 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data Size Sensitivity in Unsupervised Rhyme Recognition
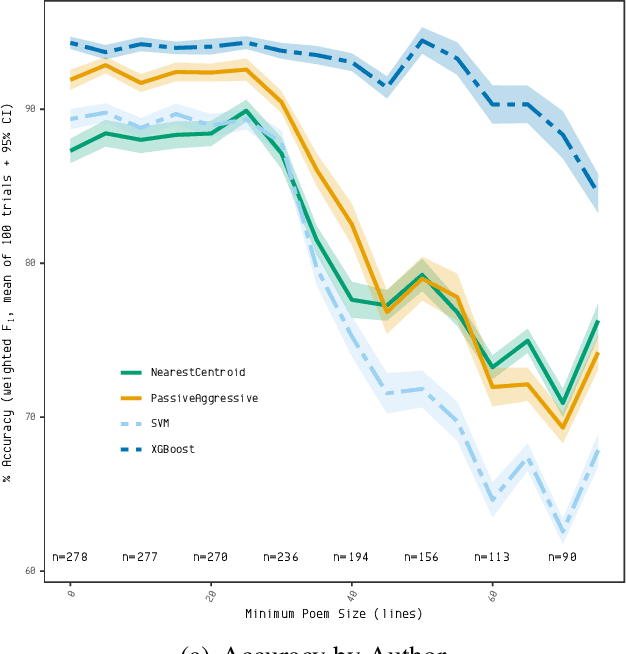
Apr 09, 2026Rhyme is deceptively intuitive: what is or is not a rhyme is constructed historically, scholars struggle with rhyme classification, and people disagree on whether two words are rhymed or not. This complicates automated rhymed recognition and evaluation, especially in multilingual context. This article investigates how much training data is needed for reliable unsupervised rhyme recognition using RhymeTagger, a language-independent tool that identifies rhymes based on repeating patterns in poetry corpora. We evaluate its performance across seven languages (Czech, German, English, French, Italian, Russian, and Slovene), examining how training size and language differences affect accuracy. To set a realistic performance benchmark, we assess inter-annotator agreement on a manually annotated subset of poems and analyze factors contributing to disagreement in expert annotations: phonetic similarity between rhyming words and their distance from each other in a poem. We also compare RhymeTagger to three large language models using a one-shot learning strategy. Our findings show that, once provided with sufficient training data, RhymeTagger consistently outperforms human agreement, while LLMs lacking phonetic representation significantly struggle with the task.
Metronome: tracing variation in poetic meters via local sequence alignment
Apr 26, 2024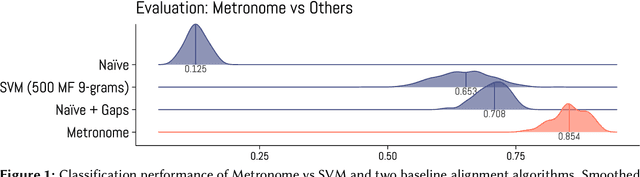
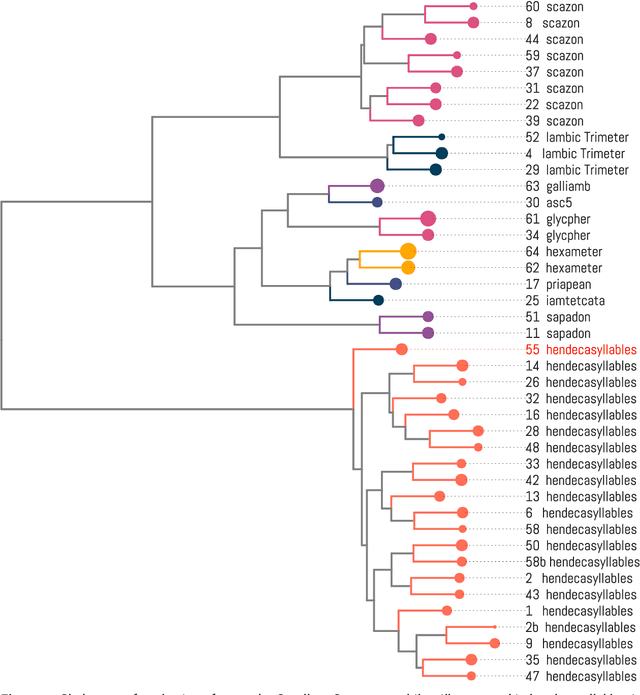

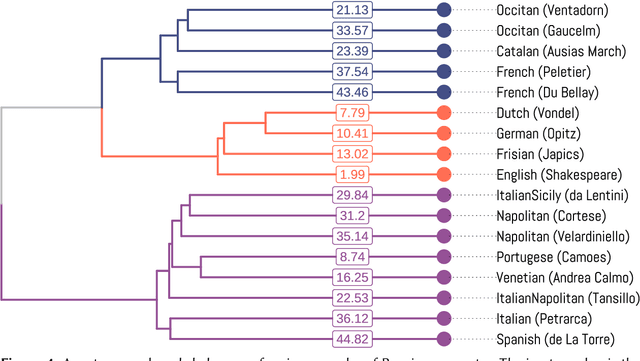
All poetic forms come from somewhere. Prosodic templates can be copied for generations, altered by individuals, imported from foreign traditions, or fundamentally changed under the pressures of language evolution. Yet these relationships are notoriously difficult to trace across languages and times. This paper introduces an unsupervised method for detecting structural similarities in poems using local sequence alignment. The method relies on encoding poetic texts as strings of prosodic features using a four-letter alphabet; these sequences are then aligned to derive a distance measure based on weighted symbol (mis)matches. Local alignment allows poems to be clustered according to emergent properties of their underlying prosodic patterns. We evaluate method performance on a meter recognition tasks against strong baselines and show its potential for cross-lingual and historical research using three short case studies: 1) mutations in quantitative meter in classical Latin, 2) European diffusion of the Renaissance hendecasyllable, and 3) comparative alignment of modern meters in 18--19th century Czech, German and Russian. We release an implementation of the algorithm as a Python package with an open license.
(Not) Understanding Latin Poetic Style with Deep Learning
Apr 09, 2024This article summarizes some mostly unsuccessful attempts to understand authorial style by examining the attention of various neural networks (LSTMs and CNNs) trained on a corpus of classical Latin verse that has been encoded to include sonic and metrical features. Carefully configured neural networks are shown to be extremely strong authorship classifiers, so it is hoped that they might therefore teach `traditional' readers something about how the authors differ in style. Sadly their reasoning is, so far, inscrutable. While the overall goal has not yet been reached, this work reports some useful findings in terms of effective ways to encode and embed verse, the relative strengths and weaknesses of the neural network families, and useful (and not so useful) techniques for designing and inspecting NN models in this domain. This article suggests that, for poetry, CNNs are better choices than LSTMs -- they train more quickly, have equivalent accuracy, and (potentially) offer better interpretability. Based on a great deal of experimentation, it also suggests that simple, trainable embeddings are more effective than domain-specific schemes, and stresses the importance of techniques to reduce overfitting, like dropout and batch normalization.
From stage to page: language independent bootstrap measures of distinctiveness in fictional speech
Jan 13, 2023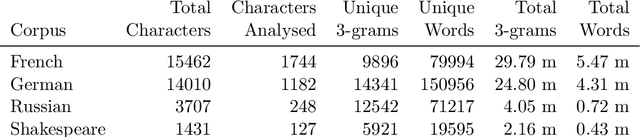
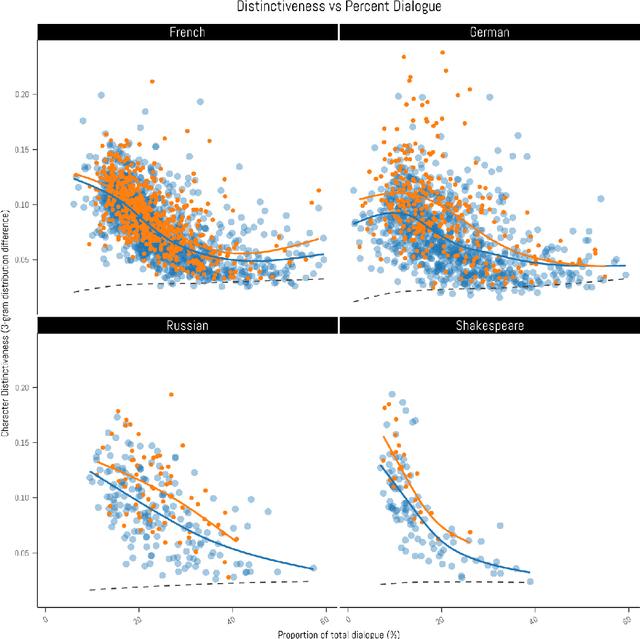
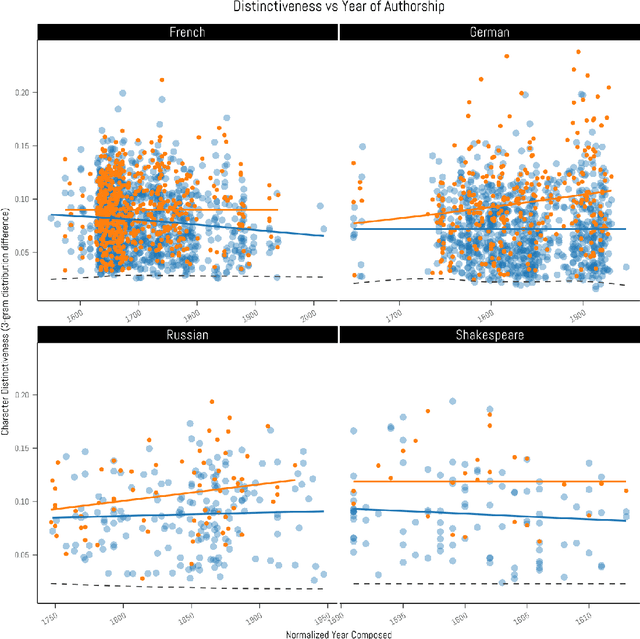
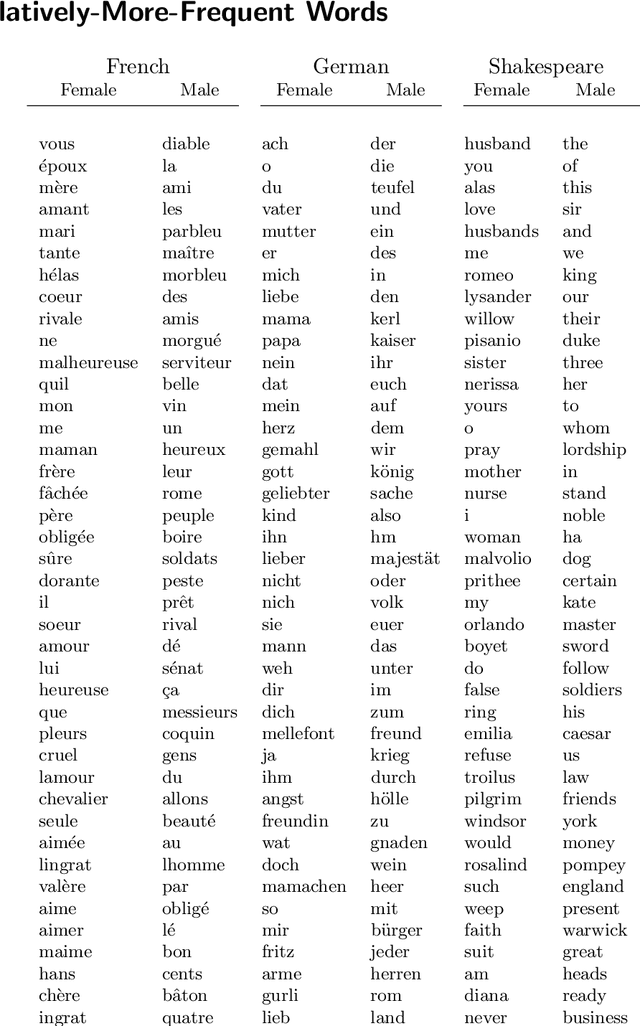
Stylometry is mostly applied to authorial style. Recently, researchers have begun investigating the style of characters, finding that the variation remains within authorial bounds. We address the stylistic distinctiveness of characters in drama. Our primary contribution is methodological; we introduce and evaluate two non-parametric methods to produce a summary statistic for character distinctiveness that can be usefully applied and compared across languages and times. Our first method is based on bootstrap distances between 3-gram probability distributions, the second (reminiscent of 'unmasking' techniques) on word keyness curves. Both methods are validated and explored by applying them to a reasonably large corpus (a subset of DraCor): we analyse 3301 characters drawn from 2324 works, covering five centuries and four languages (French, German, Russian, and the works of Shakespeare). Both methods appear useful; the 3-gram method is statistically more powerful but the word keyness method offers rich interpretability. Both methods are able to capture phonological differences such as accent or dialect, as well as broad differences in topic and lexical richness. Based on exploratory analysis, we find that smaller characters tend to be more distinctive, and that women are cross-linguistically more distinctive than men, with this latter finding carefully interrogated using multiple regression. This greater distinctiveness stems from a historical tendency for female characters to be restricted to an 'internal narrative domain' covering mainly direct discourse and family/romantic themes. It is hoped that direct, comparable statistical measures will form a basis for more sophisticated future studies, and advances in theory.
Some Stylometric Remarks on Ovid's Heroides and the Epistula Sapphus
Feb 24, 2022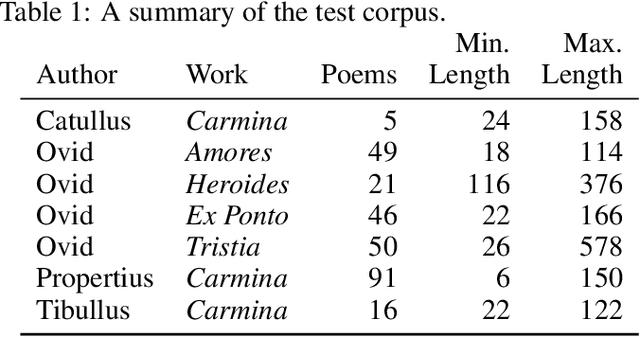


This article aims to contribute to two well-worn areas of debate in classical Latin philology, relating to Ovid's Heroides. The first is the question of the authenticity (and, to a lesser extent the correct position) of the letter placed fifteenth by almost every editor -- the so-called Epistula Sapphus (henceforth ES). The secondary question, although perhaps now less fervently debated, is the authenticity of the 'Double Heroides', placed by those who accept them as letters 16-21. I employ a variety of methods drawn from the domain of computational stylometry to consider the poetics and the lexico-grammatical features of these elegiac poems in the broader context of a corpus of 'shorter' (from 20 to 546 lines) elegiac works from five authors (266 poems in all) comprising more or less all of the non-fragmentary classical corpus. Based on a variety of techniques, every measure gives clear indication that the poetic style of the Heroides is Ovidian, but distinctive; they can be accurately isolated from Ovid more broadly. The Single and Double Heroides split into two clear groups, with the ES grouped consistently with the single letters. Furthermore, by comparing the style of the letters with the 'early' (although there are complications in this label) works of the Amores and the late works of the Ex Ponto, the evidence supports sequential composition -- meaning that the ES is correctly placed -- and, further, supports the growing consensus that the double letters were composed significantly later, in exile.