 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArzEn-ST: A Three-way Speech Translation Corpus for Code-Switched Egyptian Arabic - English
Nov 22, 2022

We present our work on collecting ArzEn-ST, a code-switched Egyptian Arabic - English Speech Translation Corpus. This corpus is an extension of the ArzEn speech corpus, which was collected through informal interviews with bilingual speakers. In this work, we collect translations in both directions, monolingual Egyptian Arabic and monolingual English, forming a three-way speech translation corpus. We make the translation guidelines and corpus publicly available. We also report results for baseline systems for machine translation and speech translation tasks. We believe this is a valuable resource that can motivate and facilitate further research studying the code-switching phenomenon from a linguistic perspective and can be used to train and evaluate NLP systems.
Exploring Segmentation Approaches for Neural Machine Translation of Code-Switched Egyptian Arabic-English Text
Oct 11, 2022
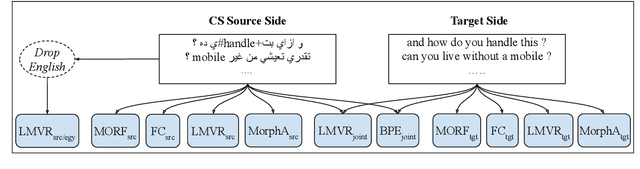
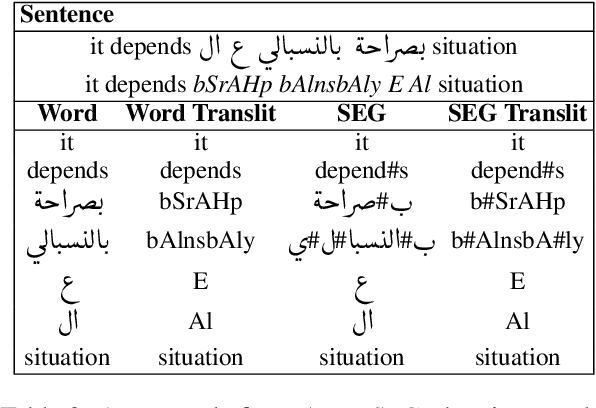
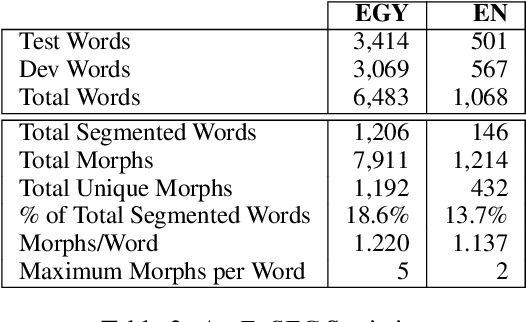
Data sparsity is one of the main challenges posed by Code-switching (CS), which is further exacerbated in the case of morphologically rich languages. For the task of Machine Translation (MT), morphological segmentation has proven successful in alleviating data sparsity in monolingual contexts; however, it has not been investigated for CS settings. In this paper, we study the effectiveness of different segmentation approaches on MT performance, covering morphology-based and frequency-based segmentation techniques. We experiment on MT from code-switched Arabic-English to English. We provide detailed analysis, examining a variety of conditions, such as data size and sentences with different degrees in CS. Empirical results show that morphology-aware segmenters perform the best in segmentation tasks but under-perform in MT. Nevertheless, we find that the choice of the segmentation setup to use for MT is highly dependent on the data size. For extreme low-resource scenarios, a combination of frequency and morphology-based segmentations is shown to perform the best. For more resourced settings, such a combination does not bring significant improvements over the use of frequency-based segmentation.
The Who in Code-Switching: A Case Study for Predicting Egyptian Arabic-English Code-Switching Levels based on Character Profiles
Jul 31, 2022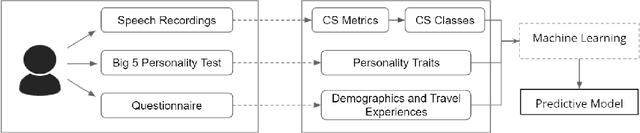

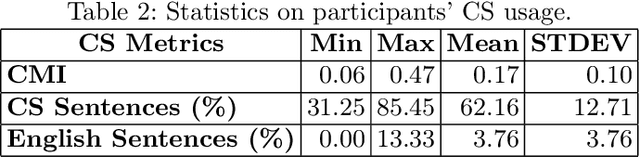
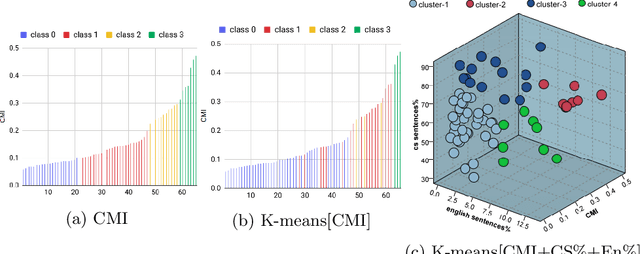
Code-switching (CS) is a common linguistic phenomenon exhibited by multilingual individuals, where they tend to alternate between languages within one single conversation. CS is a complex phenomenon that not only encompasses linguistic challenges, but also contains a great deal of complexity in terms of its dynamic behaviour across speakers. Given that the factors giving rise to CS vary from one country to the other, as well as from one person to the other, CS is found to be a speaker-dependant behaviour, where the frequency by which the foreign language is embedded differs across speakers. While several researchers have looked into predicting CS behaviour from a linguistic point of view, research is still lacking in the task of predicting user CS behaviour from sociological and psychological perspectives. We provide an empirical user study, where we investigate the correlations between users' CS levels and character traits. We conduct interviews with bilinguals and gather information on their profiles, including their demographics, personality traits, and traveling experiences. We then use machine learning (ML) to predict users' CS levels based on their profiles, where we identify the main influential factors in the modeling process. We experiment with both classification as well as regression tasks. Our results show that the CS behaviour is affected by the relation between speakers, travel experiences as well as Neuroticism and Extraversion personality traits.
Investigating Lexical Replacements for Arabic-English Code-Switched Data Augmentation
May 25, 2022
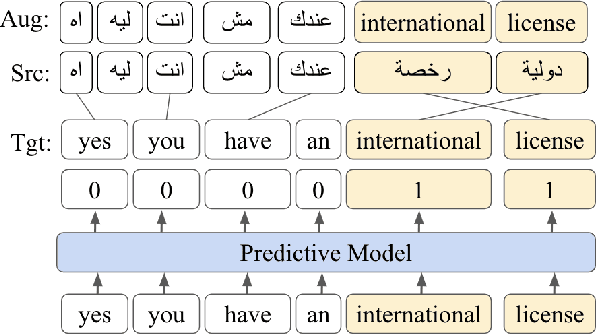

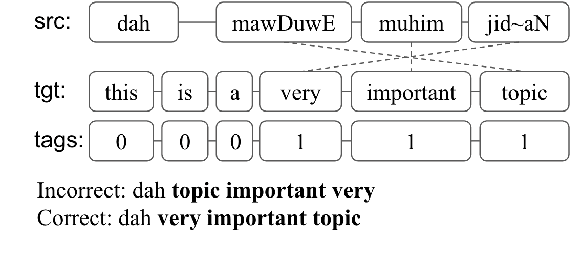
Code-switching (CS) poses several challenges to NLP tasks, where data sparsity is a main problem hindering the development of CS NLP systems. In this paper, we investigate data augmentation techniques for synthesizing Dialectal Arabic-English CS text. We perform lexical replacements using parallel corpora and alignments where CS points are either randomly chosen or learnt using a sequence-to-sequence model. We evaluate the effectiveness of data augmentation on language modeling (LM), machine translation (MT), and automatic speech recognition (ASR) tasks. Results show that in the case of using 1-1 alignments, using trained predictive models produces more natural CS sentences, as reflected in perplexity. By relying on grow-diag-final alignments, we then identify aligning segments and perform replacements accordingly. By replacing segments instead of words, the quality of synthesized data is greatly improved. With this improvement, random-based approach outperforms using trained predictive models on all extrinsic tasks. Our best models achieve 33.6% improvement in perplexity, +3.2-5.6 BLEU points on MT task, and 7% relative improvement on WER for ASR task. We also contribute in filling the gap in resources by collecting and publishing the first Arabic English CS-English parallel corpus.
Predicting User Code-Switching Level from Sociological and Psychological Profiles
Dec 13, 2021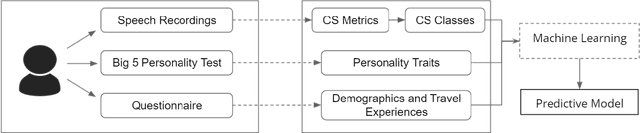
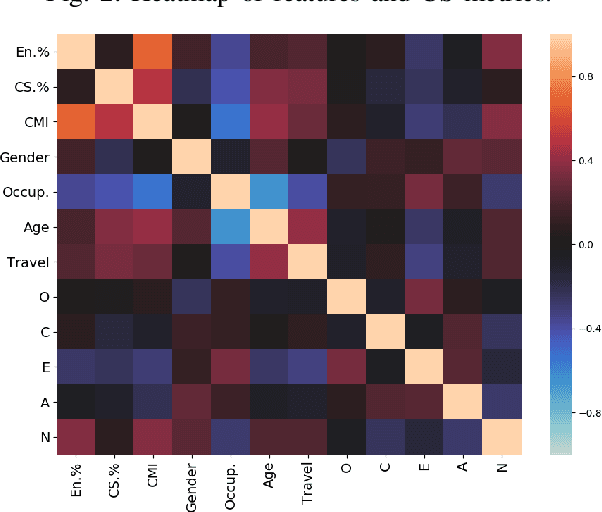
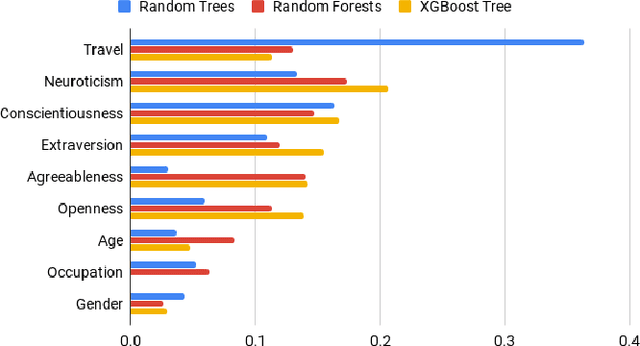
Multilingual speakers tend to alternate between languages within a conversation, a phenomenon referred to as "code-switching" (CS). CS is a complex phenomenon that not only encompasses linguistic challenges, but also contains a great deal of complexity in terms of its dynamic behaviour across speakers. This dynamic behaviour has been studied by sociologists and psychologists, identifying factors affecting CS. In this paper, we provide an empirical user study on Arabic-English CS, where we show the correlation between users' CS frequency and character traits. We use machine learning (ML) to validate the findings, informing and confirming existing theories. The predictive models were able to predict users' CS frequency with an accuracy higher than 55%, where travel experiences and personality traits played the biggest role in the modeling process.
Investigations on Speech Recognition Systems for Low-Resource Dialectal Arabic-English Code-Switching Speech
Aug 29, 2021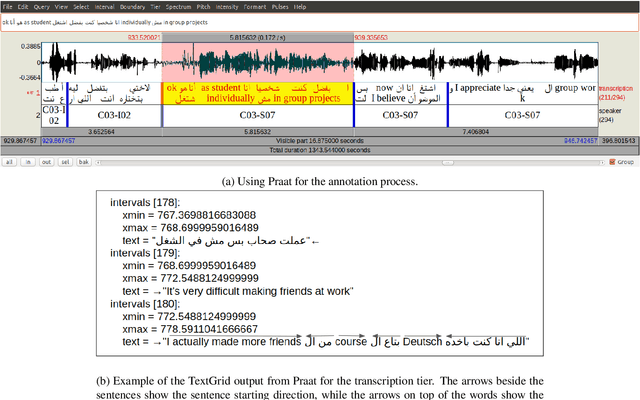
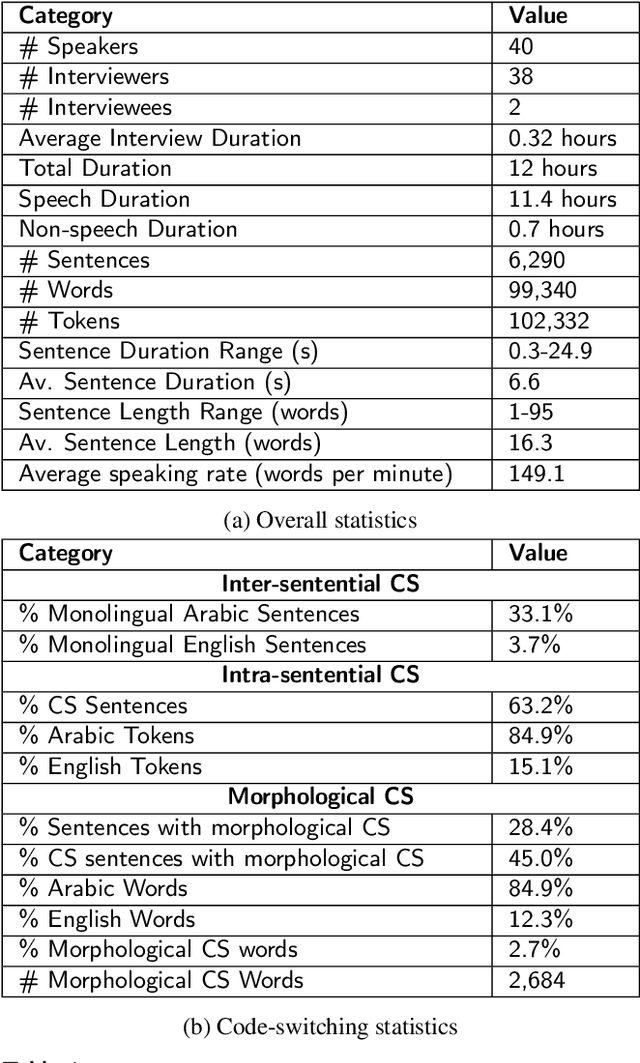
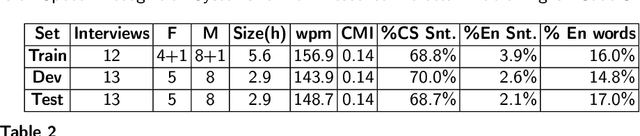
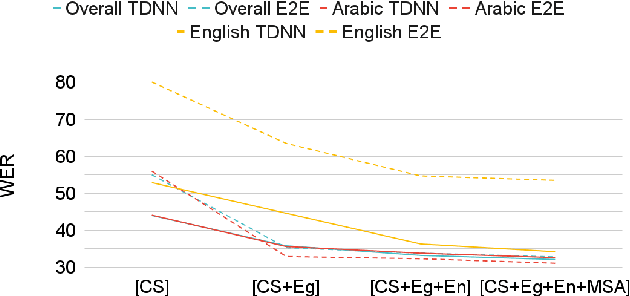
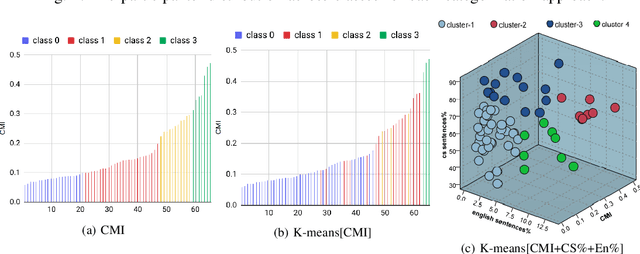
Code-switching (CS), defined as the mixing of languages in conversations, has become a worldwide phenomenon. The prevalence of CS has been recently met with a growing demand and interest to build CS ASR systems. In this paper, we present our work on code-switched Egyptian Arabic-English automatic speech recognition (ASR). We first contribute in filling the huge gap in resources by collecting, analyzing and publishing our spontaneous CS Egyptian Arabic-English speech corpus. We build our ASR systems using DNN-based hybrid and Transformer-based end-to-end models. In this paper, we present a thorough comparison between both approaches under the setting of a low-resource, orthographically unstandardized, and morphologically rich language pair. We show that while both systems give comparable overall recognition results, each system provides complementary sets of strength points. We show that recognition can be improved by combining the outputs of both systems. We propose several effective system combination approaches, where hypotheses of both systems are merged on sentence- and word-levels. Our approaches result in overall WER relative improvement of 4.7%, over a baseline performance of 32.1% WER. In the case of intra-sentential CS sentences, we achieve WER relative improvement of 4.8%. Our best performing system achieves 30.6% WER on ArzEn test set.
Code-switching Language Modeling With Bilingual Word Embeddings: A Case Study for Egyptian Arabic-English
Sep 24, 2019

Code-switching (CS) is a widespread phenomenon among bilingual and multilingual societies. The lack of CS resources hinders the performance of many NLP tasks. In this work, we explore the potential use of bilingual word embeddings for code-switching (CS) language modeling (LM) in the low resource Egyptian Arabic-English language. We evaluate different state-of-the-art bilingual word embeddings approaches that require cross-lingual resources at different levels and propose an innovative but simple approach that jointly learns bilingual word representations without the use of any parallel data, relying only on monolingual and a small amount of CS data. While all representations improve CS LM, ours performs the best and improves perplexity 33.5% relative over the baseline.
* 11 pages, 1 figure (having 2 sub-figures), submitted to the 21st International Conference on Speech and Computer (SPECOM'19),
A Visual Entity-Relationship Model for Constraint-Based University Timetabling
Sep 28, 2011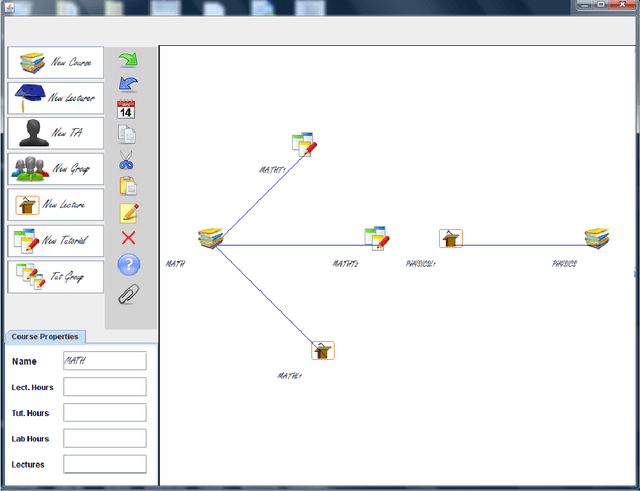

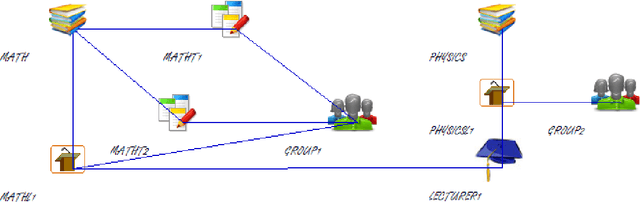
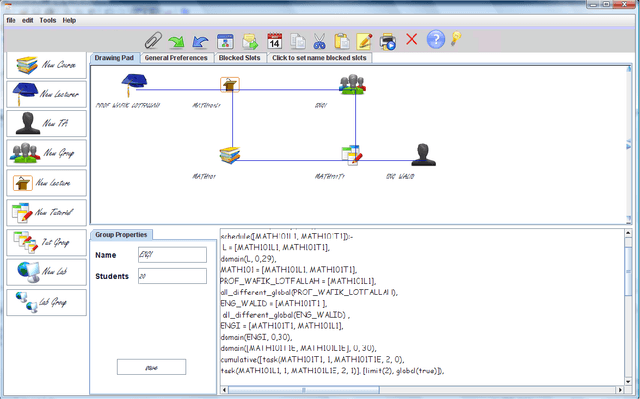
University timetabling (UTT) is a complex problem due to its combinatorial nature but also the type of constraints involved. The holy grail of (constraint) programming: "the user states the problem the program solves it" remains a challenge since solution quality is tightly coupled with deriving "effective models", best handled by technology experts. In this paper, focusing on the field of university timetabling, we introduce a visual graphic communication tool that lets the user specify her problem in an abstract manner, using a visual entity-relationship model. The entities are nodes of mainly two types: resource nodes (lecturers, assistants, student groups) and events nodes (lectures, lab sessions, tutorials). The links between the nodes signify a desired relationship between them. The visual modeling abstraction focuses on the nature of the entities and their relationships and abstracts from an actual constraint model.
The Munich Rent Advisor: A Success for Logic Programming on the Internet
Feb 10, 2004
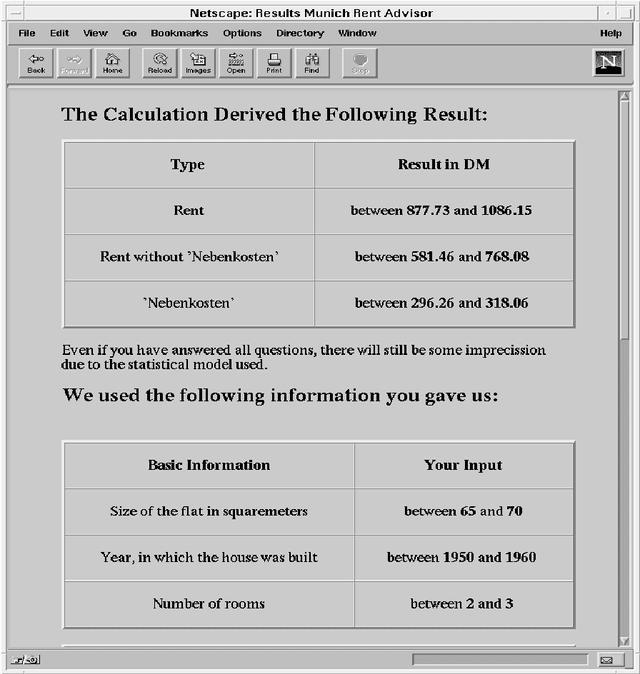
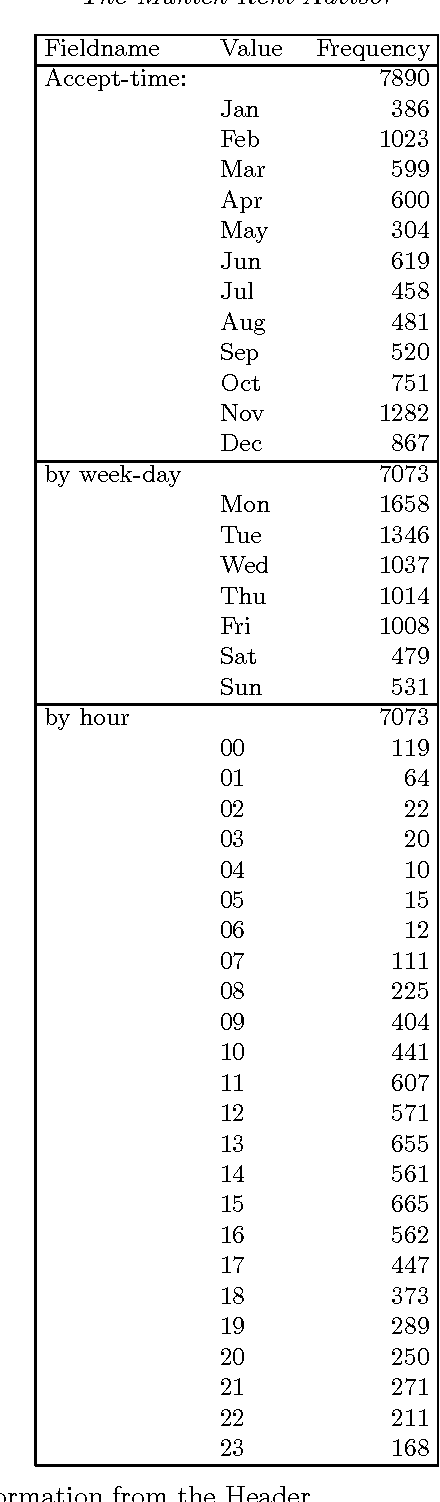
Most cities in Germany regularly publish a booklet called the {\em Mietspiegel}. It basically contains a verbal description of an expert system. It allows the calculation of the estimated fair rent for a flat. By hand, one may need a weekend to do so. With our computerized version, the {\em Munich Rent Advisor}, the user just fills in a form in a few minutes and the rent is calculated immediately. We also extended the functionality and applicability of the {\em Mietspiegel} so that the user need not answer all questions on the form. The key to computing with partial information using high-level programming was to use constraint logic programming. We rely on the internet, and more specifically the World Wide Web, to provide this service to a broad user group. More than ten thousand people have used our service in the last three years. This article describes the experiences in implementing and using the {\em Munich Rent Advisor}. Our results suggests that logic programming with constraints can be an important ingredient in intelligent internet systems.