 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigations on Speech Recognition Systems for Low-Resource Dialectal Arabic-English Code-Switching Speech
Aug 29, 2021
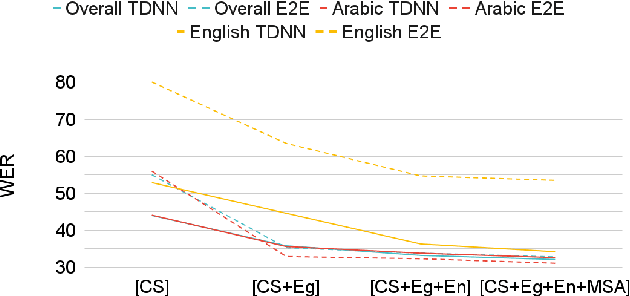
Code-switching (CS), defined as the mixing of languages in conversations, has become a worldwide phenomenon. The prevalence of CS has been recently met with a growing demand and interest to build CS ASR systems. In this paper, we present our work on code-switched Egyptian Arabic-English automatic speech recognition (ASR). We first contribute in filling the huge gap in resources by collecting, analyzing and publishing our spontaneous CS Egyptian Arabic-English speech corpus. We build our ASR systems using DNN-based hybrid and Transformer-based end-to-end models. In this paper, we present a thorough comparison between both approaches under the setting of a low-resource, orthographically unstandardized, and morphologically rich language pair. We show that while both systems give comparable overall recognition results, each system provides complementary sets of strength points. We show that recognition can be improved by combining the outputs of both systems. We propose several effective system combination approaches, where hypotheses of both systems are merged on sentence- and word-levels. Our approaches result in overall WER relative improvement of 4.7%, over a baseline performance of 32.1% WER. In the case of intra-sentential CS sentences, we achieve WER relative improvement of 4.8%. Our best performing system achieves 30.6% WER on ArzEn test set.
Code-switching Language Modeling With Bilingual Word Embeddings: A Case Study for Egyptian Arabic-English
Sep 24, 2019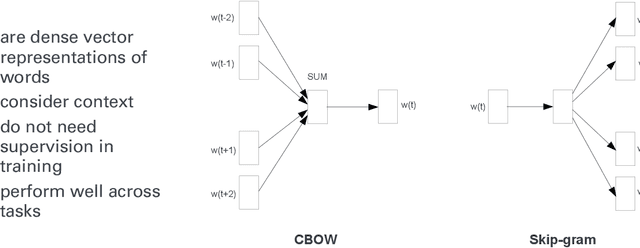

Code-switching (CS) is a widespread phenomenon among bilingual and multilingual societies. The lack of CS resources hinders the performance of many NLP tasks. In this work, we explore the potential use of bilingual word embeddings for code-switching (CS) language modeling (LM) in the low resource Egyptian Arabic-English language. We evaluate different state-of-the-art bilingual word embeddings approaches that require cross-lingual resources at different levels and propose an innovative but simple approach that jointly learns bilingual word representations without the use of any parallel data, relying only on monolingual and a small amount of CS data. While all representations improve CS LM, ours performs the best and improves perplexity 33.5% relative over the baseline.
* 11 pages, 1 figure (having 2 sub-figures), submitted to the 21st International Conference on Speech and Computer (SPECOM'19),