 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeadlines You Won't Forget: Can Pronoun Insertion Increase Memorability?
Apr 21, 2026For news headlines to influence beliefs and drive action, relevant information needs to be retained and retrievable from memory. In this probing study we draw on experiment designs from cognitive psychology to examine how a specific linguistic feature, namely direct address through first- and second-person pronouns, affects memorability and to what extent it is feasible to use large language models for the targeted insertion of such a feature into existing text without changing its core meaning. Across three controlled memorization experiments with a total of 240 participants, yielding 7,680 unique memory judgments, we show that pronoun insertion has mixed effects on memorability. Exploratory analyses indicate that effects differ based on headline topic, how pronouns are inserted and their immediate contexts. Additional data and fine-grained analysis is needed to draw definitive conclusions on these mediating factors. We further show that automatic revisions by LLMs are not always appropriate: Crowdsourced evaluations find many of them to be lacking in content accuracy and emotion retention or resulting in unnatural writing style. We make our collected data available for future work.
A Computational Analysis of Vagueness in Revisions of Instructional Texts
Sep 21, 2023



WikiHow is an open-domain repository of instructional articles for a variety of tasks, which can be revised by users. In this paper, we extract pairwise versions of an instruction before and after a revision was made. Starting from a noisy dataset of revision histories, we specifically extract and analyze edits that involve cases of vagueness in instructions. We further investigate the ability of a neural model to distinguish between two versions of an instruction in our data by adopting a pairwise ranking task from previous work and showing improvements over existing baselines.
SemEval-2022 Task 7: Identifying Plausible Clarifications of Implicit and Underspecified Phrases in Instructional Texts
Sep 21, 2023



We describe SemEval-2022 Task 7, a shared task on rating the plausibility of clarifications in instructional texts. The dataset for this task consists of manually clarified how-to guides for which we generated alternative clarifications and collected human plausibility judgements. The task of participating systems was to automatically determine the plausibility of a clarification in the respective context. In total, 21 participants took part in this task, with the best system achieving an accuracy of 68.9%. This report summarizes the results and findings from 8 teams and their system descriptions. Finally, we show in an additional evaluation that predictions by the top participating team make it possible to identify contexts with multiple plausible clarifications with an accuracy of 75.2%.
How-to Guides for Specific Audiences: A Corpus and Initial Findings
Sep 21, 2023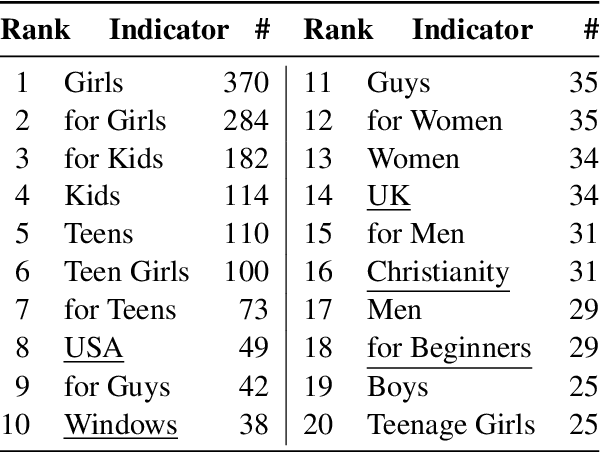
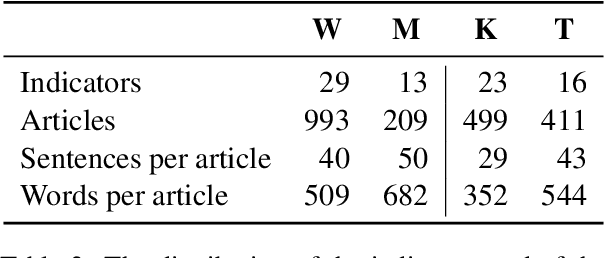
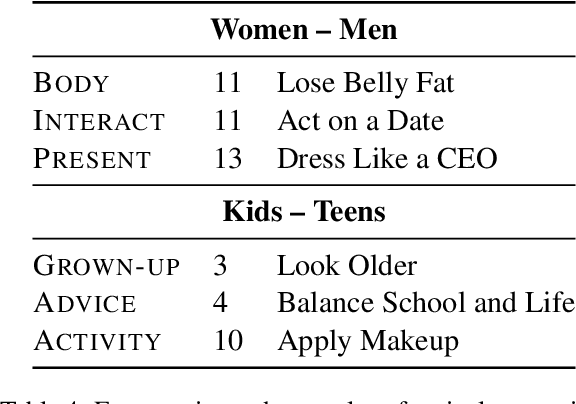

Instructional texts for specific target groups should ideally take into account the prior knowledge and needs of the readers in order to guide them efficiently to their desired goals. However, targeting specific groups also carries the risk of reflecting disparate social norms and subtle stereotypes. In this paper, we investigate the extent to which how-to guides from one particular platform, wikiHow, differ in practice depending on the intended audience. We conduct two case studies in which we examine qualitative features of texts written for specific audiences. In a generalization study, we investigate which differences can also be systematically demonstrated using computational methods. The results of our studies show that guides from wikiHow, like other text genres, are subject to subtle biases. We aim to raise awareness of these inequalities as a first step to addressing them in future work.
Conference proceedings KI4Industry AI for SMEs -- the online congress for practical entry into AI for SMEs
Jul 05, 2021
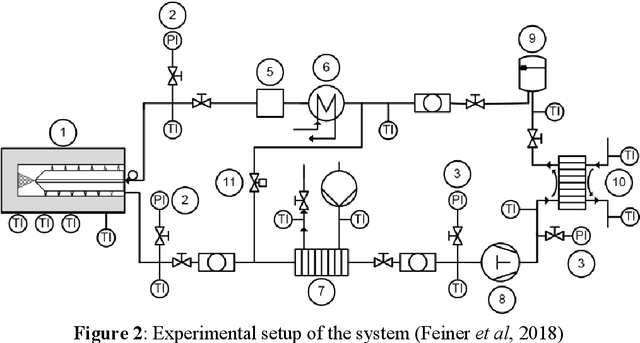
The Institute of Materials and Processes, IMP, of the University of Applied Sciences in Karlsruhe, Germany in cooperation with VDI Verein Deutscher Ingenieure e.V, AEN Automotive Engineering Network and their cooperation partners present their competences of AI-based solution approaches in the production engineering field. The online congress KI 4 Industry on November 12 and 13, 2020, showed what opportunities the use of artificial intelligence offers for medium-sized manufacturing companies, SMEs, and where potential fields of application lie. The main purpose of KI 4 Industry is to increase the transfer of knowledge, research and technology from universities to small and medium-sized enterprises, to demystify the term AI and to encourage companies to use AI-based solutions in their own value chain or in their products.
HAWKEYE: Adversarial Example Detector for Deep Neural Networks
Sep 22, 2019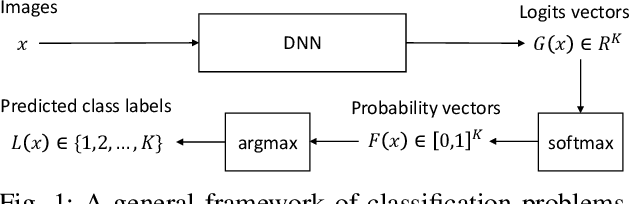
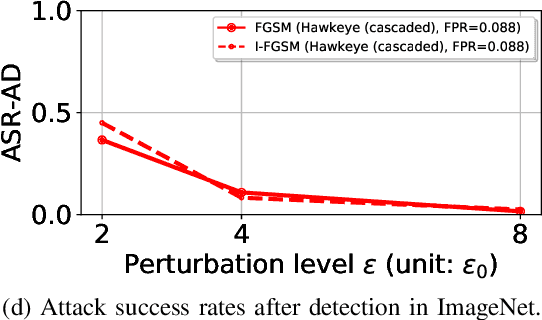
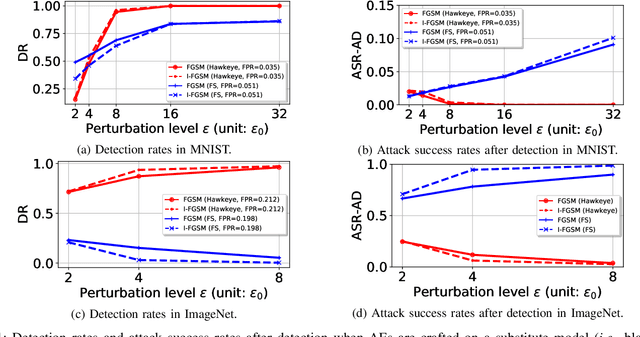

Adversarial examples (AEs) are images that can mislead deep neural network (DNN) classifiers via introducing slight perturbations into original images. Recent work has shown that detecting AEs can be more effective against AEs than preventing them from being generated. However, the state-of-the-art AE detection still shows a high false positive rate, thereby rejecting a considerable amount of normal images. To address this issue, we propose HAWKEYE, which is a separate neural network that analyzes the output layer of the DNN, and detects AEs. HAWKEYE's AE detector utilizes a quantized version of an input image as a reference, and is trained to distinguish the variation characteristics of the DNN output on an input image from the DNN output on its reference image. We also show that cascading our AE detectors that are trained for different quantization step sizes can drastically reduce a false positive rate, while keeping a detection rate high.
Detecting Everyday Scenarios in Narrative Texts
Jun 10, 2019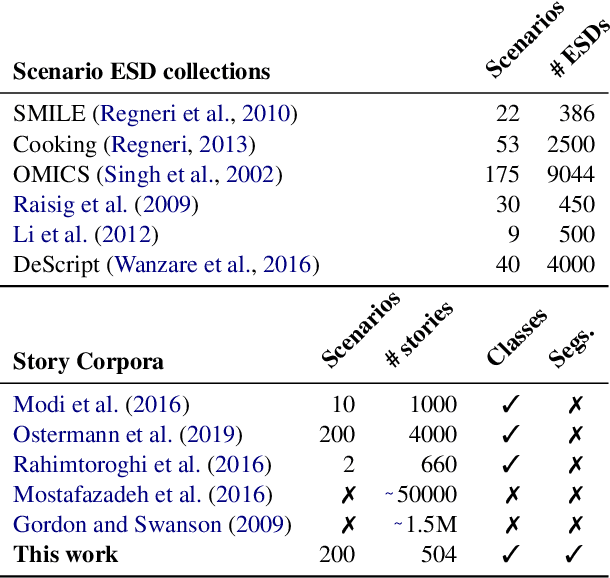
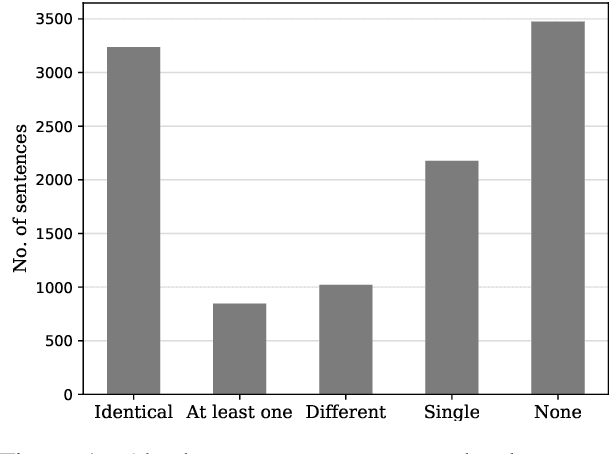

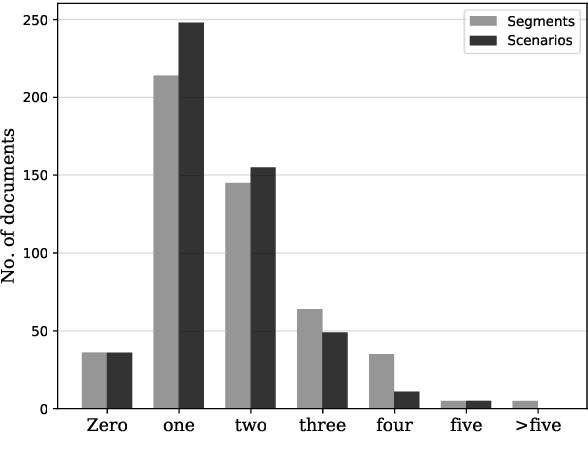
Script knowledge consists of detailed information on everyday activities. Such information is often taken for granted in text and needs to be inferred by readers. Therefore, script knowledge is a central component to language comprehension. Previous work on representing scripts is mostly based on extensive manual work or limited to scenarios that can be found with sufficient redundancy in large corpora. We introduce the task of scenario detection, in which we identify references to scripts. In this task, we address a wide range of different scripts (200 scenarios) and we attempt to identify all references to them in a collection of narrative texts. We present a first benchmark data set and a baseline model that tackles scenario detection using techniques from topic segmentation and text classification.
MCScript2.0: A Machine Comprehension Corpus Focused on Script Events and Participants
May 30, 2019


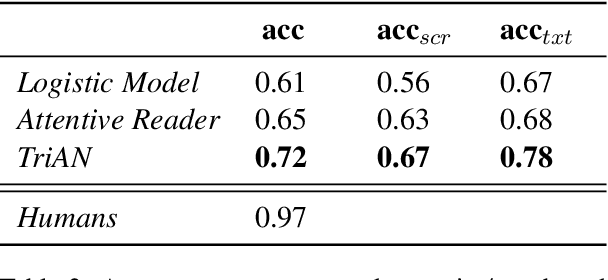
We introduce MCScript2.0, a machine comprehension corpus for the end-to-end evaluation of script knowledge. MCScript2.0 contains approx. 20,000 questions on approx. 3,500 texts, crowdsourced based on a new collection process that results in challenging questions. Half of the questions cannot be answered from the reading texts, but require the use of commonsense and, in particular, script knowledge. We give a thorough analysis of our corpus and show that while the task is not challenging to humans, existing machine comprehension models fail to perform well on the data, even if they make use of a commonsense knowledge base. The dataset is available at http://www.sfb1102.uni-saarland.de/?page_id=2582
Role Semantics for Better Models of Implicit Discourse Relations
Aug 24, 2018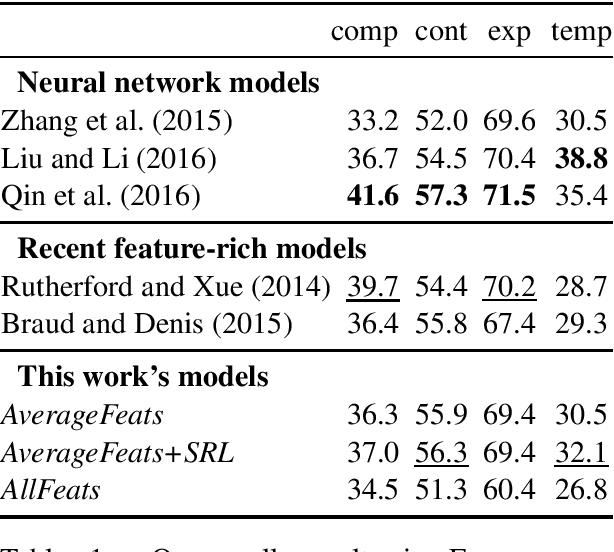
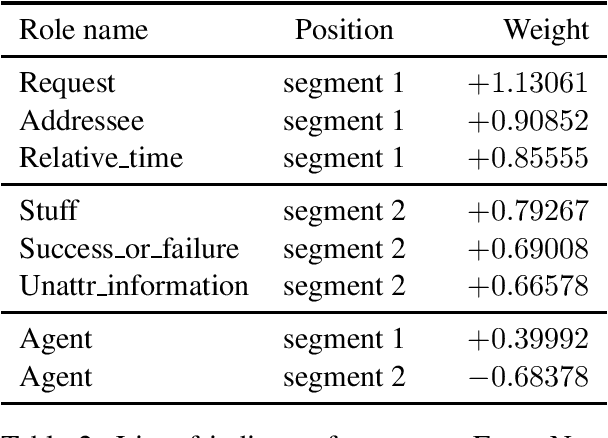
Predicting the structure of a discourse is challenging because relations between discourse segments are often implicit and thus hard to distinguish computationally. I extend previous work to classify implicit discourse relations by introducing a novel set of features on the level of semantic roles. My results demonstrate that such features are helpful, yielding results competitive with other feature-rich approaches on the PDTB. My main contribution is an analysis of improvements that can be traced back to role-based features, providing insights into why and when role semantics is helpful.
Visually grounded cross-lingual keyword spotting in speech
Jun 13, 2018

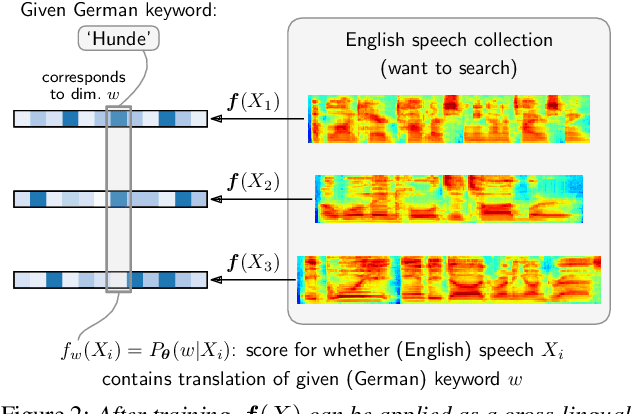
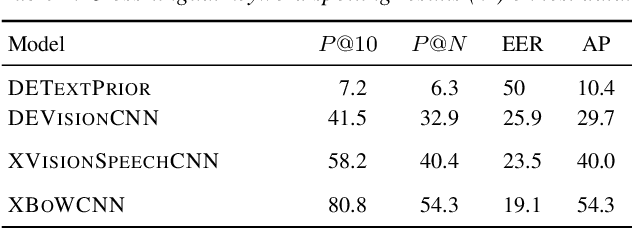
Recent work considered how images paired with speech can be used as supervision for building speech systems when transcriptions are not available. We ask whether visual grounding can be used for cross-lingual keyword spotting: given a text keyword in one language, the task is to retrieve spoken utterances containing that keyword in another language. This could enable searching through speech in a low-resource language using text queries in a high-resource language. As a proof-of-concept, we use English speech with German queries: we use a German visual tagger to add keyword labels to each training image, and then train a neural network to map English speech to German keywords. Without seeing parallel speech-transcriptions or translations, the model achieves a precision at ten of 58%. We show that most erroneous retrievals contain equivalent or semantically relevant keywords; excluding these would improve P@10 to 91%.