 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduceFormer: Attention with Tensor Reduction by Summation
Jun 11, 2024Transformers have excelled in many tasks including vision. However, efficient deployment of transformer models in low-latency or high-throughput applications is hindered by the computation in the attention mechanism which involves expensive operations such as matrix multiplication and Softmax. To address this, we introduce ReduceFormer, a family of models optimized for efficiency with the spirit of attention. ReduceFormer leverages only simple operations such as reduction and element-wise multiplication, leading to greatly simplified architecture and improved inference performance, with up to 37% reduction in latency and 44% improvement in throughput, while maintaining competitive accuracy comparable to other recent methods. The proposed model family is suitable for edge devices where compute resource and memory bandwidth are limited, as well as for cloud computing where high throughput is sought after.
Swin-Free: Achieving Better Cross-Window Attention and Efficiency with Size-varying Window
Jun 23, 2023Transformer models have shown great potential in computer vision, following their success in language tasks. Swin Transformer is one of them that outperforms convolution-based architectures in terms of accuracy, while improving efficiency when compared to Vision Transformer (ViT) and its variants, which have quadratic complexity with respect to the input size. Swin Transformer features shifting windows that allows cross-window connection while limiting self-attention computation to non-overlapping local windows. However, shifting windows introduces memory copy operations, which account for a significant portion of its runtime. To mitigate this issue, we propose Swin-Free in which we apply size-varying windows across stages, instead of shifting windows, to achieve cross-connection among local windows. With this simple design change, Swin-Free runs faster than the Swin Transformer at inference with better accuracy. Furthermore, we also propose a few of Swin-Free variants that are faster than their Swin Transformer counterparts.
Depth Estimation with Simplified Transformer
Apr 28, 2022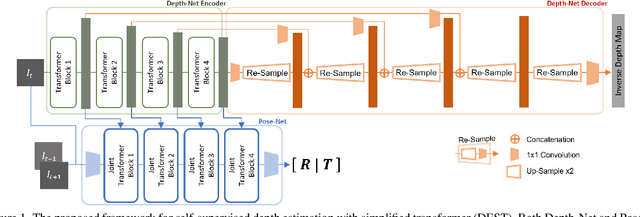
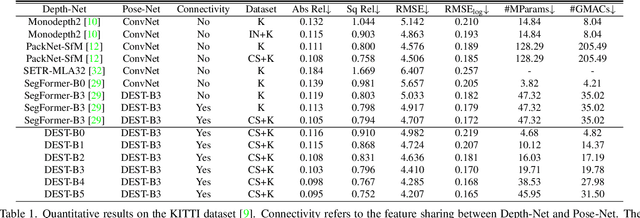
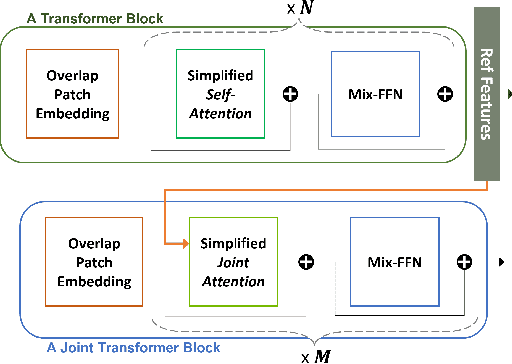
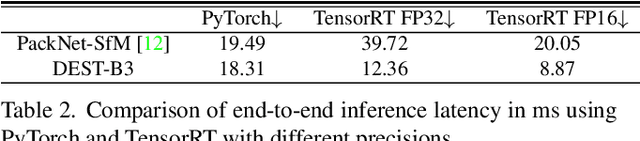
Transformer and its variants have shown state-of-the-art results in many vision tasks recently, ranging from image classification to dense prediction. Despite of their success, limited work has been reported on improving the model efficiency for deployment in latency-critical applications, such as autonomous driving and robotic navigation. In this paper, we aim at improving upon the existing transformers in vision, and propose a method for self-supervised monocular Depth Estimation with Simplified Transformer (DEST), which is efficient and particularly suitable for deployment on GPU-based platforms. Through strategic design choices, our model leads to significant reduction in model size, complexity, as well as inference latency, while achieving superior accuracy as compared to state-of-the-art. We also show that our design generalize well to other dense prediction task without bells and whistles.