 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFW2V: An Enhanced Document Similarity Method for the Morphologically Rich Finnish Language
Dec 23, 2021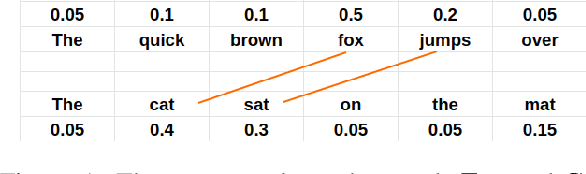
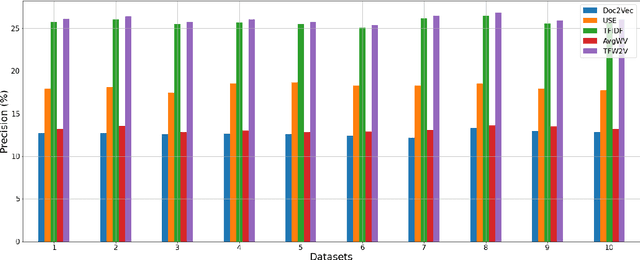
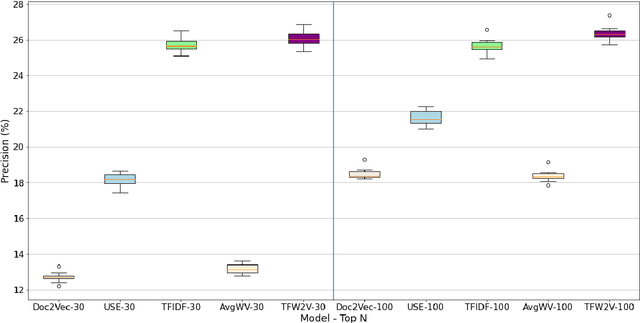
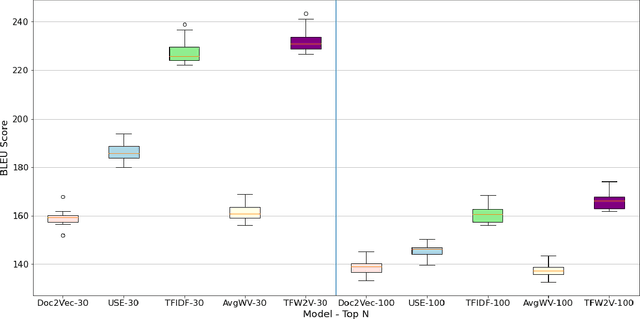
Measuring the semantic similarity of different texts has many important applications in Digital Humanities research such as information retrieval, document clustering and text summarization. The performance of different methods depends on the length of the text, the domain and the language. This study focuses on experimenting with some of the current approaches to Finnish, which is a morphologically rich language. At the same time, we propose a simple method, TFW2V, which shows high efficiency in handling both long text documents and limited amounts of data. Furthermore, we design an objective evaluation method which can be used as a framework for benchmarking text similarity approaches.
Hub and Spoke Logistics Network Design for Urban Region with Clustering-Based Approach
Jul 07, 2021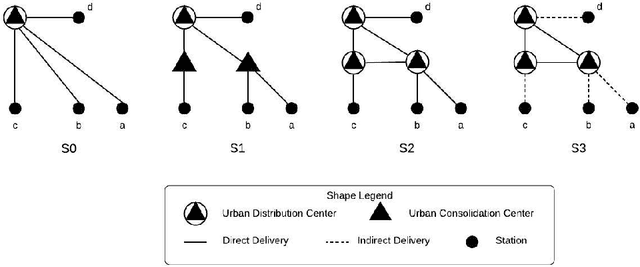

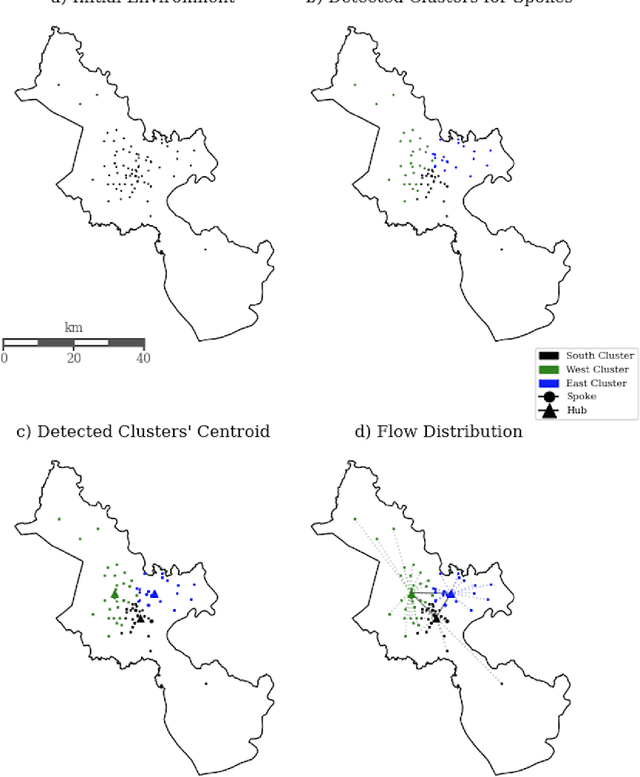
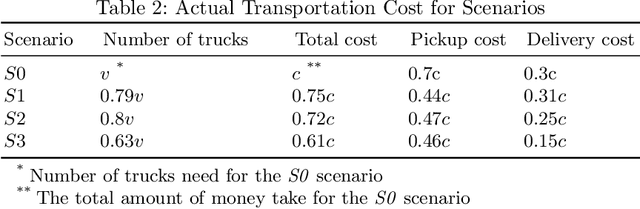
This study aims to propose effective modeling and approach for designing a logistics network in the urban area in order to offer an efficient flow distribution network as a competitive strategy in the logistics industry where demand is sensitive to both price and time. A multi-stage approach is introduced to select the number of hubs and allocate spokes to the hubs for flow distribution and hubs' location detection. Specifically, a fuzzy clustering model with the objective function is to minimize the approximate transportation cost is employed, in the next phase is to focus on balancing the demand capacity among the hubs with the help of domain experts, afterward, the facility location vehicle routing problems within the network is introduced. To demonstrate the approach's advantages, an experiment was performed on the designed network and its actual transportation cost for the real operational data in which specific to the Ho Chi Minh city infrastructure conditions. Additionally, we show the flexibility of the designed network in the flow distribution and its computational experiments to develop the managerial insights which contribute to the network design decision-making process.
A Simplified Framework for Air Route Clustering Based on ADS-B Data
Jul 07, 2021

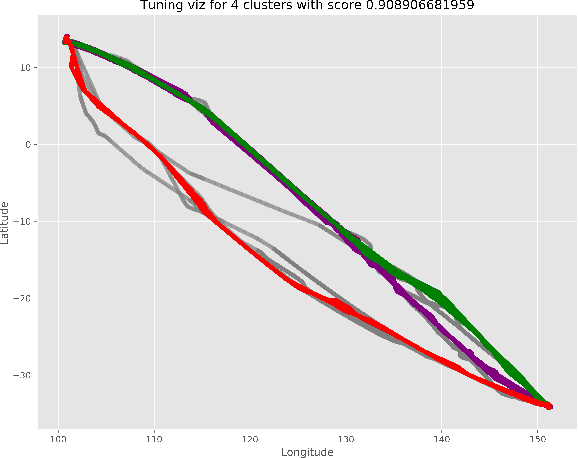
The volume of flight traffic gets increasing over the time, which makes the strategic traffic flow management become one of the challenging problems since it requires a lot of computational resources to model entire traffic data. On the other hand, Automatic Dependent Surveillance - Broadcast (ADS-B) technology has been considered as a promising data technology to provide both flight crews and ground control staff the necessary information safely and efficiently about the position and velocity of the airplanes in a specific area. In the attempt to tackle this problem, we presented in this paper a simplified framework that can support to detect the typical air routes between airports based on ADS-B data. Specifically, the flight traffic will be classified into major groups based on similarity measures, which helps to reduce the number of flight paths between airports. As a matter of fact, our framework can be taken into account to reduce practically the computational cost for air flow optimization and evaluate the operational performance. Finally, in order to illustrate the potential applications of our proposed framework, an experiment was performed using ADS-B traffic flight data of three different pairs of airports. The detected typical routes between each couple of airports show promising results by virtue of combining two indices for measuring the clustering performance and incorporating human judgment into the visual inspection.
An Unsupervised method for OCR Post-Correction and Spelling Normalisation for Finnish
Nov 06, 2020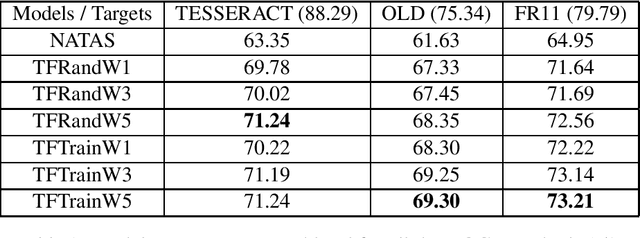
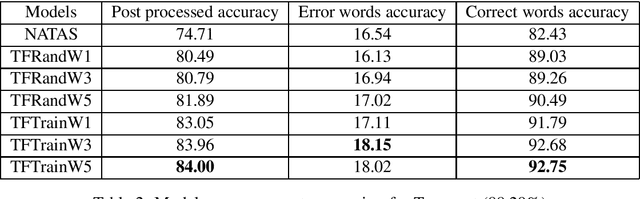


Historical corpora are known to contain errors introduced by OCR (optical character recognition) methods used in the digitization process, often said to be degrading the performance of NLP systems. Correcting these errors manually is a time-consuming process and a great part of the automatic approaches have been relying on rules or supervised machine learning. We build on previous work on fully automatic unsupervised extraction of parallel data to train a character-based sequence-to-sequence NMT (neural machine translation) model to conduct OCR error correction designed for English, and adapt it to Finnish by proposing solutions that take the rich morphology of the language into account. Our new method shows increased performance while remaining fully unsupervised, with the added benefit of spelling normalisation. The source code and models are available on GitHub and Zenodo.