 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Low and High-level Feature Analysis for Early Rumor Detection on Twitter
Sep 07, 2018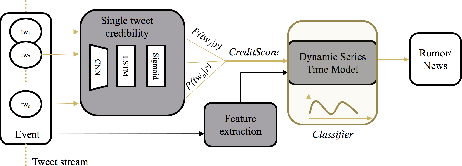

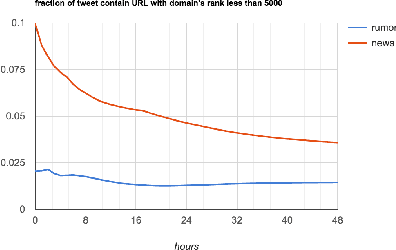

Recent work have done a good job in modeling rumors and detecting them over microblog streams. However, the performance of their automatic approaches are not relatively high when looking early in the diffusion. A first intuition is that, at early stage, most of the aggregated rumor features (e.g., propagation features) are not mature and distinctive enough. The objective of rumor debunking in microblogs, however, are to detect these misinformation as early as possible. In this work, we leverage neural models in learning the hidden representations of individual rumor-related tweets at the very beginning of a rumor. Our extensive experiments show that the resulting signal improves our classification performance over time, significantly within the first 10 hours. To deepen the understanding of these low and high-level features in contributing to the model performance over time, we conduct an extensive study on a wide range of high impact rumor features for the 48 hours range. The end model that engages these features are shown to be competitive, reaches over 90% accuracy and out-performs strong baselines in our carefully cured dataset.
On the Predictability of non-CGM Diabetes Data for Personalized Recommendation
Sep 07, 2018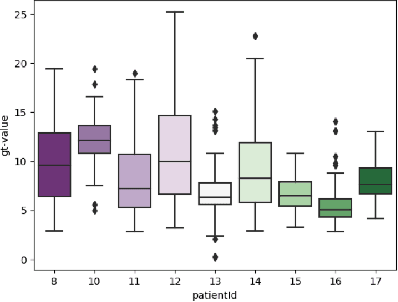
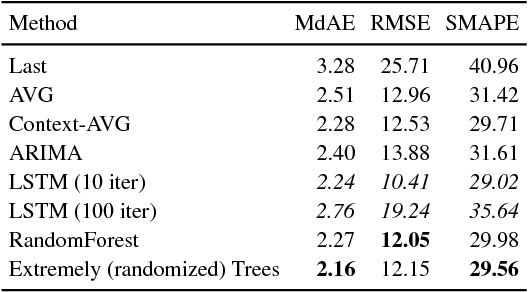
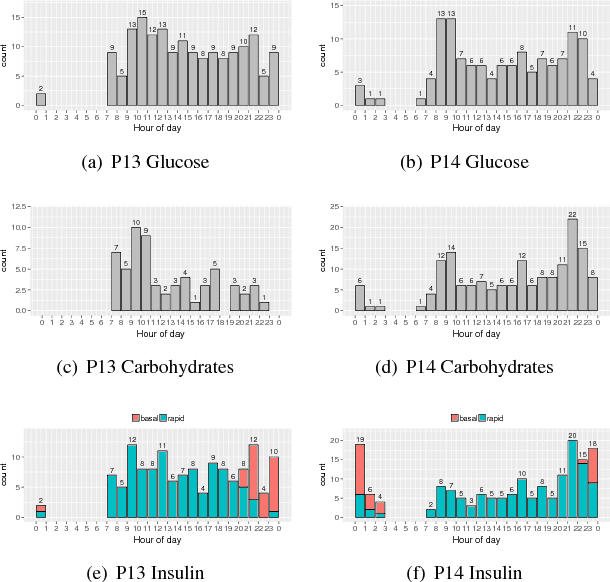
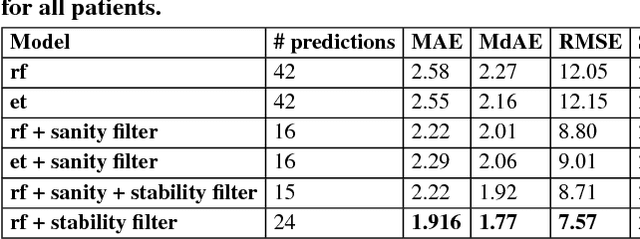
With continuous glucose monitoring (CGM), data-driven models on blood glucose prediction have been shown to be effective in related work. However, such (CGM) systems are not always available, e.g., for a patient at home. In this work, we conduct a study on 9 patients and examine the predictability of data-driven (aka. machine learning) based models on patient-level blood glucose prediction; with measurements are taken only periodically (i.e., after several hours). To this end, we propose several post-prediction methods to account for the noise nature of these data, that marginally improves the performance of the end system.
A Trio Neural Model for Dynamic Entity Relatedness Ranking
Sep 07, 2018



Measuring entity relatedness is a fundamental task for many natural language processing and information retrieval applications. Prior work often studies entity relatedness in static settings and an unsupervised manner. However, entities in real-world are often involved in many different relationships, consequently entity-relations are very dynamic over time. In this work, we propose a neural networkbased approach for dynamic entity relatedness, leveraging the collective attention as supervision. Our model is capable of learning rich and different entity representations in a joint framework. Through extensive experiments on large-scale datasets, we demonstrate that our method achieves better results than competitive baselines.
Multiple Models for Recommending Temporal Aspects of Entities
Jun 03, 2018
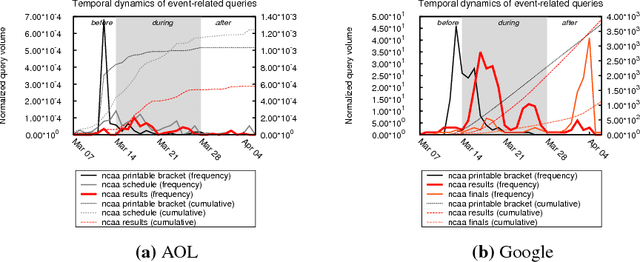

Entity aspect recommendation is an emerging task in semantic search that helps users discover serendipitous and prominent information with respect to an entity, of which salience (e.g., popularity) is the most important factor in previous work. However, entity aspects are temporally dynamic and often driven by events happening over time. For such cases, aspect suggestion based solely on salience features can give unsatisfactory results, for two reasons. First, salience is often accumulated over a long time period and does not account for recency. Second, many aspects related to an event entity are strongly time-dependent. In this paper, we study the task of temporal aspect recommendation for a given entity, which aims at recommending the most relevant aspects and takes into account time in order to improve search experience. We propose a novel event-centric ensemble ranking method that learns from multiple time and type-dependent models and dynamically trades off salience and recency characteristics. Through extensive experiments on real-world query logs, we demonstrate that our method is robust and achieves better effectiveness than competitive baselines.
On Early-stage Debunking Rumors on Twitter: Leveraging the Wisdom of Weak Learners
Sep 13, 2017



Recently a lot of progress has been made in rumor modeling and rumor detection for micro-blogging streams. However, existing automated methods do not perform very well for early rumor detection, which is crucial in many settings, e.g., in crisis situations. One reason for this is that aggregated rumor features such as propagation features, which work well on the long run, are - due to their accumulating characteristic - not very helpful in the early phase of a rumor. In this work, we present an approach for early rumor detection, which leverages Convolutional Neural Networks for learning the hidden representations of individual rumor-related tweets to gain insights on the credibility of each tweets. We then aggregate the predictions from the very beginning of a rumor to obtain the overall event credits (so-called wisdom), and finally combine it with a time series based rumor classification model. Our extensive experiments show a clearly improved classification performance within the critical very first hours of a rumor. For a better understanding, we also conduct an extensive feature evaluation that emphasized on the early stage and shows that the low-level credibility has best predictability at all phases of the rumor lifetime.
Hedera: Scalable Indexing and Exploring Entities in Wikipedia Revision History
Jan 14, 2017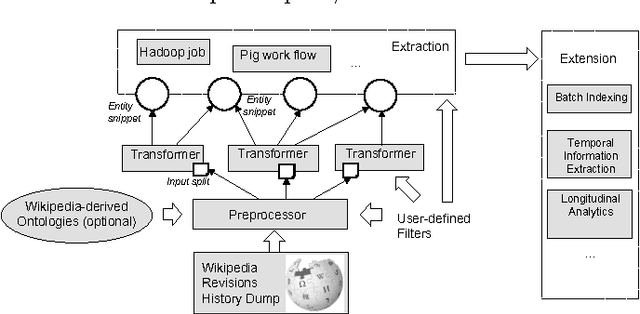
Much of work in semantic web relying on Wikipedia as the main source of knowledge often work on static snapshots of the dataset. The full history of Wikipedia revisions, while contains much more useful information, is still difficult to access due to its exceptional volume. To enable further research on this collection, we developed a tool, named Hedera, that efficiently extracts semantic information from Wikipedia revision history datasets. Hedera exploits Map-Reduce paradigm to achieve rapid extraction, it is able to handle one entire Wikipedia articles revision history within a day in a medium-scale cluster, and supports flexible data structures for various kinds of semantic web study.