 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked DeBERT: All Attention in Incomplete Data for Text Classification
Paper and Code
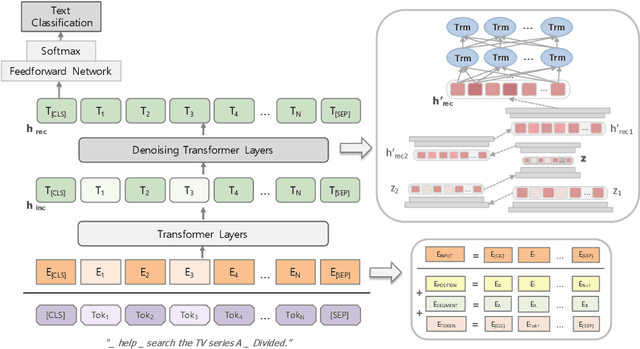


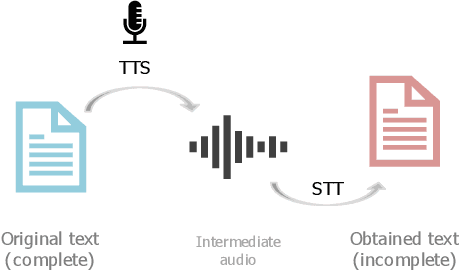
In this paper, we propose Stacked DeBERT, short for Stacked Denoising Bidirectional Encoder Representations from Transformers. This novel model improves robustness in incomplete data, when compared to existing systems, by designing a novel encoding scheme in BERT, a powerful language representation model solely based on attention mechanisms. Incomplete data in natural language processing refer to text with missing or incorrect words, and its presence can hinder the performance of current models that were not implemented to withstand such noises, but must still perform well even under duress. This is due to the fact that current approaches are built for and trained with clean and complete data, and thus are not able to extract features that can adequately represent incomplete data. Our proposed approach consists of obtaining intermediate input representations by applying an embedding layer to the input tokens followed by vanilla transformers. These intermediate features are given as input to novel denoising transformers which are responsible for obtaining richer input representations. The proposed approach takes advantage of stacks of multilayer perceptrons for the reconstruction of missing words' embeddings by extracting more abstract and meaningful hidden feature vectors, and bidirectional transformers for improved embedding representation. We consider two datasets for training and evaluation: the Chatbot Natural Language Understanding Evaluation Corpus and Kaggle's Twitter Sentiment Corpus. Our model shows improved F1-scores and better robustness in informal/incorrect texts present in tweets and in texts with Speech-to-Text error in the sentiment and intent classification tasks.