 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin-Free: Achieving Better Cross-Window Attention and Efficiency with Size-varying Window
Jun 23, 2023Transformer models have shown great potential in computer vision, following their success in language tasks. Swin Transformer is one of them that outperforms convolution-based architectures in terms of accuracy, while improving efficiency when compared to Vision Transformer (ViT) and its variants, which have quadratic complexity with respect to the input size. Swin Transformer features shifting windows that allows cross-window connection while limiting self-attention computation to non-overlapping local windows. However, shifting windows introduces memory copy operations, which account for a significant portion of its runtime. To mitigate this issue, we propose Swin-Free in which we apply size-varying windows across stages, instead of shifting windows, to achieve cross-connection among local windows. With this simple design change, Swin-Free runs faster than the Swin Transformer at inference with better accuracy. Furthermore, we also propose a few of Swin-Free variants that are faster than their Swin Transformer counterparts.
Depth Estimation with Simplified Transformer
Apr 28, 2022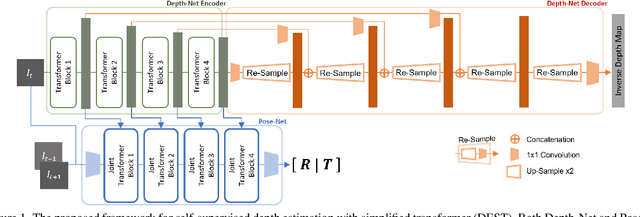
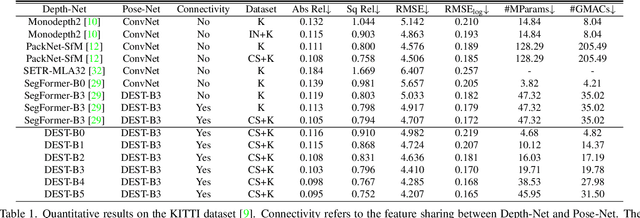
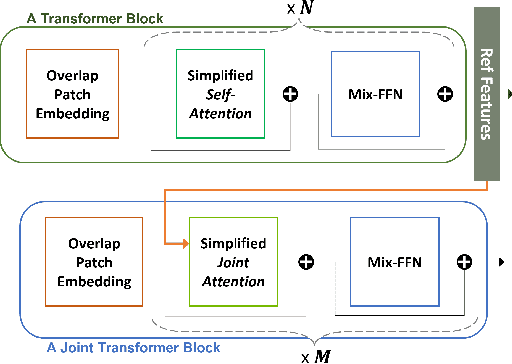
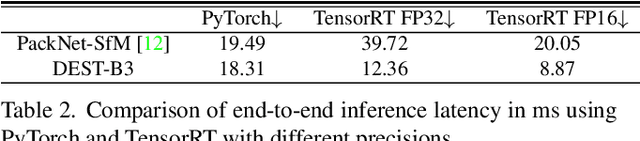
Transformer and its variants have shown state-of-the-art results in many vision tasks recently, ranging from image classification to dense prediction. Despite of their success, limited work has been reported on improving the model efficiency for deployment in latency-critical applications, such as autonomous driving and robotic navigation. In this paper, we aim at improving upon the existing transformers in vision, and propose a method for self-supervised monocular Depth Estimation with Simplified Transformer (DEST), which is efficient and particularly suitable for deployment on GPU-based platforms. Through strategic design choices, our model leads to significant reduction in model size, complexity, as well as inference latency, while achieving superior accuracy as compared to state-of-the-art. We also show that our design generalize well to other dense prediction task without bells and whistles.
HAWKEYE: Adversarial Example Detector for Deep Neural Networks
Sep 22, 2019
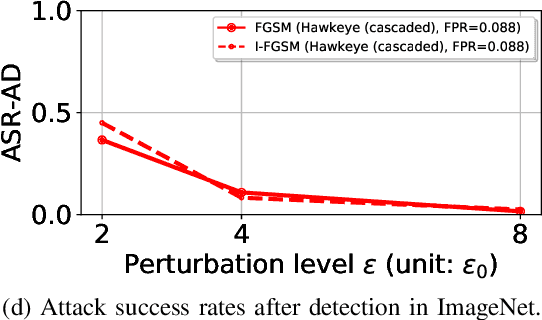
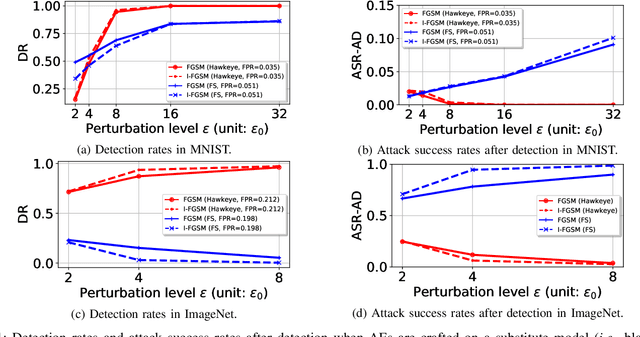

Adversarial examples (AEs) are images that can mislead deep neural network (DNN) classifiers via introducing slight perturbations into original images. Recent work has shown that detecting AEs can be more effective against AEs than preventing them from being generated. However, the state-of-the-art AE detection still shows a high false positive rate, thereby rejecting a considerable amount of normal images. To address this issue, we propose HAWKEYE, which is a separate neural network that analyzes the output layer of the DNN, and detects AEs. HAWKEYE's AE detector utilizes a quantized version of an input image as a reference, and is trained to distinguish the variation characteristics of the DNN output on an input image from the DNN output on its reference image. We also show that cascading our AE detectors that are trained for different quantization step sizes can drastically reduce a false positive rate, while keeping a detection rate high.
ApproxNet: Content and Contention Aware Video Analytics System for the Edge
Aug 28, 2019

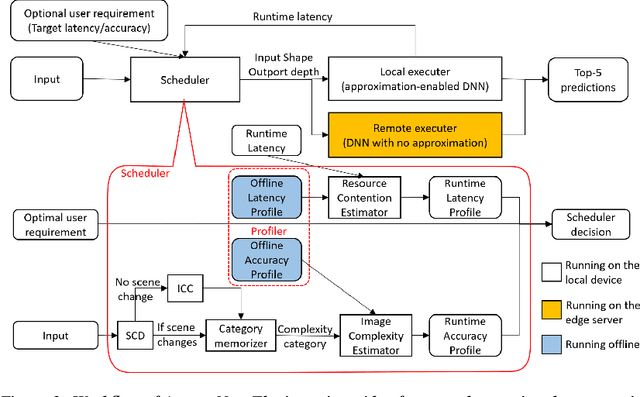
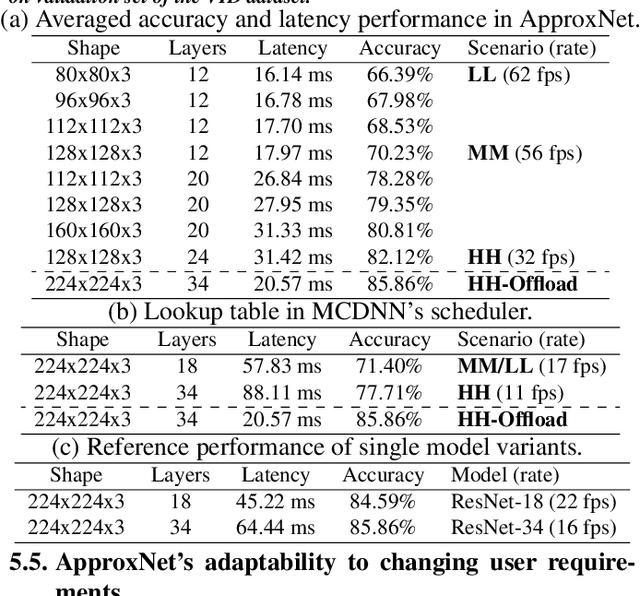
Videos take lot of time to transport over the network, hence running analytics on live video at the edge devices, right where it was captured has become an important system driver. However these edge devices, e.g., IoT devices, surveillance cameras, AR/VR gadgets are resource constrained. This makes it impossible to run state-of-the-art heavy Deep Neural Networks (DNNs) on them and yet provide low and stable latency under various circumstances, such as, changes in the resource availability on the device, the content characteristics, or requirements from the user. In this paper we introduce ApproxNet, a video analytics system for the edge. It enables novel dynamic approximation techniques to achieve desired inference latency and accuracy trade-off under different system conditions and resource contentions, variations in the complexity of the video contents and user requirements. It achieves this by enabling two approximation knobs within a single DNN model, rather than creating and maintaining an ensemble of models (such as in MCDNN [Mobisys-16]). Ensemble models run into memory issues on the lightweight devices and incur large switching penalties among the models in response to runtime changes. We show that ApproxNet can adapt seamlessly at runtime to video content changes and changes in system dynamics to provide low and stable latency for object detection on a video stream. We compare the accuracy and the latency to ResNet [2015], MCDNN, and MobileNets [Google-2017].