 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Is this an example image?" -- Predicting the Relative Abstractness Level of Image and Text
Paper and Code
Jan 23, 2019
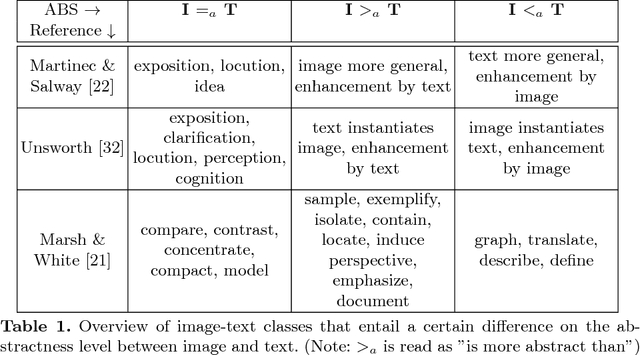

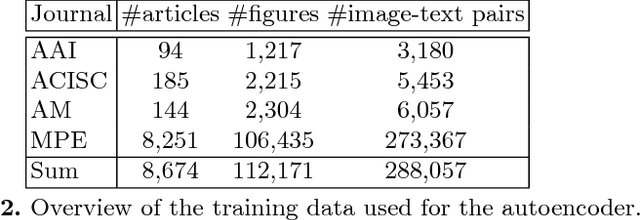
Successful multimodal search and retrieval requires the automatic understanding of semantic cross-modal relations, which, however, is still an open research problem. Previous work has suggested the metrics cross-modal mutual information and semantic correlation to model and predict cross-modal semantic relations of image and text. In this paper, we present an approach to predict the (cross-modal) relative abstractness level of a given image-text pair, that is whether the image is an abstraction of the text or vice versa. For this purpose, we introduce a new metric that captures this specific relationship between image and text at the Abstractness Level (ABS). We present a deep learning approach to predict this metric, which relies on an autoencoder architecture that allows us to significantly reduce the required amount of labeled training data. A comprehensive set of publicly available scientific documents has been gathered. Experimental results on a challenging test set demonstrate the feasibility of the approach.