 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I understand your perspective": LLM Persuasion and Sycophancy through the Lens of Communicative Action Theory
Jun 06, 2026Large Language Models (LLMs) can generate high-quality arguments, yet their ability to engage in nuanced and persuasive communicative actions remains largely unexplored. This work explores the persuasive potential of LLMs through the framework of Jürgen Habermas' Theory of Communicative Action. It examines whether LLMs express illocutionary intent (i.e., pragmatic functions of language such as conveying knowledge, building trust, or signaling similarity) in ways that are comparable to human communication. We simulate online discussions between opinion holders and LLMs using conversations from the persuasive subreddit ChangeMyView. We then compare the likelihood of illocutionary intents in human-written and LLM-generated counter-arguments, specifically those that successfully changed the original poster's view. We find that all three LLMs effectively convey illocutionary intent -- often more so than humans -- potentially increasing their anthropomorphism. Further, LLMs craft sycophantic responses that closely align with the opinion holder's intent, a strategy strongly associated with opinion change. Finally, crowd-sourced workers find LLM-generated counter-arguments more agreeable and consistently prefer them over human-written ones. These findings suggest that LLMs' persuasive power extends beyond merely generating high-quality arguments. On the contrary, training LLMs with human preferences effectively tunes them to mirror human communication patterns, particularly nuanced communicative actions, potentially increasing individuals' susceptibility to their influence.
A Systematic Analysis of Linguistic Features in AI-Generated Text Detection Across Domains and Models
Jun 02, 2026Interpretable linguistic features offer a promising approach for explaining why a given text appears machine-generated, particularly for non-expert users. However, existing findings on which features reliably indicate LLM-generated text remain fragmented across feature sets, models, and text domains. To address this gap, we conduct a large-scale empirical study assessing the robustness of linguistic signals for characterizing AI-generated text. Our analysis covers 284 interpretable linguistic features across outputs from 27 LLMs and ten text domains under cross-model and cross-domain generalization settings. We show that classifiers based solely on linguistic features can reliably distinguish AI-generated from human-written text. However, many previously proposed indicators prove strongly context-dependent, with the exception of measures of lexical richness, which remain robust signals across model families and text domains. These results demonstrate which linguistic signals generalize across contexts and provide a foundation for more reliable, interpretable analyses of AI-generated language.
How-to Guides for Specific Audiences: A Corpus and Initial Findings
Sep 21, 2023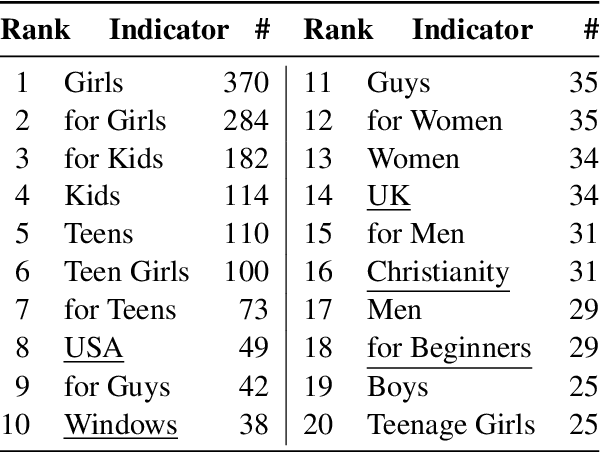
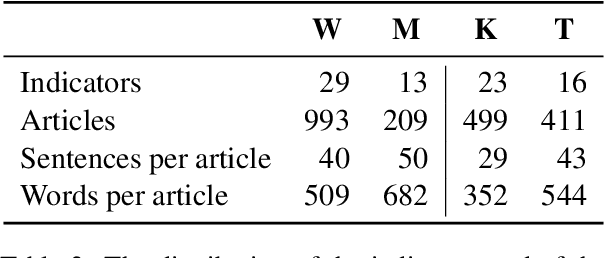
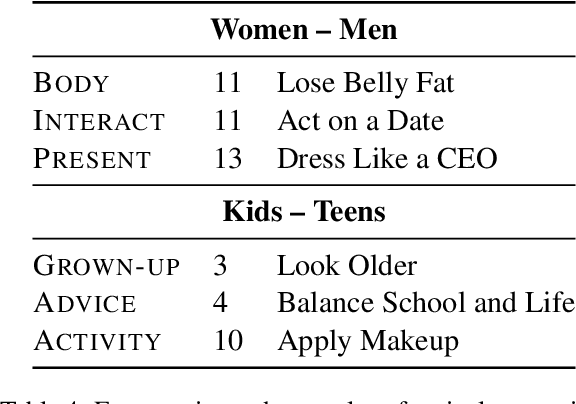

Instructional texts for specific target groups should ideally take into account the prior knowledge and needs of the readers in order to guide them efficiently to their desired goals. However, targeting specific groups also carries the risk of reflecting disparate social norms and subtle stereotypes. In this paper, we investigate the extent to which how-to guides from one particular platform, wikiHow, differ in practice depending on the intended audience. We conduct two case studies in which we examine qualitative features of texts written for specific audiences. In a generalization study, we investigate which differences can also be systematically demonstrated using computational methods. The results of our studies show that guides from wikiHow, like other text genres, are subject to subtle biases. We aim to raise awareness of these inequalities as a first step to addressing them in future work.
The Utility of Structural Features in BiLSTM-based Dependency Parsers
Jun 04, 2019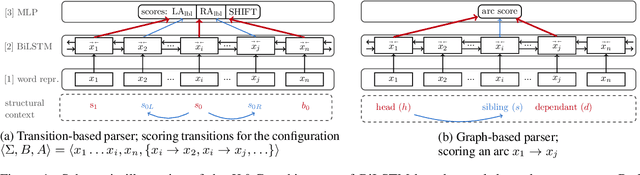

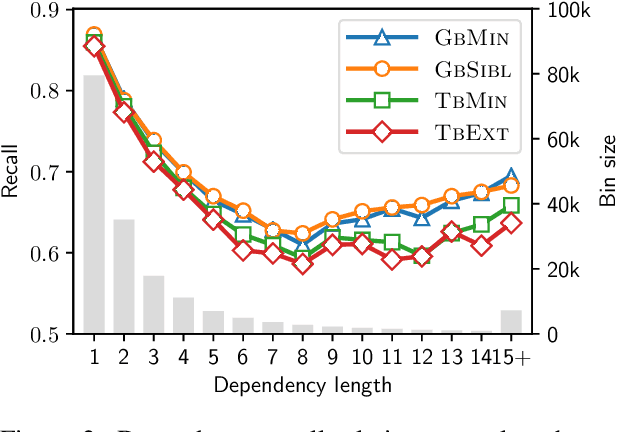

Classical non-neural dependency parsers put considerable effort on the design of feature functions. Especially, they benefit from information coming from structural features, such as features drawn from neighboring tokens in the dependency tree. In contrast, their BiLSTM-based successors achieve state-of-the-art performance without explicit information about the structural context. In this paper we aim to answer the question: How much structural context are the BiLSTM representations able to capture implicitly? We show that features drawn from partial subtrees become redundant when the BiLSTMs are used. We provide a deep insight into information flow in transition- and graph-based neural architectures to demonstrate where the implicit information comes from when the parsers make their decisions. Finally, with model ablations we demonstrate that the structural context is not only present in the models, but it significantly influences their performance.
IMS at the PolEval 2018: A Bulky Ensemble Depedency Parser meets 12 Simple Rules for Predicting Enhanced Dependencies in Polish
Nov 07, 2018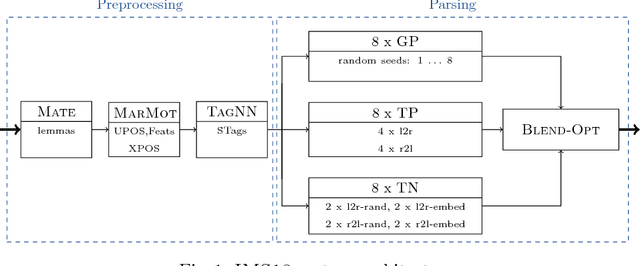
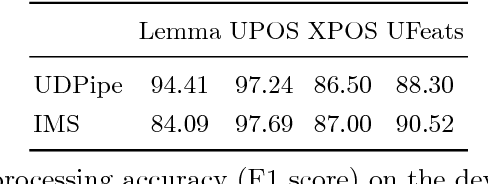
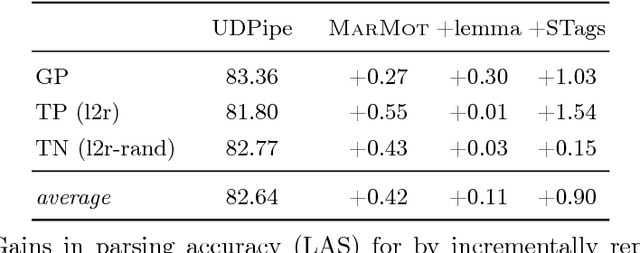
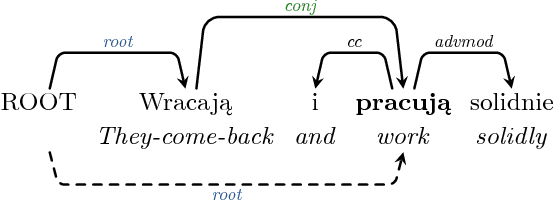
This paper presents the IMS contribution to the PolEval 2018 Shared Task. We submitted systems for both of the Subtasks of Task 1. In Subtask (A), which was about dependency parsing, we used our ensemble system from the CoNLL 2017 UD Shared Task. The system first preprocesses the sentences with a CRF POS/morphological tagger and predicts supertags with a neural tagger. Then, it employs multiple instances of three different parsers and merges their outputs by applying blending. The system achieved the second place out of four participating teams. In this paper we show which components of the system were the most responsible for its final performance. The goal of Subtask (B) was to predict enhanced graphs. Our approach consisted of two steps: parsing the sentences with our ensemble system from Subtask (A), and applying 12 simple rules to obtain the final dependency graphs. The rules introduce additional enhanced arcs only for tokens with "conj" heads (conjuncts). They do not predict semantic relations at all. The system ranked first out of three participating teams. In this paper we show examples of rules we designed and analyze the relation between the quality of automatically parsed trees and the accuracy of the enhanced graphs.