Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Word Usage Graphs with Cluster Definitions
Paper and Code
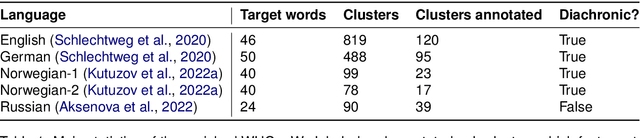
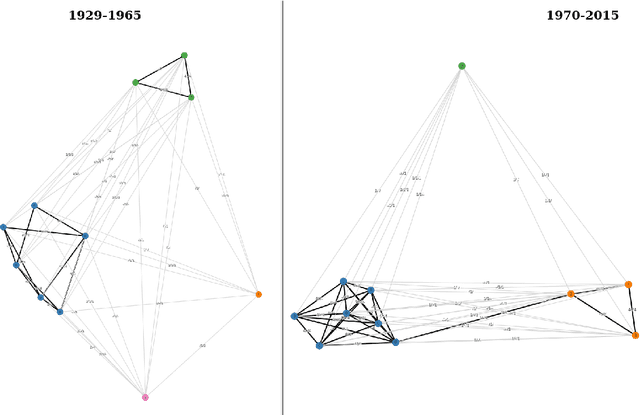


We present a dataset of word usage graphs (WUGs), where the existing WUGs for multiple languages are enriched with cluster labels functioning as sense definitions. They are generated from scratch by fine-tuned encoder-decoder language models. The conducted human evaluation has shown that these definitions match the existing clusters in WUGs better than the definitions chosen from WordNet by two baseline systems. At the same time, the method is straightforward to use and easy to extend to new languages. The resulting enriched datasets can be extremely helpful for moving on to explainable semantic change modeling.
* LREC-COLING 2024
View paper on