 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcessing M.A. Castrén's Materials: Multilingual Typed and Handwritten Manuscripts
Paper and Code
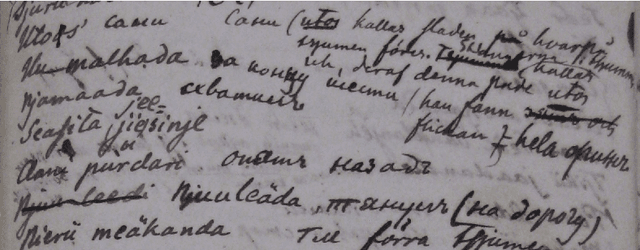
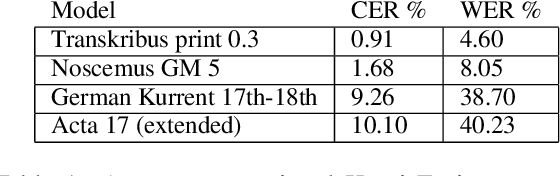
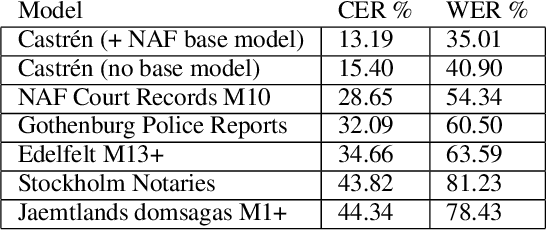
The study forms a technical report of various tasks that have been performed on the materials collected and published by Finnish ethnographer and linguist, Matthias Alexander Castr\'en (1813-1852). The Finno-Ugrian Society is publishing Castr\'en's manuscripts as new critical and digital editions, and at the same time different research groups have also paid attention to these materials. We discuss the workflows and technical infrastructure used, and consider how datasets that benefit different computational tasks could be created to further improve the usability of these materials, and also to aid the further processing of similar archived collections. We specifically focus on the parts of the collections that are processed in a way that improves their usability in more technical applications, complementing the earlier work on the cultural and linguistic aspects of these materials. Most of these datasets are openly available in Zenodo. The study points to specific areas where further research is needed, and provides benchmarks for text recognition tasks.