 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMigration Reframed? A multilingual analysis on the stance shift in Europe during the Ukrainian crisis
Feb 06, 2023The war in Ukraine seems to have positively changed the attitude toward the critical societal topic of migration in Europe -- at least towards refugees from Ukraine. We investigate whether this impression is substantiated by how the topic is reflected in online news and social media, thus linking the representation of the issue on the Web to its perception in society. For this purpose, we combine and adapt leading-edge automatic text processing for a novel multilingual stance detection approach. Starting from 5.5M Twitter posts published by 565 European news outlets in one year, beginning September 2021, plus replies, we perform a multilingual analysis of migration-related media coverage and associated social media interaction for Europe and selected European countries. The results of our analysis show that there is actually a reframing of the discussion illustrated by the terminology change, e.g., from "migrant" to "refugee", often even accentuated with phrases such as "real refugees". However, concerning a stance shift in public perception, the picture is more diverse than expected. All analyzed cases show a noticeable temporal stance shift around the start of the war in Ukraine. Still, there are apparent national differences in the size and stability of this shift.
Developing an AI-enabled IIoT platform -- Lessons learned from early use case validation
Jul 10, 2022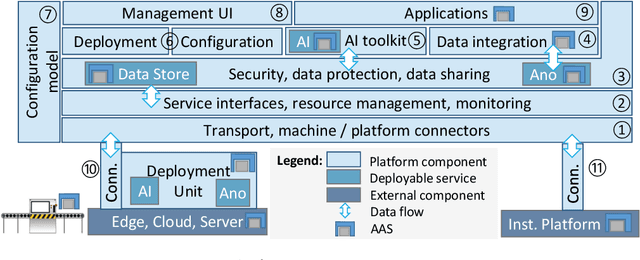
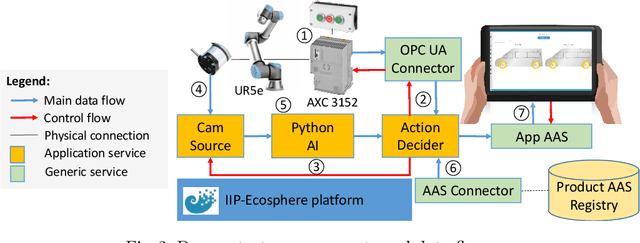


For a broader adoption of AI in industrial production, adequate infrastructure capabilities are crucial. This includes easing the integration of AI with industrial devices, support for distributed deployment, monitoring, and consistent system configuration. Existing IIoT platforms still lack required capabilities to flexibly integrate reusable AI services and relevant standards such as Asset Administration Shells or OPC UA in an open, ecosystem-based manner. This is exactly what our next level Intelligent Industrial Production Ecosphere (IIP-Ecosphere) platform addresses, employing a highly configurable low-code based approach. In this paper, we introduce the design of this platform and discuss an early evaluation in terms of a demonstrator for AI-enabled visual quality inspection. This is complemented by insights and lessons learned during this early evaluation activity.
On the Feasibility of Predicting Questions being Forgotten in Stack Overflow
Oct 29, 2021
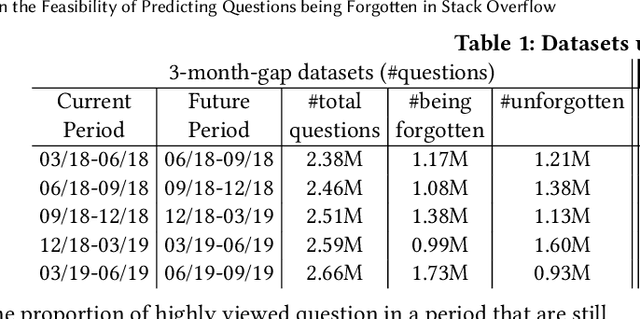
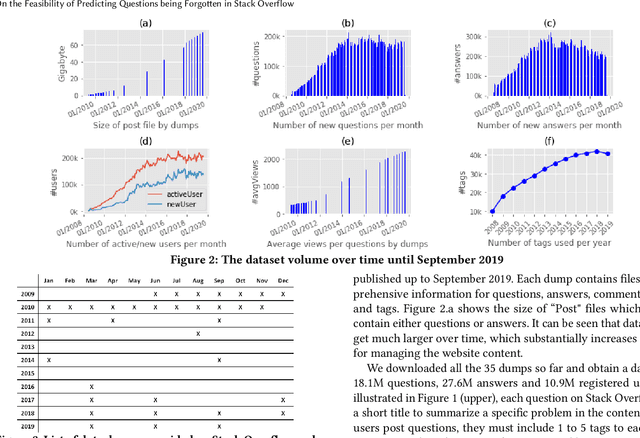

For their attractiveness, comprehensiveness and dynamic coverage of relevant topics, community-based question answering sites such as Stack Overflow heavily rely on the engagement of their communities: Questions on new technologies, technology features as well as technology versions come up and have to be answered as technology evolves (and as community members gather experience with it). At the same time, other questions cease in importance over time, finally becoming irrelevant to users. Beyond filtering low-quality questions, "forgetting" questions, which have become redundant, is an important step for keeping the Stack Overflow content concise and useful. In this work, we study this managed forgetting task for Stack Overflow. Our work is based on data from more than a decade (2008 - 2019) - covering 18.1M questions, that are made publicly available by the site itself. For establishing a deeper understanding, we first analyze and characterize the set of questions about to be forgotten, i.e., questions that get a considerable number of views in the current period but become unattractive in the near future. Subsequently, we examine the capability of a wide range of features in predicting such forgotten questions in different categories. We find some categories in which those questions are more predictable. We also discover that the text-based features are surprisingly not helpful in this prediction task, while the meta information is much more predictive.
Temporarily Unavailable: Memory Inhibition in Cognitive and Computer Science
Nov 15, 2019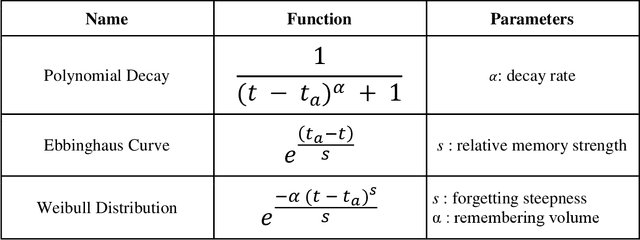
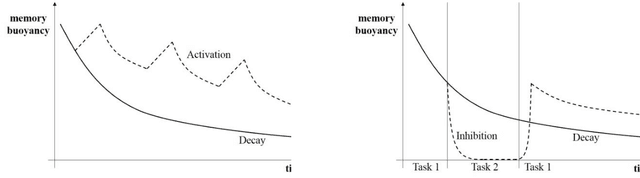
Inhibition is one of the core concepts in Cognitive Psychology. The idea of inhibitory mechanisms actively weakening representations in the human mind has inspired a great number of studies in various research domains. In contrast, Computer Science only recently has begun to consider inhibition as a second basic processing quality beside activation. Here, we review psychological research on inhibition in memory and link the gained insights with the current efforts in Computer Science of incorporating inhibitory principles for optimizing information retrieval in Personal Information Management. Four common aspects guide this review in both domains: 1. The purpose of inhibition to increase processing efficiency. 2. Its relation to activation. 3. Its links to contexts. 4. Its temporariness. In summary, the concept of inhibition has been used by Computer Science for enhancing software in various ways already. Yet, we also identify areas for promising future developments of inhibitory mechanisms, particularly context inhibition.
* 46 pages, 5 figures, preprint, final version published in IWC
Managed Forgetting to Support Information Management and Knowledge Work
Nov 17, 2018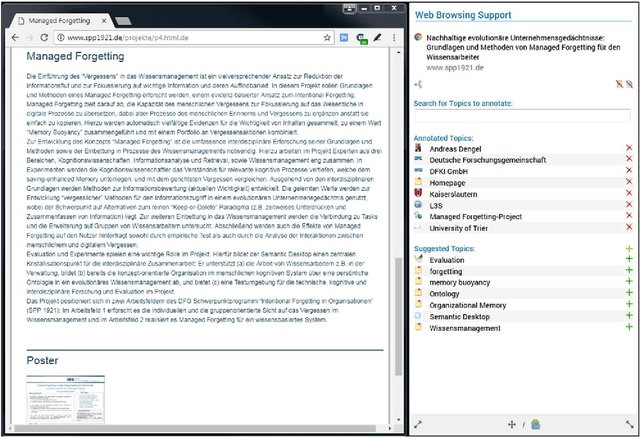
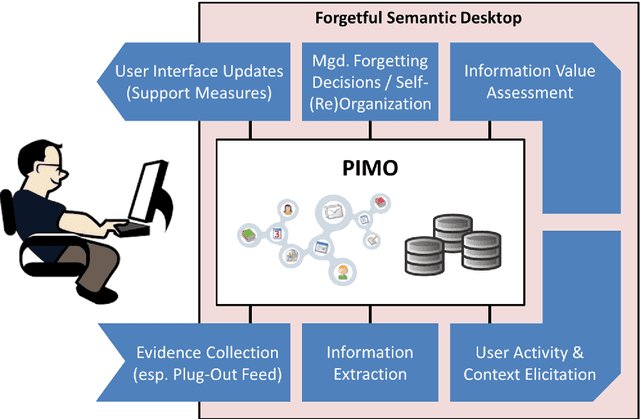
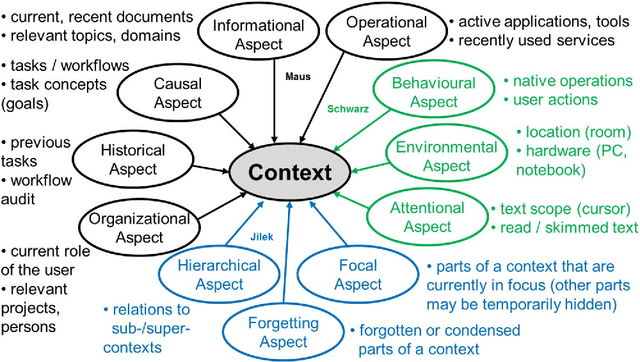
Trends like digital transformation even intensify the already overwhelming mass of information knowledge workers face in their daily life. To counter this, we have been investigating knowledge work and information management support measures inspired by human forgetting. In this paper, we give an overview of solutions we have found during the last five years as well as challenges that still need to be tackled. Additionally, we share experiences gained with the prototype of a first forgetful information system used 24/7 in our daily work for the last three years. We also address the untapped potential of more explicated user context as well as features inspired by Memory Inhibition, which is our current focus of research.
On Early-stage Debunking Rumors on Twitter: Leveraging the Wisdom of Weak Learners
Sep 13, 2017



Recently a lot of progress has been made in rumor modeling and rumor detection for micro-blogging streams. However, existing automated methods do not perform very well for early rumor detection, which is crucial in many settings, e.g., in crisis situations. One reason for this is that aggregated rumor features such as propagation features, which work well on the long run, are - due to their accumulating characteristic - not very helpful in the early phase of a rumor. In this work, we present an approach for early rumor detection, which leverages Convolutional Neural Networks for learning the hidden representations of individual rumor-related tweets to gain insights on the credibility of each tweets. We then aggregate the predictions from the very beginning of a rumor to obtain the overall event credits (so-called wisdom), and finally combine it with a time series based rumor classification model. Our extensive experiments show a clearly improved classification performance within the critical very first hours of a rumor. For a better understanding, we also conduct an extensive feature evaluation that emphasized on the early stage and shows that the low-level credibility has best predictability at all phases of the rumor lifetime.
Balancing Novelty and Salience: Adaptive Learning to Rank Entities for Timeline Summarization of High-impact Events
Jan 14, 2017



Long-running, high-impact events such as the Boston Marathon bombing often develop through many stages and involve a large number of entities in their unfolding. Timeline summarization of an event by key sentences eases story digestion, but does not distinguish between what a user remembers and what she might want to re-check. In this work, we present a novel approach for timeline summarization of high-impact events, which uses entities instead of sentences for summarizing the event at each individual point in time. Such entity summaries can serve as both (1) important memory cues in a retrospective event consideration and (2) pointers for personalized event exploration. In order to automatically create such summaries, it is crucial to identify the "right" entities for inclusion. We propose to learn a ranking function for entities, with a dynamically adapted trade-off between the in-document salience of entities and the informativeness of entities across documents, i.e., the level of new information associated with an entity for a time point under consideration. Furthermore, for capturing collective attention for an entity we use an innovative soft labeling approach based on Wikipedia. Our experiments on a real large news datasets confirm the effectiveness of the proposed methods.