 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Multimodal Topic Modelling with Pretrained Embeddings
Paper and Code
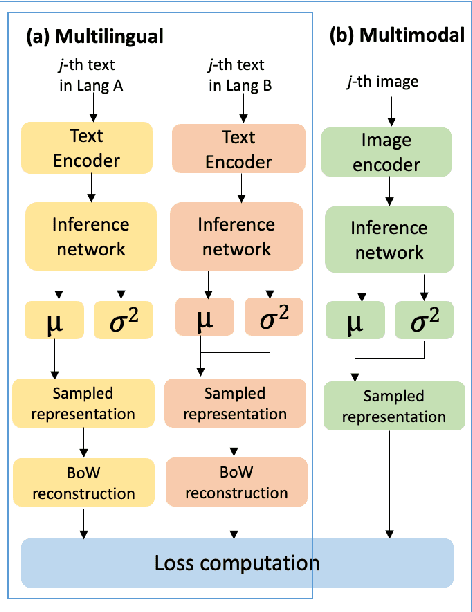
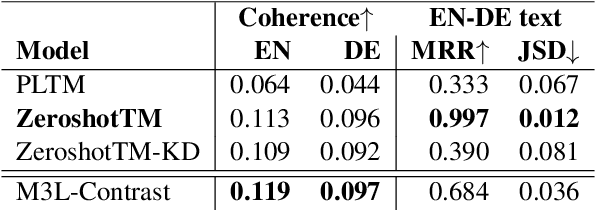
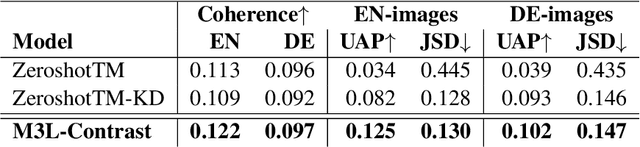
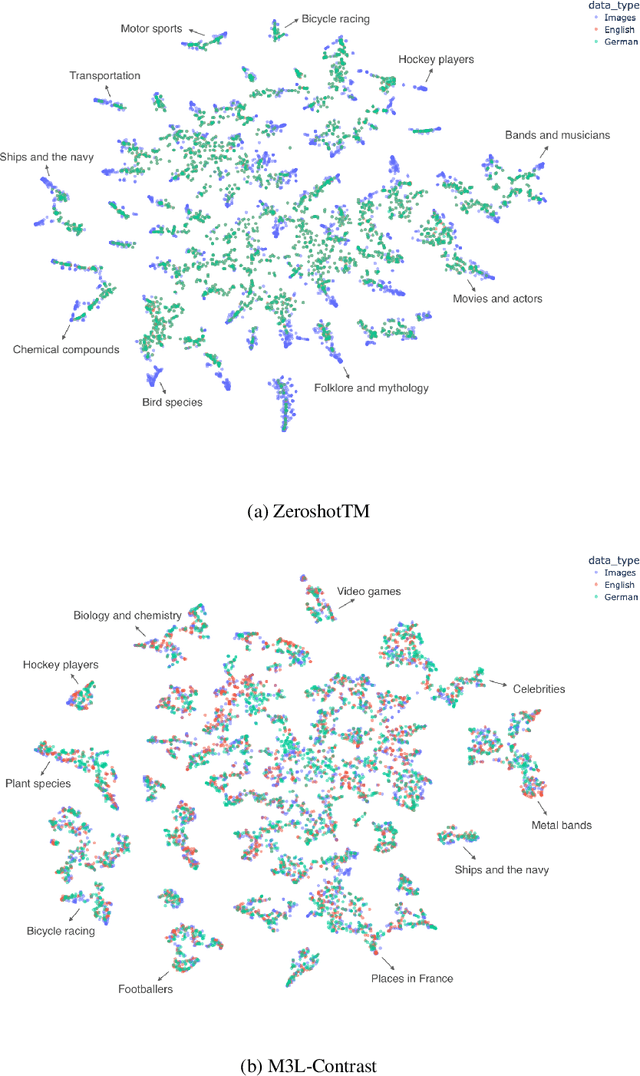
This paper presents M3L-Contrast -- a novel multimodal multilingual (M3L) neural topic model for comparable data that maps texts from multiple languages and images into a shared topic space. Our model is trained jointly on texts and images and takes advantage of pretrained document and image embeddings to abstract the complexities between different languages and modalities. As a multilingual topic model, it produces aligned language-specific topics and as multimodal model, it infers textual representations of semantic concepts in images. We demonstrate that our model is competitive with a zero-shot topic model in predicting topic distributions for comparable multilingual data and significantly outperforms a zero-shot model in predicting topic distributions for comparable texts and images. We also show that our model performs almost as well on unaligned embeddings as it does on aligned embeddings.