 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsody Cloning in Zero-Shot Multispeaker Text-to-Speech
Paper and Code
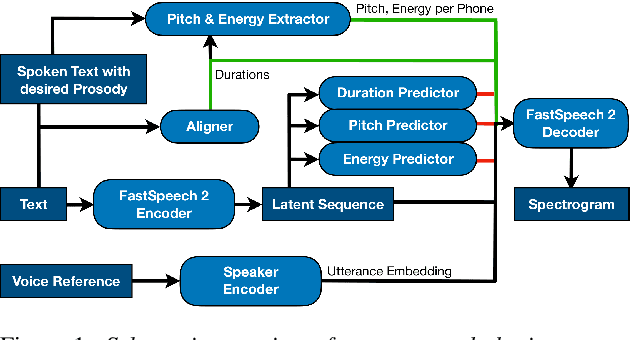
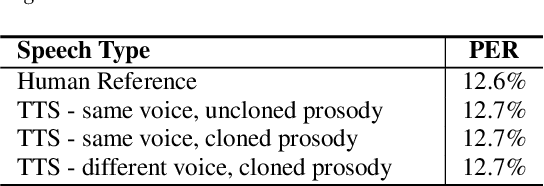

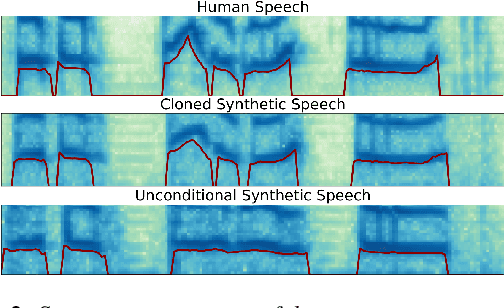
The cloning of a speaker's voice using an untranscribed reference sample is one of the great advances of modern neural text-to-speech (TTS) methods. Approaches for mimicking the prosody of a transcribed reference audio have also been proposed recently. In this work, we bring these two tasks together for the first time through utterance level normalization in conjunction with an utterance level speaker embedding. We further introduce a lightweight aligner for extracting fine-grained prosodic features, that can be finetuned on individual samples within seconds. We show that it is possible to clone the voice of a speaker as well as the prosody of a spoken reference independently without any degradation in quality and high similarity to both original voice and prosody, as our objective evaluation and human study show. All of our code and trained models are available, alongside static and interactive demos.