 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Enabling hand gesture customization on wrist-worn devices
Mar 29, 2022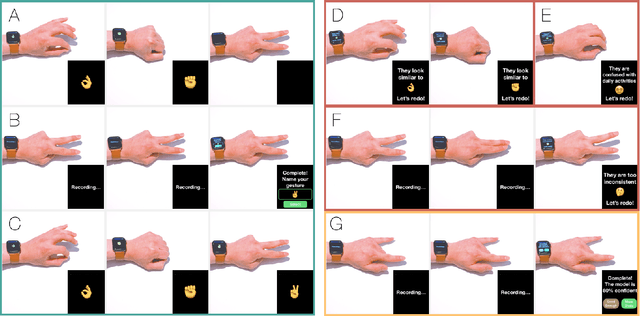
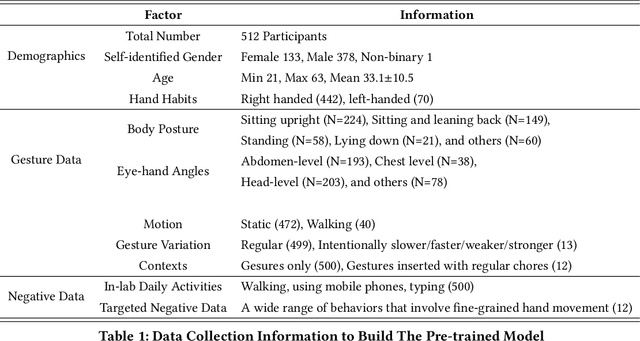
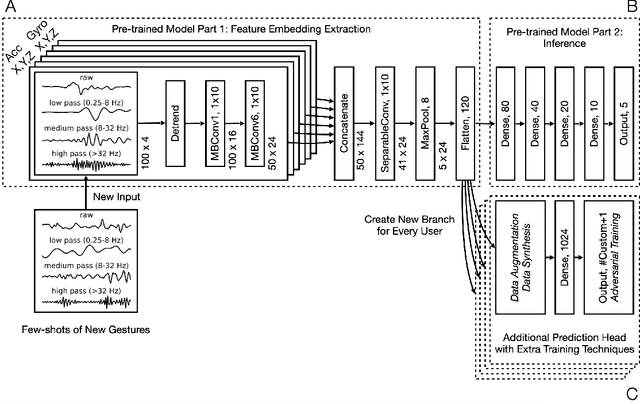
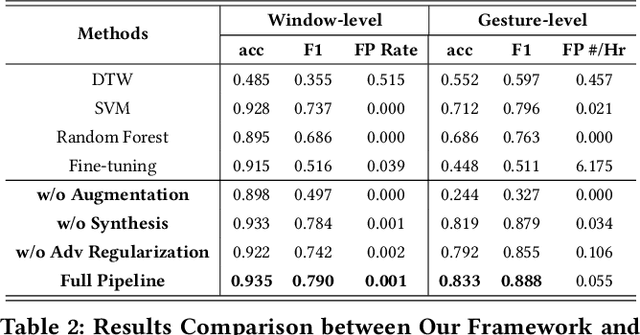
We present a framework for gesture customization requiring minimal examples from users, all without degrading the performance of existing gesture sets. To achieve this, we first deployed a large-scale study (N=500+) to collect data and train an accelerometer-gyroscope recognition model with a cross-user accuracy of 95.7% and a false-positive rate of 0.6 per hour when tested on everyday non-gesture data. Next, we design a few-shot learning framework which derives a lightweight model from our pre-trained model, enabling knowledge transfer without performance degradation. We validate our approach through a user study (N=20) examining on-device customization from 12 new gestures, resulting in an average accuracy of 55.3%, 83.1%, and 87.2% on using one, three, or five shots when adding a new gesture, while maintaining the same recognition accuracy and false-positive rate from the pre-existing gesture set. We further evaluate the usability of our real-time implementation with a user experience study (N=20). Our results highlight the effectiveness, learnability, and usability of our customization framework. Our approach paves the way for a future where users are no longer bound to pre-existing gestures, freeing them to creatively introduce new gestures tailored to their preferences and abilities.