 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Pareto-optimal Utility-Fairness between Groups in Repeated Rankings
Feb 22, 2024



In this paper, we tackle the problem of computing a sequence of rankings with the guarantee of the Pareto-optimal balance between (1) maximizing the utility of the consumers and (2) minimizing unfairness between producers of the items. Such a multi-objective optimization problem is typically solved using a combination of a scalarization method and linear programming on bi-stochastic matrices, representing the distribution of possible rankings of items. However, the above-mentioned approach relies on Birkhoff-von Neumann (BvN) decomposition, of which the computational complexity is $\mathcal{O}(n^5)$ with $n$ being the number of items, making it impractical for large-scale systems. To address this drawback, we introduce a novel approach to the above problem by using the Expohedron - a permutahedron whose points represent all achievable exposures of items. On the Expohedron, we profile the Pareto curve which captures the trade-off between group fairness and user utility by identifying a finite number of Pareto optimal solutions. We further propose an efficient method by relaxing our optimization problem on the Expohedron's circumscribed $n$-sphere, which significantly improve the running time. Moreover, the approximate Pareto curve is asymptotically close to the real Pareto optimal curve as the number of substantial solutions increases. Our methods are applicable with different ranking merits that are non-decreasing functions of item relevance. The effectiveness of our methods are validated through experiments on both synthetic and real-world datasets.
On the Feasibility of Predicting Questions being Forgotten in Stack Overflow
Oct 29, 2021
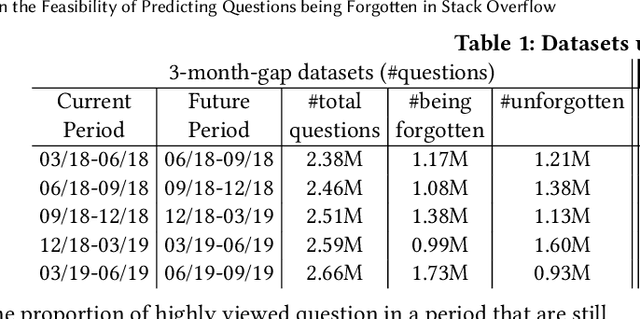
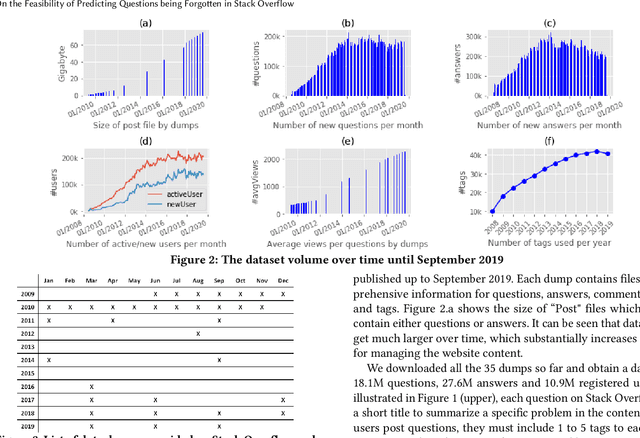

For their attractiveness, comprehensiveness and dynamic coverage of relevant topics, community-based question answering sites such as Stack Overflow heavily rely on the engagement of their communities: Questions on new technologies, technology features as well as technology versions come up and have to be answered as technology evolves (and as community members gather experience with it). At the same time, other questions cease in importance over time, finally becoming irrelevant to users. Beyond filtering low-quality questions, "forgetting" questions, which have become redundant, is an important step for keeping the Stack Overflow content concise and useful. In this work, we study this managed forgetting task for Stack Overflow. Our work is based on data from more than a decade (2008 - 2019) - covering 18.1M questions, that are made publicly available by the site itself. For establishing a deeper understanding, we first analyze and characterize the set of questions about to be forgotten, i.e., questions that get a considerable number of views in the current period but become unattractive in the near future. Subsequently, we examine the capability of a wide range of features in predicting such forgotten questions in different categories. We find some categories in which those questions are more predictable. We also discover that the text-based features are surprisingly not helpful in this prediction task, while the meta information is much more predictive.
DeepHate: Hate Speech Detection via Multi-Faceted Text Representations
Mar 14, 2021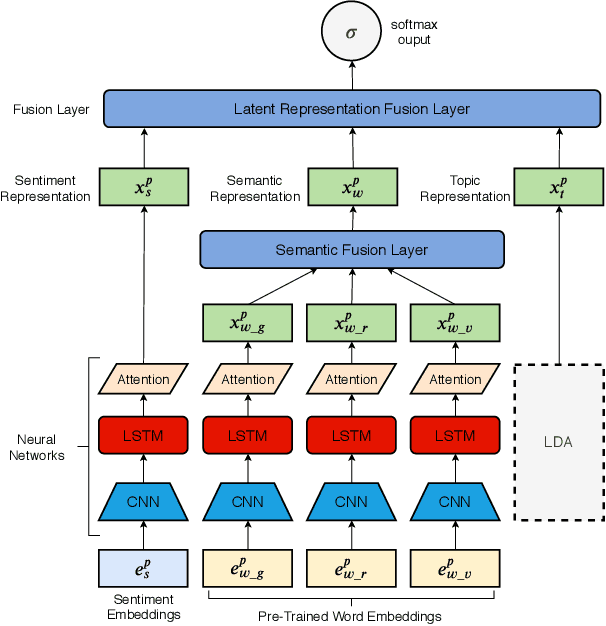
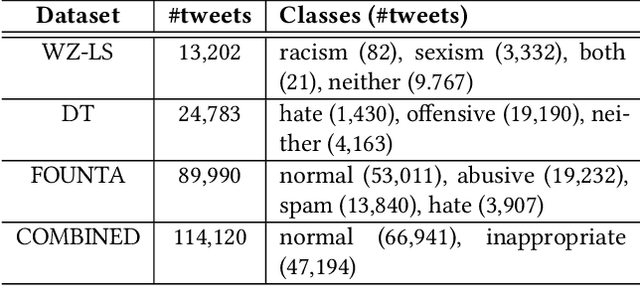
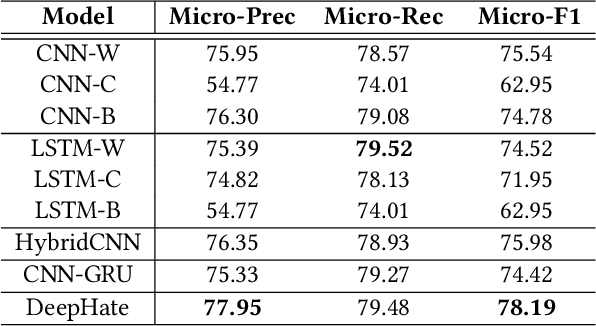
Online hate speech is an important issue that breaks the cohesiveness of online social communities and even raises public safety concerns in our societies. Motivated by this rising issue, researchers have developed many traditional machine learning and deep learning methods to detect hate speech in online social platforms automatically. However, most of these methods have only considered single type textual feature, e.g., term frequency, or using word embeddings. Such approaches neglect the other rich textual information that could be utilized to improve hate speech detection. In this paper, we propose DeepHate, a novel deep learning model that combines multi-faceted text representations such as word embeddings, sentiments, and topical information, to detect hate speech in online social platforms. We conduct extensive experiments and evaluate DeepHate on three large publicly available real-world datasets. Our experiment results show that DeepHate outperforms the state-of-the-art baselines on the hate speech detection task. We also perform case studies to provide insights into the salient features that best aid in detecting hate speech in online social platforms.