 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARETE: an R package for Automated REtrieval from TExt with large language models
Nov 06, 20251. A hard stop for the implementation of rigorous conservation initiatives is our lack of key species data, especially occurrence data. Furthermore, researchers have to contend with an accelerated speed at which new information must be collected and processed due to anthropogenic activity. Publications ranging from scientific papers to gray literature contain this crucial information but their data are often not machine-readable, requiring extensive human work to be retrieved. 2. We present the ARETE R package, an open-source software aiming to automate data extraction of species occurrences powered by large language models, namely using the chatGPT Application Programming Interface. This R package integrates all steps of the data extraction and validation process, from Optical Character Recognition to detection of outliers and output in tabular format. Furthermore, we validate ARETE through systematic comparison between what is modelled and the work of human annotators. 3. We demonstrate the usefulness of the approach by comparing range maps produced using GBIF data and with those automatically extracted for 100 species of spiders. Newly extracted data allowed to expand the known Extent of Occurrence by a mean three orders of magnitude, revealing new areas where the species were found in the past, which mayhave important implications for spatial conservation planning and extinction risk assessments. 4. ARETE allows faster access to hitherto untapped occurrence data, a potential game changer in projects requiring such data. Researchers will be able to better prioritize resources, manually verifying selected species while maintaining automated extraction for the majority. This workflow also allows predicting available bibliographic data during project planning.
Multilingual and Multimodal Topic Modelling with Pretrained Embeddings
Nov 15, 2022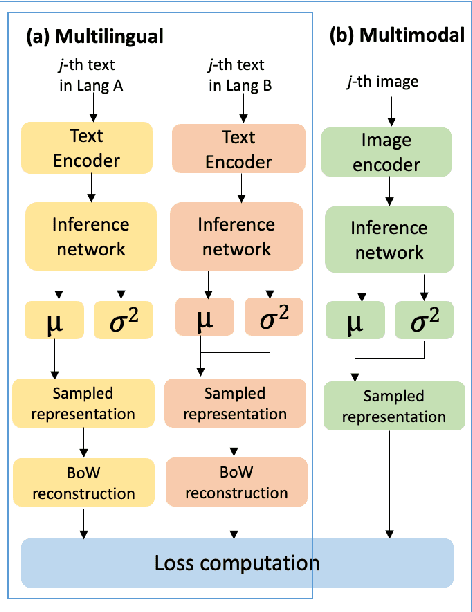
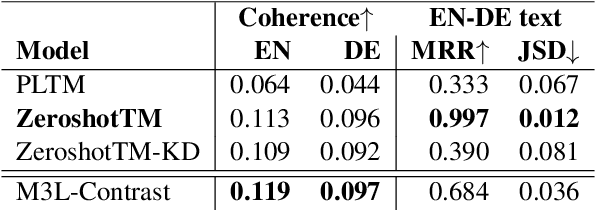
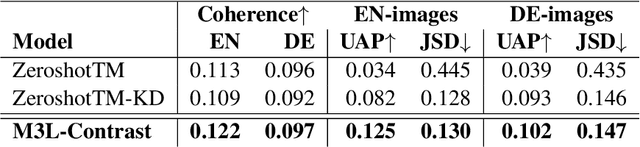
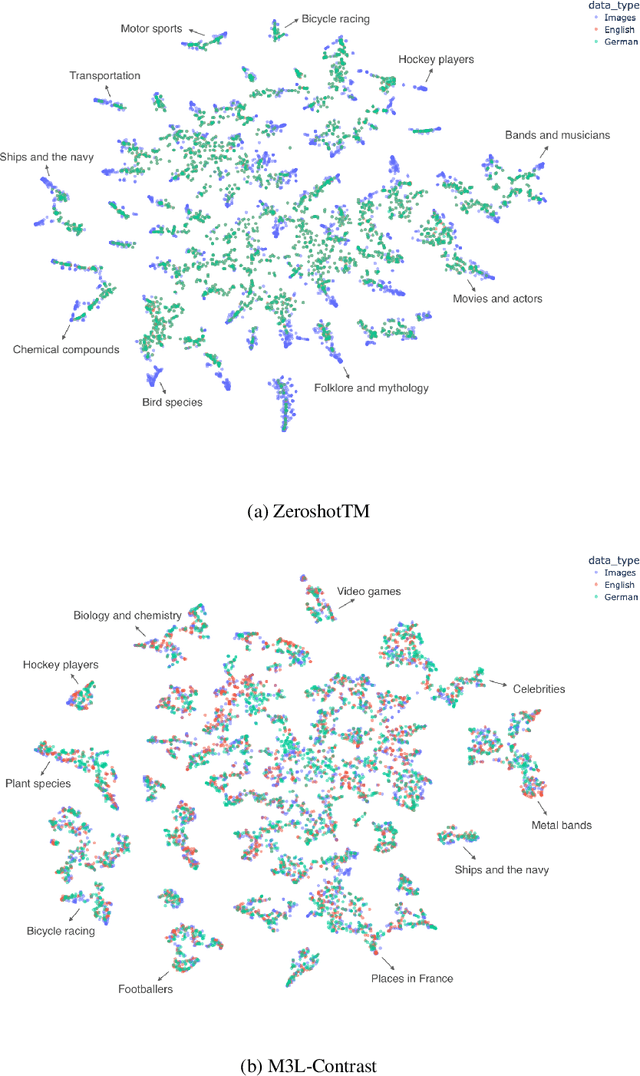
This paper presents M3L-Contrast -- a novel multimodal multilingual (M3L) neural topic model for comparable data that maps texts from multiple languages and images into a shared topic space. Our model is trained jointly on texts and images and takes advantage of pretrained document and image embeddings to abstract the complexities between different languages and modalities. As a multilingual topic model, it produces aligned language-specific topics and as multimodal model, it infers textual representations of semantic concepts in images. We demonstrate that our model is competitive with a zero-shot topic model in predicting topic distributions for comparable multilingual data and significantly outperforms a zero-shot model in predicting topic distributions for comparable texts and images. We also show that our model performs almost as well on unaligned embeddings as it does on aligned embeddings.
Do Not Fire the Linguist: Grammatical Profiles Help Language Models Detect Semantic Change
Apr 12, 2022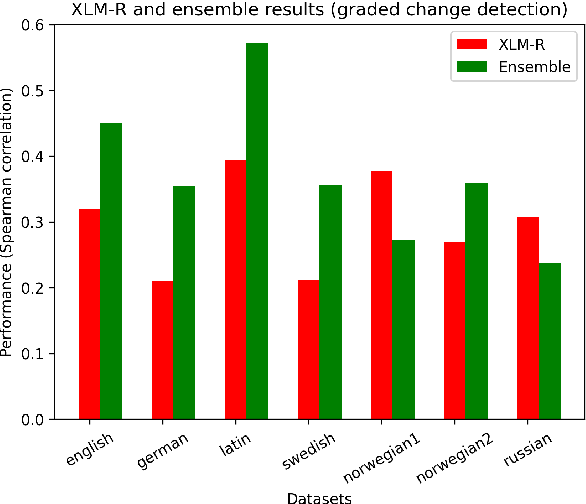

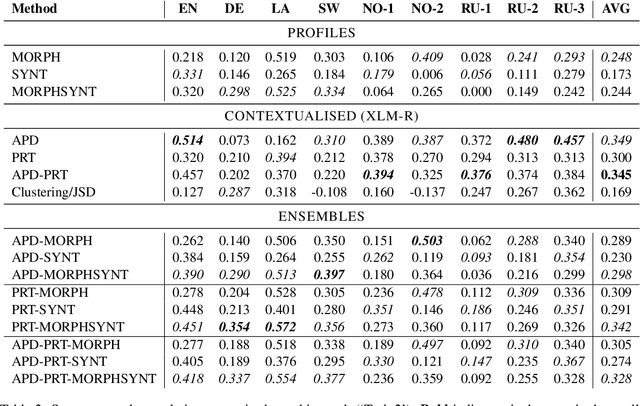
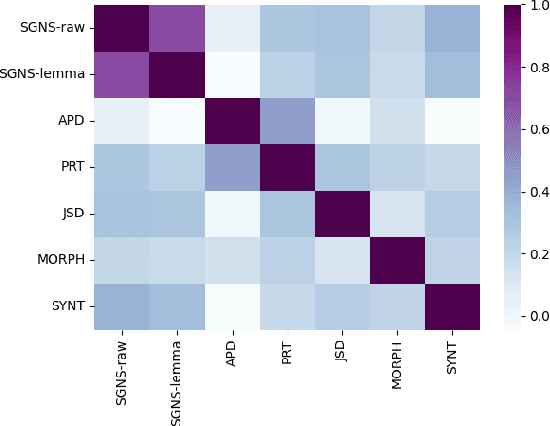
Morphological and syntactic changes in word usage (as captured, e.g., by grammatical profiles) have been shown to be good predictors of a word's meaning change. In this work, we explore whether large pre-trained contextualised language models, a common tool for lexical semantic change detection, are sensitive to such morphosyntactic changes. To this end, we first compare the performance of grammatical profiles against that of a multilingual neural language model (XLM-R) on 10 datasets, covering 7 languages, and then combine the two approaches in ensembles to assess their complementarity. Our results show that ensembling grammatical profiles with XLM-R improves semantic change detection performance for most datasets and languages. This indicates that language models do not fully cover the fine-grained morphological and syntactic signals that are explicitly represented in grammatical profiles. An interesting exception are the test sets where the time spans under analysis are much longer than the time gap between them (for example, century-long spans with a one-year gap between them). Morphosyntactic change is slow so grammatical profiles do not detect in such cases. In contrast, language models, thanks to their access to lexical information, are able to detect fast topical changes.
Grammatical Profiling for Semantic Change Detection
Sep 21, 2021
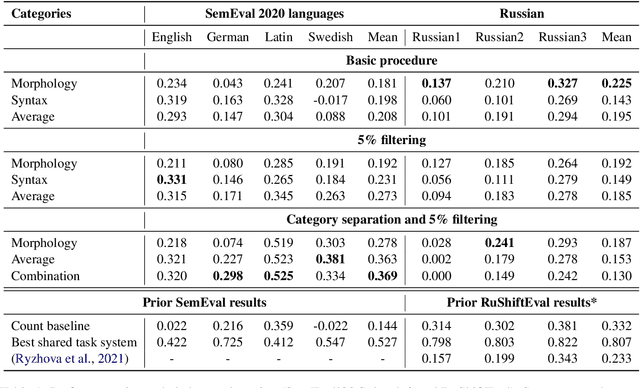
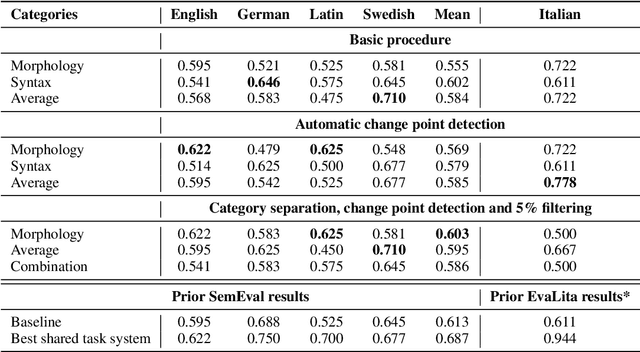
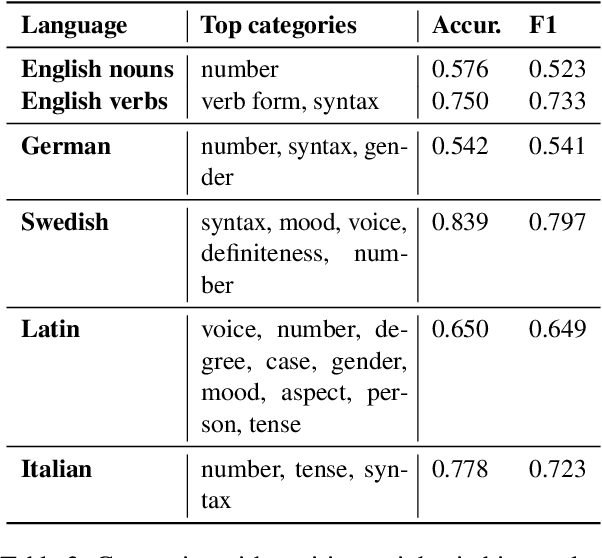
Semantics, morphology and syntax are strongly interdependent. However, the majority of computational methods for semantic change detection use distributional word representations which encode mostly semantics. We investigate an alternative method, grammatical profiling, based entirely on changes in the morphosyntactic behaviour of words. We demonstrate that it can be used for semantic change detection and even outperforms some distributional semantic methods. We present an in-depth qualitative and quantitative analysis of the predictions made by our grammatical profiling system, showing that they are plausible and interpretable.
Three-part diachronic semantic change dataset for Russian
Jun 15, 2021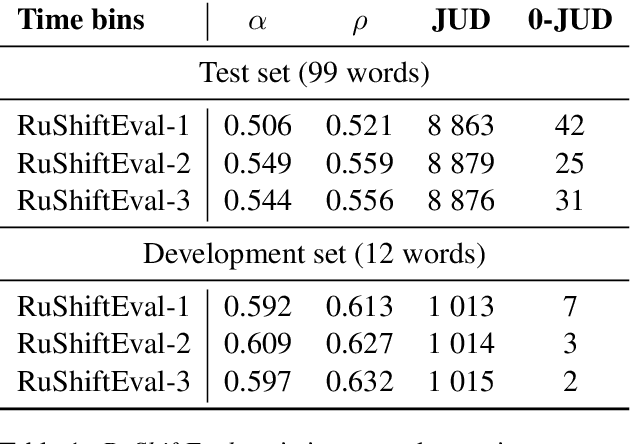
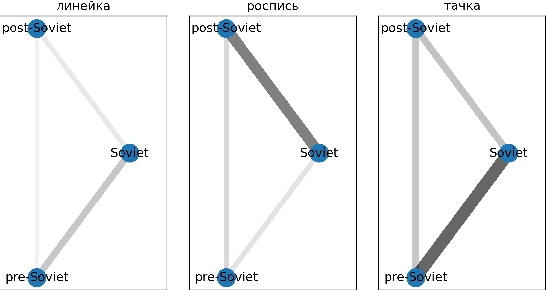

We present a manually annotated lexical semantic change dataset for Russian: RuShiftEval. Its novelty is ensured by a single set of target words annotated for their diachronic semantic shifts across three time periods, while the previous work either used only two time periods, or different sets of target words. The paper describes the composition and annotation procedure for the dataset. In addition, it is shown how the ternary nature of RuShiftEval allows to trace specific diachronic trajectories: `changed at a particular time period and stable afterwards' or `was changing throughout all time periods'. Based on the analysis of the submissions to the recent shared task on semantic change detection for Russian, we argue that correctly identifying such trajectories can be an interesting sub-task itself.
Topic modelling discourse dynamics in historical newspapers
Nov 20, 2020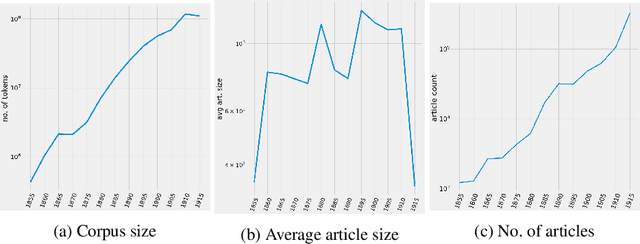
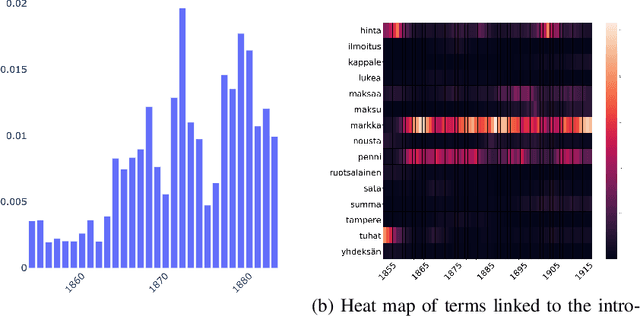
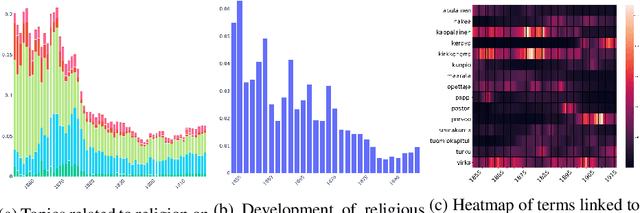
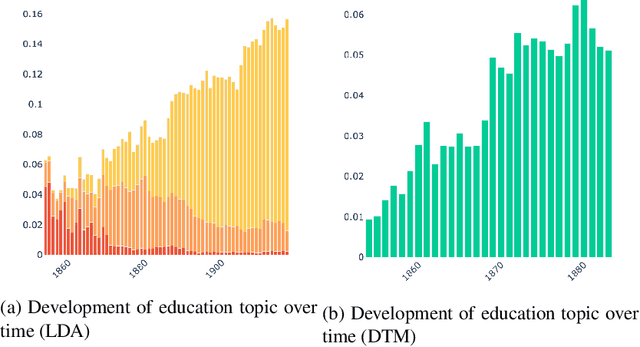
This paper addresses methodological issues in diachronic data analysis for historical research. We apply two families of topic models (LDA and DTM) on a relatively large set of historical newspapers, with the aim of capturing and understanding discourse dynamics. Our case study focuses on newspapers and periodicals published in Finland between 1854 and 1917, but our method can easily be transposed to any diachronic data. Our main contributions are a) a combined sampling, training and inference procedure for applying topic models to huge and imbalanced diachronic text collections; b) a discussion on the differences between two topic models for this type of data; c) quantifying topic prominence for a period and thus a generalization of document-wise topic assignment to a discourse level; and d) a discussion of the role of humanistic interpretation with regard to analysing discourse dynamics through topic models.
Capturing Evolution in Word Usage: Just Add More Clusters?
Jan 24, 2020
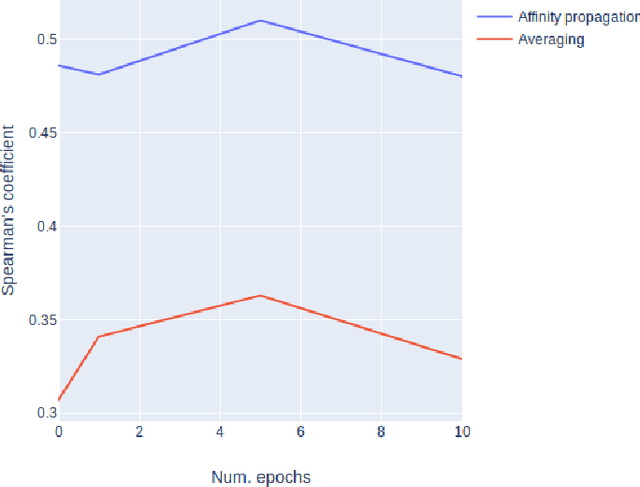
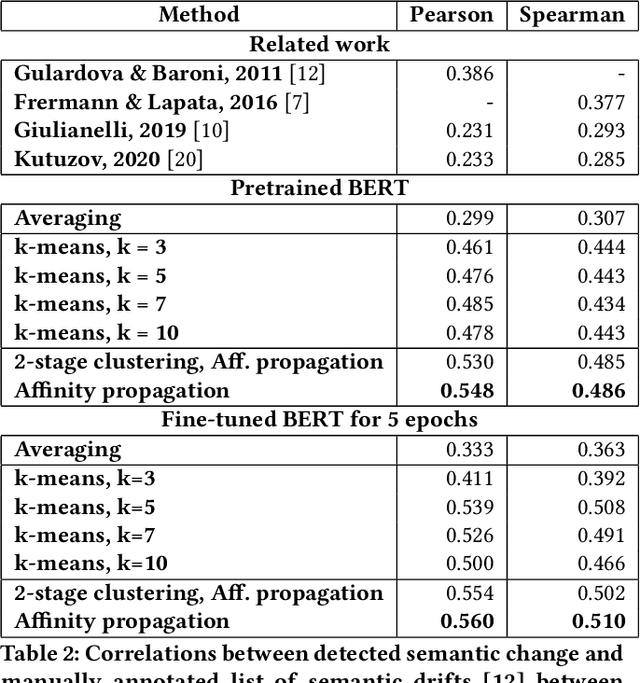

The way the words are used evolves through time, mirroring cultural or technological evolution of society. Semantic change detection is the task of detecting and analysing word evolution in textual data, even in short periods of time. In this paper we focus on a new set of methods relying on contextualised embeddings, a type of semantic modelling that revolutionised the NLP field recently. We leverage the ability of the transformer-based BERT model to generate contextualised embeddings capable of detecting semantic change of words across time. Several approaches are compared in a common setting in order to establish strengths and weaknesses for each of them. We also propose several ideas for improvements, managing to drastically improve the performance of existing approaches.