 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin-Free: Achieving Better Cross-Window Attention and Efficiency with Size-varying Window
Jun 23, 2023Transformer models have shown great potential in computer vision, following their success in language tasks. Swin Transformer is one of them that outperforms convolution-based architectures in terms of accuracy, while improving efficiency when compared to Vision Transformer (ViT) and its variants, which have quadratic complexity with respect to the input size. Swin Transformer features shifting windows that allows cross-window connection while limiting self-attention computation to non-overlapping local windows. However, shifting windows introduces memory copy operations, which account for a significant portion of its runtime. To mitigate this issue, we propose Swin-Free in which we apply size-varying windows across stages, instead of shifting windows, to achieve cross-connection among local windows. With this simple design change, Swin-Free runs faster than the Swin Transformer at inference with better accuracy. Furthermore, we also propose a few of Swin-Free variants that are faster than their Swin Transformer counterparts.
Emotional Video to Audio Transformation Using Deep Recurrent Neural Networks and a Neuro-Fuzzy System
Apr 05, 2020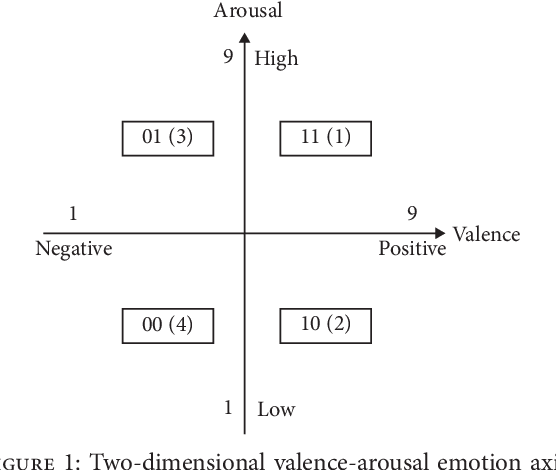

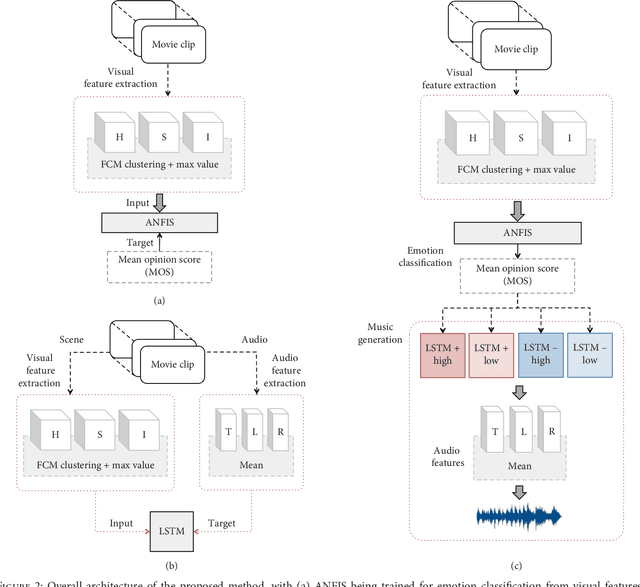
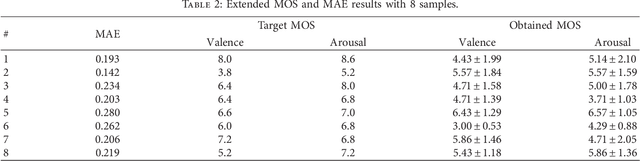
Generating music with emotion similar to that of an input video is a very relevant issue nowadays. Video content creators and automatic movie directors benefit from maintaining their viewers engaged, which can be facilitated by producing novel material eliciting stronger emotions in them. Moreover, there's currently a demand for more empathetic computers to aid humans in applications such as augmenting the perception ability of visually and/or hearing impaired people. Current approaches overlook the video's emotional characteristics in the music generation step, only consider static images instead of videos, are unable to generate novel music, and require a high level of human effort and skills. In this study, we propose a novel hybrid deep neural network that uses an Adaptive Neuro-Fuzzy Inference System to predict a video's emotion from its visual features and a deep Long Short-Term Memory Recurrent Neural Network to generate its corresponding audio signals with similar emotional inkling. The former is able to appropriately model emotions due to its fuzzy properties, and the latter is able to model data with dynamic time properties well due to the availability of the previous hidden state information. The novelty of our proposed method lies in the extraction of visual emotional features in order to transform them into audio signals with corresponding emotional aspects for users. Quantitative experiments show low mean absolute errors of 0.217 and 0.255 in the Lindsey and DEAP datasets respectively, and similar global features in the spectrograms. This indicates that our model is able to appropriately perform domain transformation between visual and audio features. Based on experimental results, our model can effectively generate audio that matches the scene eliciting a similar emotion from the viewer in both datasets, and music generated by our model is also chosen more often.
* Published (https://www.hindawi.com/journals/mpe/2020/8478527/)
Stacked DeBERT: All Attention in Incomplete Data for Text Classification
Jan 01, 2020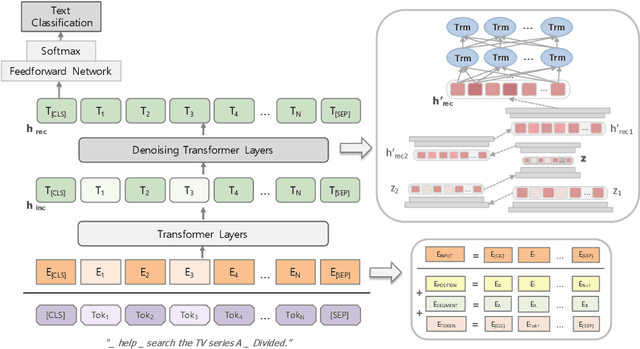


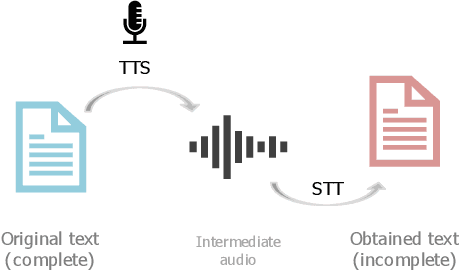
In this paper, we propose Stacked DeBERT, short for Stacked Denoising Bidirectional Encoder Representations from Transformers. This novel model improves robustness in incomplete data, when compared to existing systems, by designing a novel encoding scheme in BERT, a powerful language representation model solely based on attention mechanisms. Incomplete data in natural language processing refer to text with missing or incorrect words, and its presence can hinder the performance of current models that were not implemented to withstand such noises, but must still perform well even under duress. This is due to the fact that current approaches are built for and trained with clean and complete data, and thus are not able to extract features that can adequately represent incomplete data. Our proposed approach consists of obtaining intermediate input representations by applying an embedding layer to the input tokens followed by vanilla transformers. These intermediate features are given as input to novel denoising transformers which are responsible for obtaining richer input representations. The proposed approach takes advantage of stacks of multilayer perceptrons for the reconstruction of missing words' embeddings by extracting more abstract and meaningful hidden feature vectors, and bidirectional transformers for improved embedding representation. We consider two datasets for training and evaluation: the Chatbot Natural Language Understanding Evaluation Corpus and Kaggle's Twitter Sentiment Corpus. Our model shows improved F1-scores and better robustness in informal/incorrect texts present in tweets and in texts with Speech-to-Text error in the sentiment and intent classification tasks.
Employing Genetic Algorithm as an Efficient Alternative to Parameter Sweep Based Multi-Layer Thickness Optimization in Solar Cells
Sep 26, 2019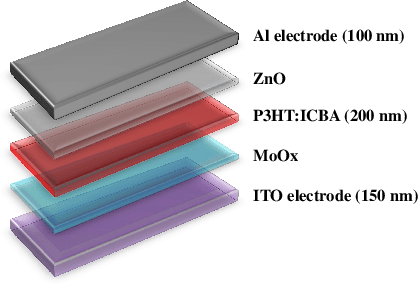
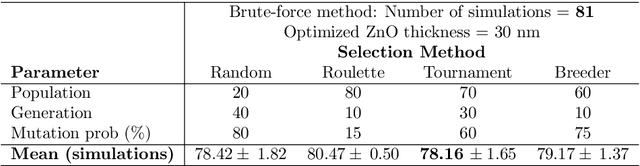
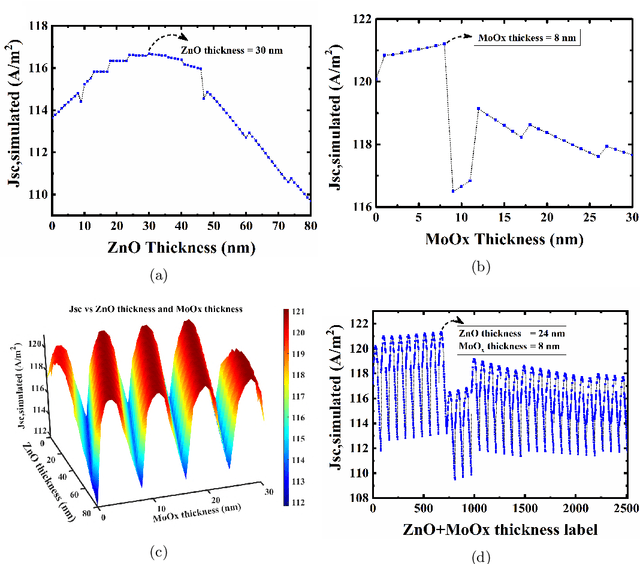

Conventional solar cells are predominately designed similar to a stacked structure. Optimizing the layer thicknesses in this stack structure is crucial to extract the best efficiency of the solar cell. The commonplace method used in optimization simulations, such as for optimizing the optical spacer layers' thicknesses, is the parameter sweep. Our experiments show that the introduction of genetic algorithm based method results in a significantly faster and accurate search method when compared to brute-force parameter sweep method in both single and multi-layer optimization. While other sweep methods can also outperform the brute-force method, they do not consistently exhibit $100\%$ accuracy in the optimized results like our genetic algorithm. Our best case scenario was observed to utilize 57.9% less simulations than brute-force method.