 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceView: Interactive Visualization of Agentic Program Repair Trajectories
Jun 20, 2026LLM-based automated program repair (APR) agents generate patches to fix software bugs with minimal human intervention. These agents often produce long trajectories of reasoning, tool use, and feedback to produce candidate patches. Final patch outcomes show whether a repair attempt succeeded or failed, but they do not show how the agent reached that outcome, or where the process became repetitive or misaligned with the task. This makes agentic repair failures difficult to diagnose, reproduce, and prevent. To help developers address these challenges, we present TraceView, an interactive tool for labeling and visualizing repair trajectories from APR systems. TraceView organizes raw and pre-labeled agentic runs with Thought, Action, and Result components to support semantic relation labeling and diagnosis, and renders the resulting trajectory as graph views. Furthermore, TraceView provides relation filters, patch outcome summaries, metrics, and node-level evidence panels to help users inspect how reasoning, actions, and feedback connect across the various steps of an agentic repair attempt. We evaluate TraceView with five researchers through a survey-based user study. Participants reported that TraceView made trajectories easier to scan and that its overview-to-detail workflow helped them better understand repair behavior. The TraceView source code is available at https://github.com/SOAR-Lab/agent-traj-visualization. A screencast of TraceView is available at https://youtu.be/9ZCh7Ifj2AQ.
The Model Knows, the Decoder Finds: Future Value Guided Particle Power Sampling
May 04, 2026A recurring pattern in "reasoning without training" is that base LLMs already assign non-trivial probability mass to correct multi-step solutions; the bottleneck is locating these modes efficiently at inference time. Power sampling provides a principled way to bias decoding toward such modes by targeting p_theta(x)^alpha with alpha > 1, but practical approximations must account for future-dependent correction factors that determine which prefixes remain promising. We introduce Auxiliary Particle Power Sampling (APPS), a blockwise particle algorithm for approximating the sequence-level power target with a bounded population of partial solutions. APPS propagates hypotheses in parallel using proposal-corrected power reweighting and refines their survival through future-value-guided selection at resampling boundaries. This redistributes finite compute across competing prefixes rather than committing to a single unfolding path, while providing a direct scaling knob in the particle count and predictable peak memory. We instantiate the future-value signal with short-horizon rollouts and also study an amortized variant that replaces rollouts with a lightweight learned selection head. Across reasoning benchmarks, APPS improves the accuracy-runtime trade-off of training-free decoding and suggests that part of the gap to post-trained systems can be recovered through more faithful inference-time power approximation.
AXE: An Agentic eXploit Engine for Confirming Zero-Day Vulnerability Reports
Feb 15, 2026Vulnerability detection tools are widely adopted in software projects, yet they often overwhelm maintainers with false positives and non-actionable reports. Automated exploitation systems can help validate these reports; however, existing approaches typically operate in isolation from detection pipelines, failing to leverage readily available metadata such as vulnerability type and source-code location. In this paper, we investigate how reported security vulnerabilities can be assessed in a realistic grey-box exploitation setting that leverages minimal vulnerability metadata, specifically a CWE classification and a vulnerable code location. We introduce Agentic eXploit Engine (AXE), a multi-agent framework for Web application exploitation that maps lightweight detection metadata to concrete exploits through decoupled planning, code exploration, and dynamic execution feedback. Evaluated on the CVE-Bench dataset, AXE achieves a 30% exploitation success rate, a 3x improvement over state-of-the-art black-box baselines. Even in a single-agent configuration, grey-box metadata yields a 1.75x performance gain. Systematic error analysis shows that most failed attempts arise from specific reasoning gaps, including misinterpreted vulnerability semantics and unmet execution preconditions. For successful exploits, AXE produces actionable, reproducible proof-of-concept artifacts, demonstrating its utility in streamlining Web vulnerability triage and remediation. We further evaluate AXE's generalizability through a case study on a recent real-world vulnerability not included in CVE-Bench.
Tree-OPO: Off-policy Monte Carlo Tree-Guided Advantage Optimization for Multistep Reasoning
Sep 11, 2025
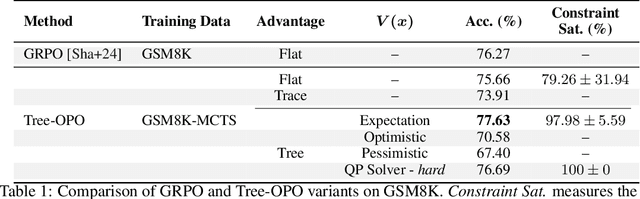


Recent advances in reasoning with large language models (LLMs) have shown the effectiveness of Monte Carlo Tree Search (MCTS) for generating high-quality intermediate trajectories, particularly in math and symbolic domains. Inspired by this, we explore how MCTS-derived trajectories, traditionally used for training value or reward models, can be repurposed to improve policy optimization in preference-based reinforcement learning (RL). Specifically, we focus on Group Relative Policy Optimization (GRPO), a recent algorithm that enables preference-consistent policy learning without value networks. We propose a staged GRPO training paradigm where completions are derived from partially revealed MCTS rollouts, introducing a novel tree-structured setting for advantage estimation. This leads to a rich class of prefix-conditioned reward signals, which we analyze theoretically and empirically. Our initial results indicate that while structured advantage estimation can stabilize updates and better reflect compositional reasoning quality, challenges such as advantage saturation and reward signal collapse remain. We propose heuristic and statistical solutions to mitigate these issues and discuss open challenges for learning under staged or tree-like reward structures.
Noise Contrastive Estimation-based Matching Framework for Low-Resource Security Attack Pattern Recognition
Jan 30, 2024
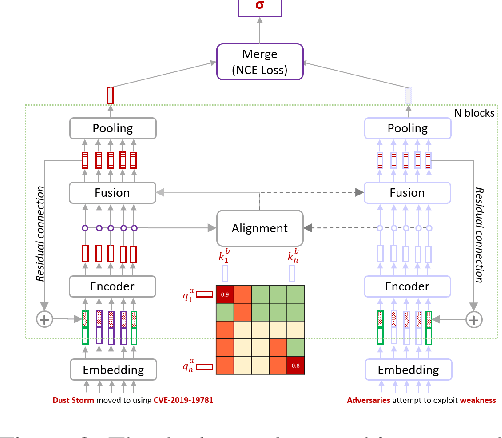
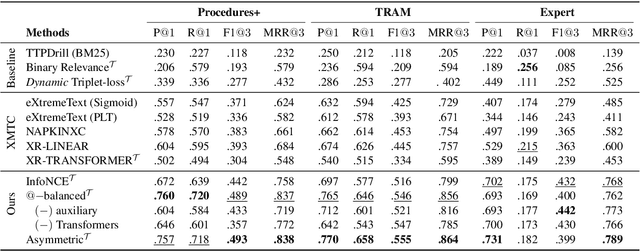
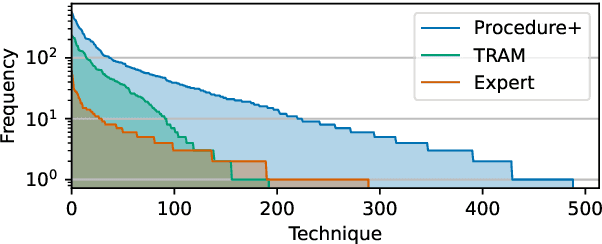
Tactics, Techniques and Procedures (TTPs) represent sophisticated attack patterns in the cybersecurity domain, described encyclopedically in textual knowledge bases. Identifying TTPs in cybersecurity writing, often called TTP mapping, is an important and challenging task. Conventional learning approaches often target the problem in the classical multi-class or multilabel classification setting. This setting hinders the learning ability of the model due to a large number of classes (i.e., TTPs), the inevitable skewness of the label distribution and the complex hierarchical structure of the label space. We formulate the problem in a different learning paradigm, where the assignment of a text to a TTP label is decided by the direct semantic similarity between the two, thus reducing the complexity of competing solely over the large labeling space. To that end, we propose a neural matching architecture with an effective sampling-based learn-to-compare mechanism, facilitating the learning process of the matching model despite constrained resources.
Enabling hand gesture customization on wrist-worn devices
Mar 29, 2022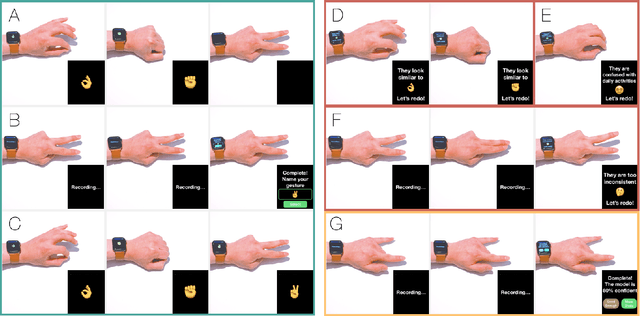
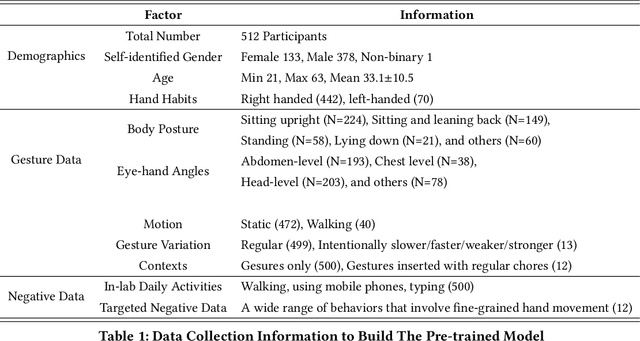
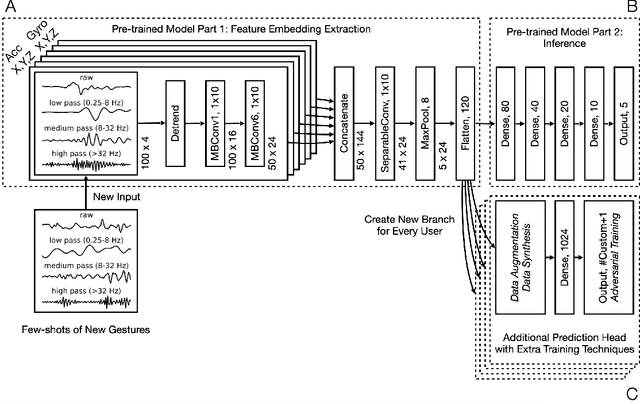
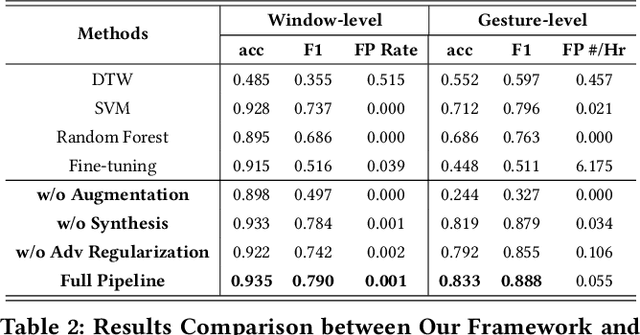
We present a framework for gesture customization requiring minimal examples from users, all without degrading the performance of existing gesture sets. To achieve this, we first deployed a large-scale study (N=500+) to collect data and train an accelerometer-gyroscope recognition model with a cross-user accuracy of 95.7% and a false-positive rate of 0.6 per hour when tested on everyday non-gesture data. Next, we design a few-shot learning framework which derives a lightweight model from our pre-trained model, enabling knowledge transfer without performance degradation. We validate our approach through a user study (N=20) examining on-device customization from 12 new gestures, resulting in an average accuracy of 55.3%, 83.1%, and 87.2% on using one, three, or five shots when adding a new gesture, while maintaining the same recognition accuracy and false-positive rate from the pre-existing gesture set. We further evaluate the usability of our real-time implementation with a user experience study (N=20). Our results highlight the effectiveness, learnability, and usability of our customization framework. Our approach paves the way for a future where users are no longer bound to pre-existing gestures, freeing them to creatively introduce new gestures tailored to their preferences and abilities.
On the Feasibility of Predicting Questions being Forgotten in Stack Overflow
Oct 29, 2021
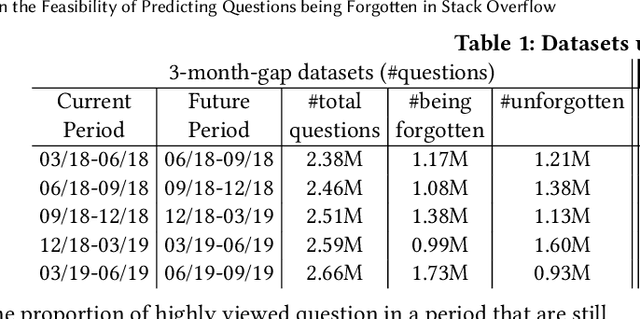
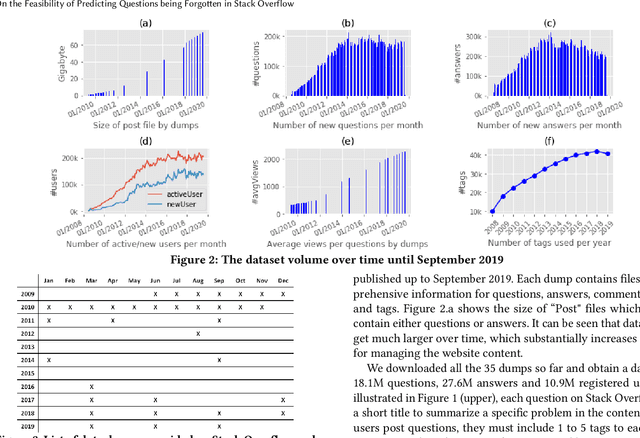

For their attractiveness, comprehensiveness and dynamic coverage of relevant topics, community-based question answering sites such as Stack Overflow heavily rely on the engagement of their communities: Questions on new technologies, technology features as well as technology versions come up and have to be answered as technology evolves (and as community members gather experience with it). At the same time, other questions cease in importance over time, finally becoming irrelevant to users. Beyond filtering low-quality questions, "forgetting" questions, which have become redundant, is an important step for keeping the Stack Overflow content concise and useful. In this work, we study this managed forgetting task for Stack Overflow. Our work is based on data from more than a decade (2008 - 2019) - covering 18.1M questions, that are made publicly available by the site itself. For establishing a deeper understanding, we first analyze and characterize the set of questions about to be forgotten, i.e., questions that get a considerable number of views in the current period but become unattractive in the near future. Subsequently, we examine the capability of a wide range of features in predicting such forgotten questions in different categories. We find some categories in which those questions are more predictable. We also discover that the text-based features are surprisingly not helpful in this prediction task, while the meta information is much more predictive.
Spatiotemporal Tile-based Attention-guided LSTMs for Traffic Video Prediction
Oct 27, 2019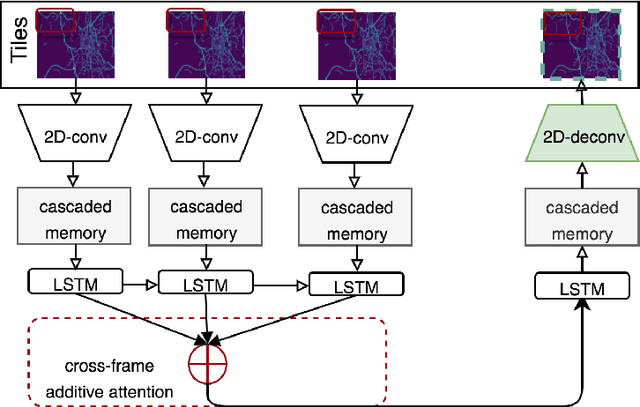
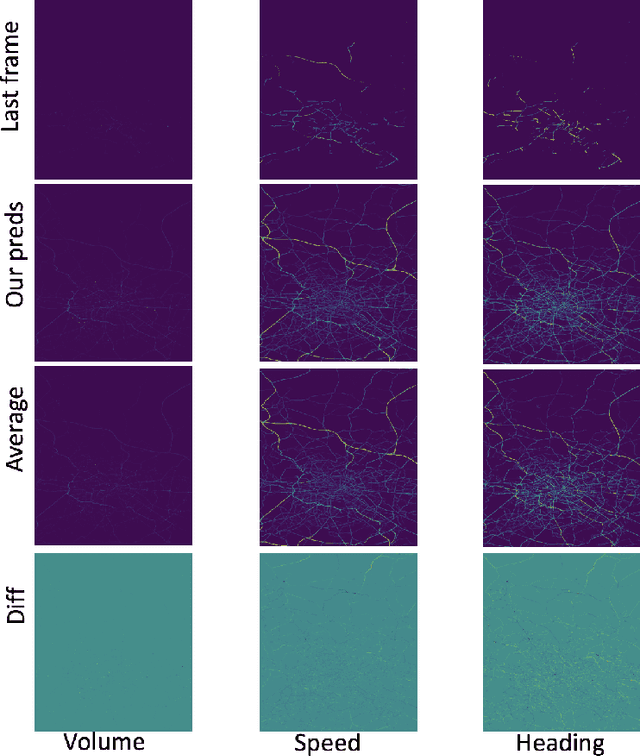
This extended abstract describes our solution for the Traffic4Cast Challenge 2019. The key problem we addressed is to properly model both low-level (pixel based) and high-level spatial information while still preserve the temporal relations among the frames. Our approach is inspired by the recent adoption of convolutional features into a recurrent neural networks such as LSTM to jointly capture the spatio-temporal dependency. While this approach has been proven to surpass the traditional stacked CNNs (using 2D or 3D kernels) in action recognition, we observe suboptimal performance in traffic prediction setting. Therefore, we apply a number of adaptations in the frame encoder-decoder layers and in sampling procedure to better capture the high-resolution trajectories, and to increase the training efficiency.