 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Tile-based Attention-guided LSTMs for Traffic Video Prediction
Paper and Code
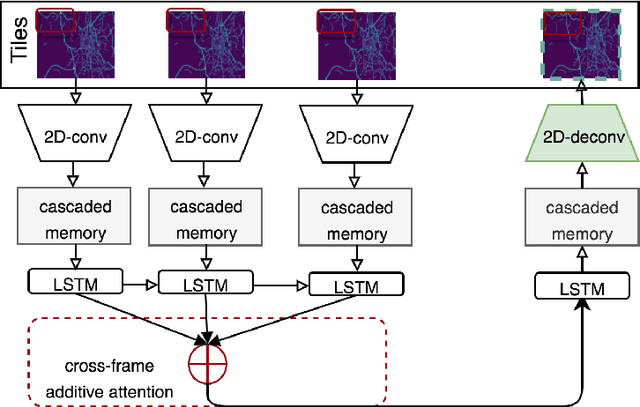
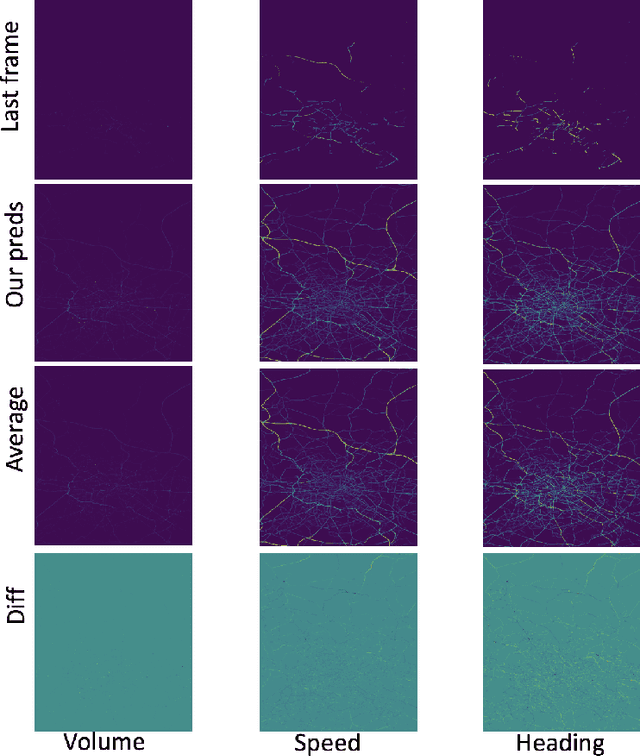
This extended abstract describes our solution for the Traffic4Cast Challenge 2019. The key problem we addressed is to properly model both low-level (pixel based) and high-level spatial information while still preserve the temporal relations among the frames. Our approach is inspired by the recent adoption of convolutional features into a recurrent neural networks such as LSTM to jointly capture the spatio-temporal dependency. While this approach has been proven to surpass the traditional stacked CNNs (using 2D or 3D kernels) in action recognition, we observe suboptimal performance in traffic prediction setting. Therefore, we apply a number of adaptations in the frame encoder-decoder layers and in sampling procedure to better capture the high-resolution trajectories, and to increase the training efficiency.