 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhispering in Norwegian: Navigating Orthographic and Dialectic Challenges
Feb 02, 2024



This article introduces NB-Whisper, an adaptation of OpenAI's Whisper, specifically fine-tuned for Norwegian language Automatic Speech Recognition (ASR). We highlight its key contributions and summarise the results achieved in converting spoken Norwegian into written forms and translating other languages into Norwegian. We show that we are able to improve the Norwegian Bokm{\aa}l transcription by OpenAI Whisper Large-v3 from a WER of 10.4 to 6.6 on the Fleurs Dataset and from 6.8 to 2.2 on the NST dataset.
The Norwegian Parliamentary Speech Corpus
Jan 26, 2022
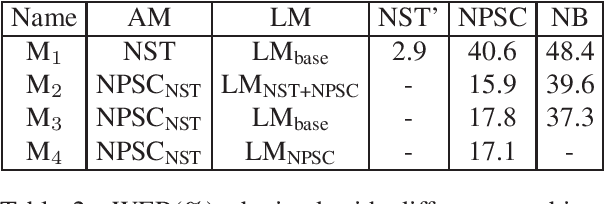
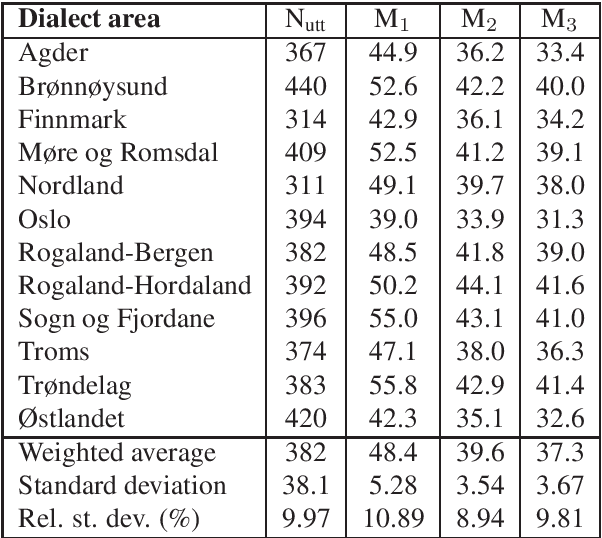
The Norwegian Parliamentary Speech Corpus (NPSC) is a speech dataset with recordings of meetings from Stortinget, the Norwegian parliament. It is the first, publicly available dataset containing unscripted, Norwegian speech designed for training of automatic speech recognition (ASR) systems. The recordings are manually transcribed and annotated with language codes and speakers, and there are detailed metadata about the speakers. The transcriptions exist in both normalized and non-normalized form, and non-standardized words are explicitly marked and annotated with standardized equivalents. To test the usefulness of this dataset, we have compared an ASR system trained on the NPSC with a baseline system trained on only manuscript-read speech. These systems were tested on an independent dataset containing spontaneous, dialectal speech. The NPSC-trained system performed significantly better, with a 22.9% relative improvement in word error rate (WER). Moreover, training on the NPSC is shown to have a "democratizing" effect in terms of dialects, as improvements are generally larger for dialects with higher WER from the baseline system.