 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMS at the PolEval 2018: A Bulky Ensemble Depedency Parser meets 12 Simple Rules for Predicting Enhanced Dependencies in Polish
Paper and Code
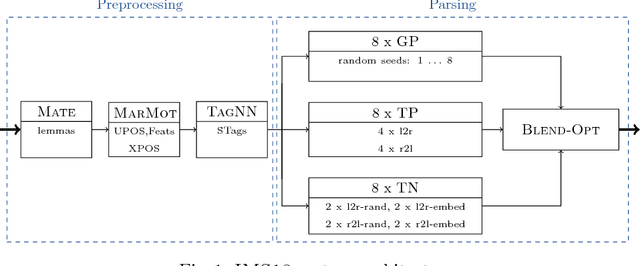
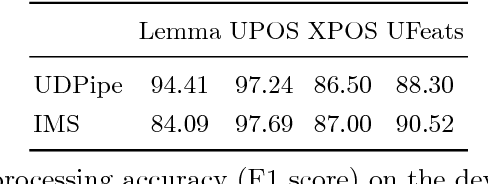
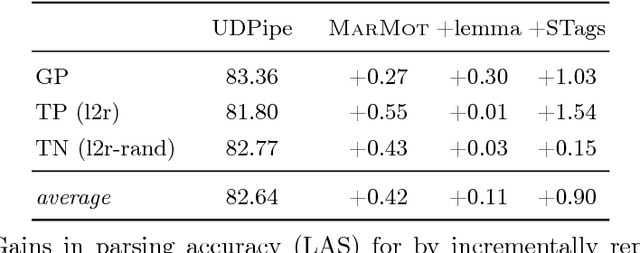
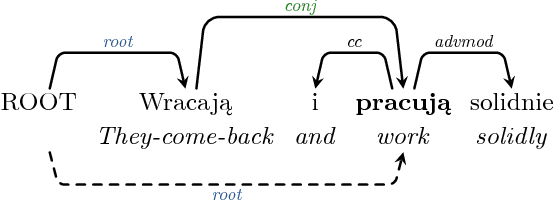
This paper presents the IMS contribution to the PolEval 2018 Shared Task. We submitted systems for both of the Subtasks of Task 1. In Subtask (A), which was about dependency parsing, we used our ensemble system from the CoNLL 2017 UD Shared Task. The system first preprocesses the sentences with a CRF POS/morphological tagger and predicts supertags with a neural tagger. Then, it employs multiple instances of three different parsers and merges their outputs by applying blending. The system achieved the second place out of four participating teams. In this paper we show which components of the system were the most responsible for its final performance. The goal of Subtask (B) was to predict enhanced graphs. Our approach consisted of two steps: parsing the sentences with our ensemble system from Subtask (A), and applying 12 simple rules to obtain the final dependency graphs. The rules introduce additional enhanced arcs only for tokens with "conj" heads (conjuncts). They do not predict semantic relations at all. The system ranked first out of three participating teams. In this paper we show examples of rules we designed and analyze the relation between the quality of automatically parsed trees and the accuracy of the enhanced graphs.