 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Claims: A Dataset for Multimodal Claim Detection in Social Media
Paper and Code
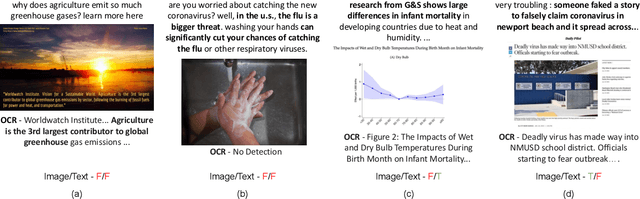
In recent years, the problem of misinformation on the web has become widespread across languages, countries, and various social media platforms. Although there has been much work on automated fake news detection, the role of images and their variety are not well explored. In this paper, we investigate the roles of image and text at an earlier stage of the fake news detection pipeline, called claim detection. For this purpose, we introduce a novel dataset, MM-Claims, which consists of tweets and corresponding images over three topics: COVID-19, Climate Change and broadly Technology. The dataset contains roughly 86000 tweets, out of which 3400 are labeled manually by multiple annotators for the training and evaluation of multimodal models. We describe the dataset in detail, evaluate strong unimodal and multimodal baselines, and analyze the potential and drawbacks of current models.