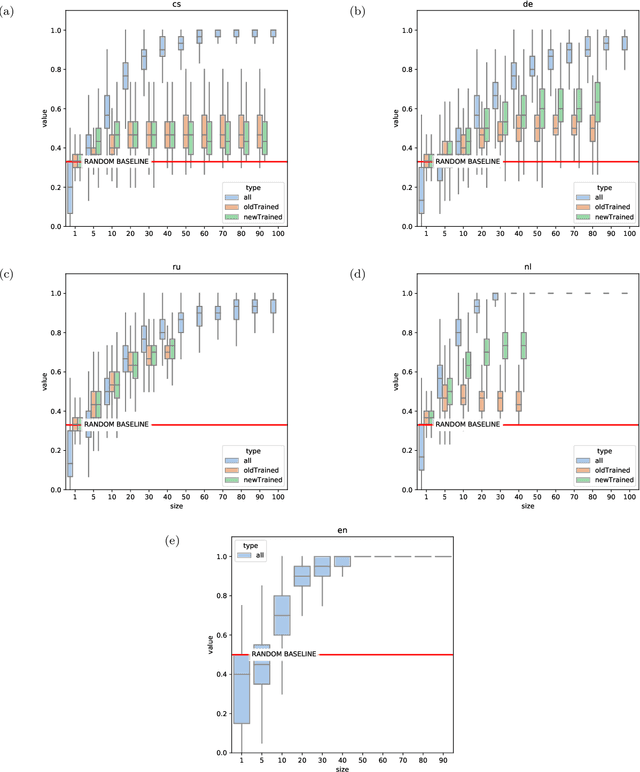
Recent advances in cultural analytics and large-scale computational studies of art, literature and film often show that long-term change in the features of artistic works happens gradually. These findings suggest that conservative forces that shape creative domains might be underestimated. To this end, we provide the first large-scale formal evidence of the persistent association between poetic meter and semantics in 18-19th European literatures, using Czech, German and Russian collections with additional data from English poetry and early modern Dutch songs. Our study traces this association through a series of clustering experiments using the abstracted semantic features of 150,000 poems. With the aid of topic modeling we infer semantic features for individual poems. Texts were also lexically simplified across collections to increase generalizability and decrease the sparseness of word frequency distributions. Topics alone enable recognition of the meters in each observed language, as may be seen from highly robust clustering of same-meter samples (median Adjusted Rand Index between 0.48 and 1). In addition, this study shows that the strength of the association between form and meaning tends to decrease over time. This may reflect a shift in aesthetic conventions between the 18th and 19th centuries as individual innovation was increasingly favored in literature. Despite this decline, it remains possible to recognize semantics of the meters from past or future, which suggests the continuity of semantic traditions while also revealing the historical variability of conditions across languages. This paper argues that distinct metrical forms, which are often copied in a language over centuries, also maintain long-term semantic inertia in poetry. Our findings, thus, highlight the role of the formal features of cultural items in influencing the pace and shape of cultural evolution.