 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Models for Recommending Temporal Aspects of Entities
Jun 03, 2018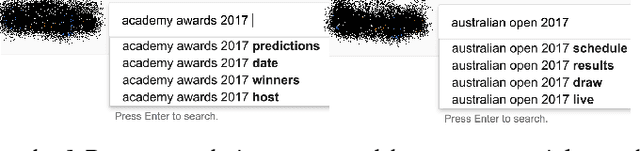
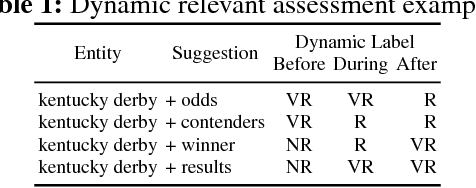
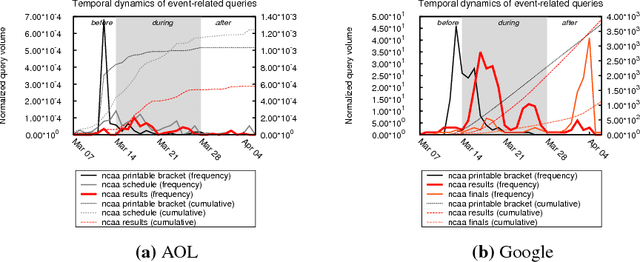

Entity aspect recommendation is an emerging task in semantic search that helps users discover serendipitous and prominent information with respect to an entity, of which salience (e.g., popularity) is the most important factor in previous work. However, entity aspects are temporally dynamic and often driven by events happening over time. For such cases, aspect suggestion based solely on salience features can give unsatisfactory results, for two reasons. First, salience is often accumulated over a long time period and does not account for recency. Second, many aspects related to an event entity are strongly time-dependent. In this paper, we study the task of temporal aspect recommendation for a given entity, which aims at recommending the most relevant aspects and takes into account time in order to improve search experience. We propose a novel event-centric ensemble ranking method that learns from multiple time and type-dependent models and dynamically trades off salience and recency characteristics. Through extensive experiments on real-world query logs, we demonstrate that our method is robust and achieves better effectiveness than competitive baselines.
Balancing Novelty and Salience: Adaptive Learning to Rank Entities for Timeline Summarization of High-impact Events
Jan 14, 2017



Long-running, high-impact events such as the Boston Marathon bombing often develop through many stages and involve a large number of entities in their unfolding. Timeline summarization of an event by key sentences eases story digestion, but does not distinguish between what a user remembers and what she might want to re-check. In this work, we present a novel approach for timeline summarization of high-impact events, which uses entities instead of sentences for summarizing the event at each individual point in time. Such entity summaries can serve as both (1) important memory cues in a retrospective event consideration and (2) pointers for personalized event exploration. In order to automatically create such summaries, it is crucial to identify the "right" entities for inclusion. We propose to learn a ranking function for entities, with a dynamically adapted trade-off between the in-document salience of entities and the informativeness of entities across documents, i.e., the level of new information associated with an entity for a time point under consideration. Furthermore, for capturing collective attention for an entity we use an innovative soft labeling approach based on Wikipedia. Our experiments on a real large news datasets confirm the effectiveness of the proposed methods.
Why is it Difficult to Detect Sudden and Unexpected Epidemic Outbreaks in Twitter?
Nov 10, 2016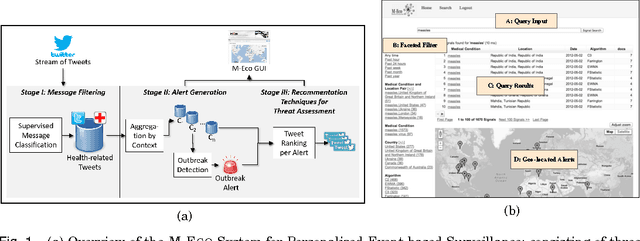
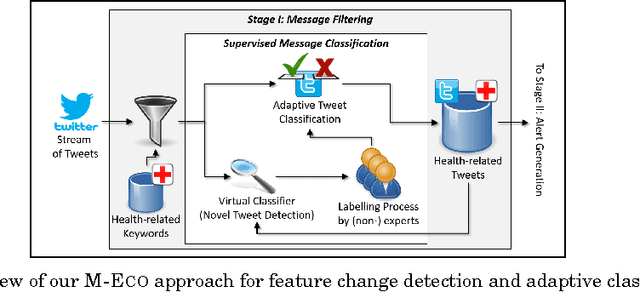
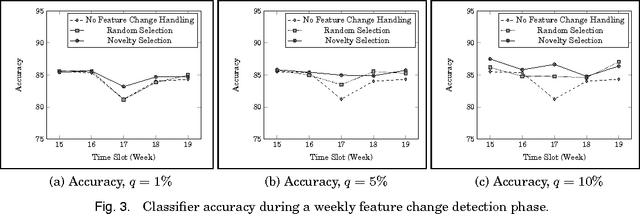
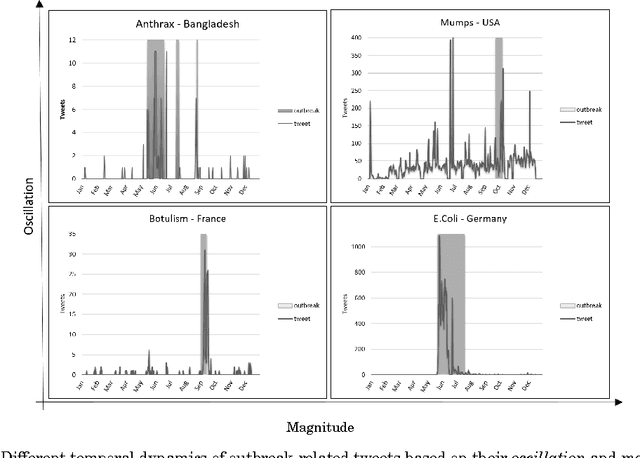
Social media services such as Twitter are a valuable source of information for decision support systems. Many studies have shown that this also holds for the medical domain, where Twitter is considered a viable tool for public health officials to sift through relevant information for the early detection, management, and control of epidemic outbreaks. This is possible due to the inherent capability of social media services to transmit information faster than traditional channels. However, the majority of current studies have limited their scope to the detection of common and seasonal health recurring events (e.g., Influenza-like Illness), partially due to the noisy nature of Twitter data, which makes outbreak detection and management very challenging. Within the European project M-Eco, we developed a Twitter-based Epidemic Intelligence (EI) system, which is designed to also handle a more general class of unexpected and aperiodic outbreaks. In particular, we faced three main research challenges in this endeavor: 1) dynamic classification to manage terminology evolution of Twitter messages, 2) alert generation to produce reliable outbreak alerts analyzing the (noisy) tweet time series, and 3) ranking and recommendation to support domain experts for better assessment of the generated alerts. In this paper, we empirically evaluate our proposed approach to these challenges using real-world outbreak datasets and a large collection of tweets. We validate our solution with domain experts, describe our experiences, and give a more realistic view on the benefits and issues of analyzing social media for public health.
Learning Dynamic Classes of Events using Stacked Multilayer Perceptron Networks
Jul 01, 2016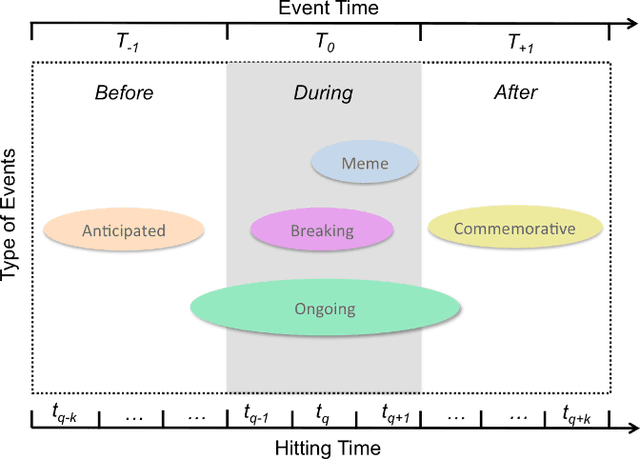
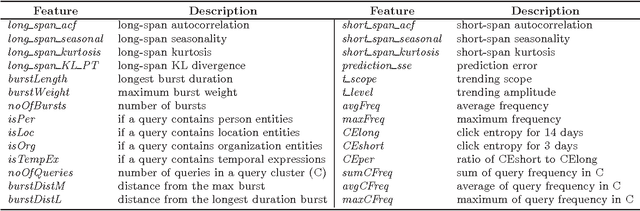
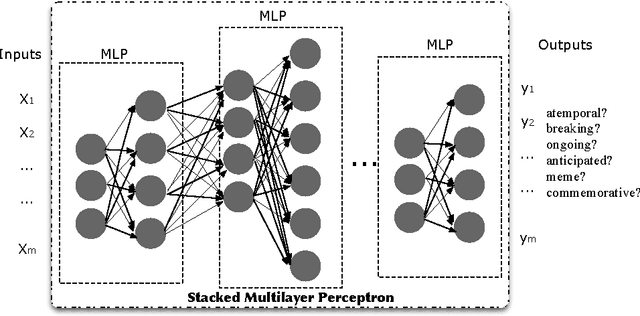
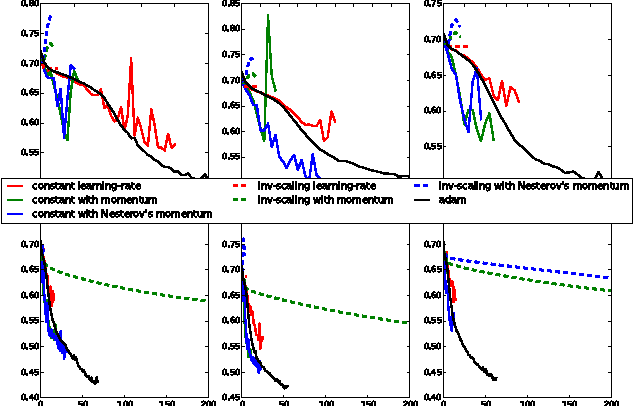
People often use a web search engine to find information about events of interest, for example, sport competitions, political elections, festivals and entertainment news. In this paper, we study a problem of detecting event-related queries, which is the first step before selecting a suitable time-aware retrieval model. In general, event-related information needs can be observed in query streams through various temporal patterns of user search behavior, e.g., spiky peaks for popular events, and periodicities for repetitive events. However, it is also common that users search for non-popular events, which may not exhibit temporal variations in query streams, e.g., past events recently occurred, historical events triggered by anniversaries or similar events, and future events anticipated to happen. To address the challenge of detecting dynamic classes of events, we propose a novel deep learning model to classify a given query into a predetermined set of multiple event types. Our proposed model, a Stacked Multilayer Perceptron (S-MLP) network, consists of multilayer perceptron used as a basic learning unit. We assemble stacked units to further learn complex relationships between neutrons in successive layers. To evaluate our proposed model, we conduct experiments using real-world queries and a set of manually created ground truth. Preliminary results have shown that our proposed deep learning model outperforms the state-of-the-art classification models significantly.