 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Collection of Real-Life Knowledge Work in Context: The RLKWiC Dataset
Apr 16, 2024Over the years, various approaches have been employed to enhance the productivity of knowledge workers, from addressing psychological well-being to the development of personal knowledge assistants. A significant challenge in this research area has been the absence of a comprehensive, publicly accessible dataset that mirrors real-world knowledge work. Although a handful of datasets exist, many are restricted in access or lack vital information dimensions, complicating meaningful comparison and benchmarking in the domain. This paper presents RLKWiC, a novel dataset of Real-Life Knowledge Work in Context, derived from monitoring the computer interactions of eight participants over a span of two months. As the first publicly available dataset offering a wealth of essential information dimensions (such as explicated contexts, textual contents, and semantics), RLKWiC seeks to address the research gap in the personal information management domain, providing valuable insights for modeling user behavior.
Towards Self-organizing Personal Knowledge Assistants in Evolving Corporate Memories
Aug 03, 2023


This paper presents a retrospective overview of a decade of research in our department towards self-organizing personal knowledge assistants in evolving corporate memories. Our research is typically inspired by real-world problems and often conducted in interdisciplinary collaborations with research and industry partners. We summarize past experiments and results comprising topics like various ways of knowledge graph construction in corporate and personal settings, Managed Forgetting and (Self-organizing) Context Spaces as a novel approach to Personal Information Management (PIM) and knowledge work support. Past results are complemented by an overview of related work and some of our latest findings not published so far. Last, we give an overview of our related industry use cases including a detailed look into CoMem, a Corporate Memory based on our presented research already in productive use and providing challenges for further research. Many contributions are only first steps in new directions with still a lot of untapped potential, especially with regard to further increasing the automation in PIM and knowledge work support.
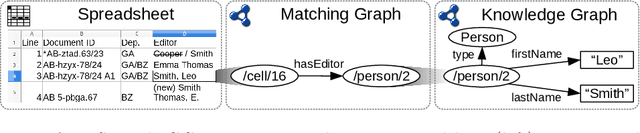
The Person Index Challenge: Extraction of Persons from Messy, Short Texts
Nov 16, 2020
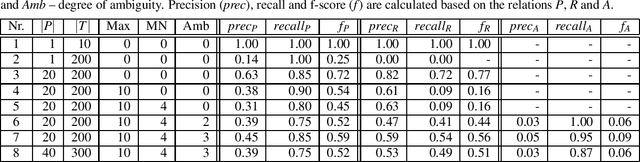
When persons are mentioned in texts with their first name, last name and/or middle names, there can be a high variation which of their names are used, how their names are ordered and if their names are abbreviated. If multiple persons are mentioned consecutively in very different ways, especially short texts can be perceived as "messy". Once ambiguous names occur, associations to persons may not be inferred correctly. Despite these eventualities, in this paper we ask how well an unsupervised algorithm can build a person index from short texts. We define a person index as a structured table that distinctly catalogs individuals by their names. First, we give a formal definition of the problem and describe a procedure to generate ground truth data for future evaluations. To give a first solution to this challenge, a baseline approach is implemented. By using our proposed evaluation strategy, we test the performance of the baseline and suggest further improvements. For future research the source code is publicly available.
Temporarily Unavailable: Memory Inhibition in Cognitive and Computer Science
Nov 15, 2019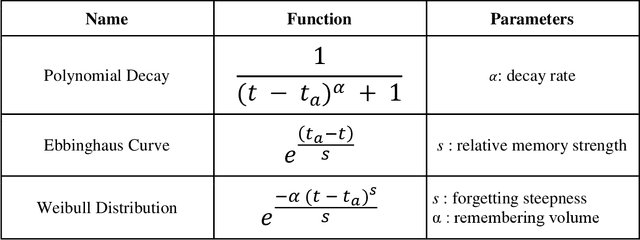
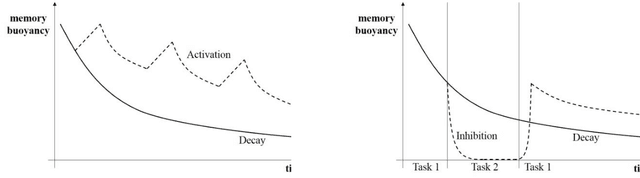
Inhibition is one of the core concepts in Cognitive Psychology. The idea of inhibitory mechanisms actively weakening representations in the human mind has inspired a great number of studies in various research domains. In contrast, Computer Science only recently has begun to consider inhibition as a second basic processing quality beside activation. Here, we review psychological research on inhibition in memory and link the gained insights with the current efforts in Computer Science of incorporating inhibitory principles for optimizing information retrieval in Personal Information Management. Four common aspects guide this review in both domains: 1. The purpose of inhibition to increase processing efficiency. 2. Its relation to activation. 3. Its links to contexts. 4. Its temporariness. In summary, the concept of inhibition has been used by Computer Science for enhancing software in various ways already. Yet, we also identify areas for promising future developments of inhibitory mechanisms, particularly context inhibition.
* 46 pages, 5 figures, preprint, final version published in IWC
Interactive Concept Mining on Personal Data -- Bootstrapping Semantic Services
Mar 14, 2019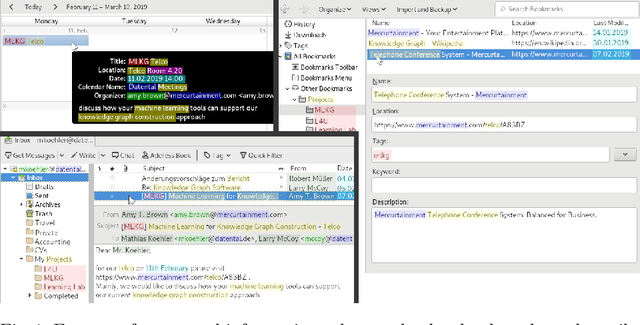
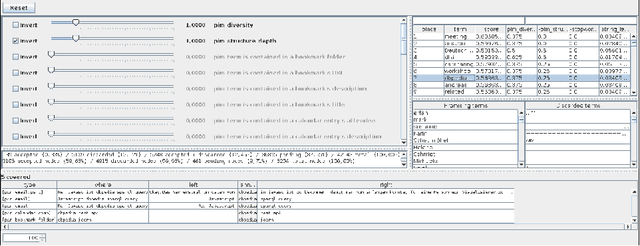
Semantic services (e.g. Semantic Desktops) are still afflicted by a cold start problem: in the beginning, the user's personal information sphere, i.e. files, mails, bookmarks, etc., is not represented by the system. Information extraction tools used to kick-start the system typically create 1:1 representations of the different information items. Higher level concepts, for example found in file names, mail subjects or in the content body of these items, are not extracted. Leaving these concepts out may lead to underperformance, having to many of them (e.g. by making every found term a concept) will clutter the arising knowledge graph with non-helpful relations. In this paper, we present an interactive concept mining approach proposing concept candidates gathered by exploiting given schemata of usual personal information management applications and analysing the personal information sphere using various metrics. To heed the subjective view of the user, a graphical user interface allows to easily rank and give feedback on proposed concept candidates, thus keeping only those actually considered relevant. A prototypical implementation demonstrates major steps of our approach.
Inflection-Tolerant Ontology-Based Named Entity Recognition for Real-Time Applications
Dec 05, 2018
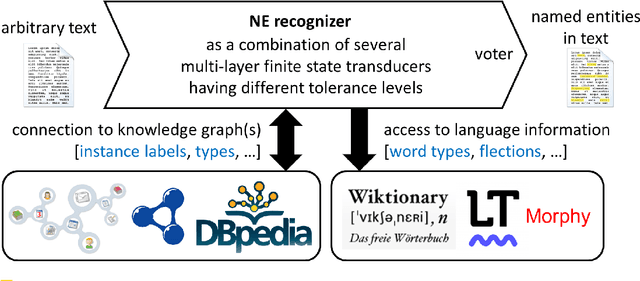
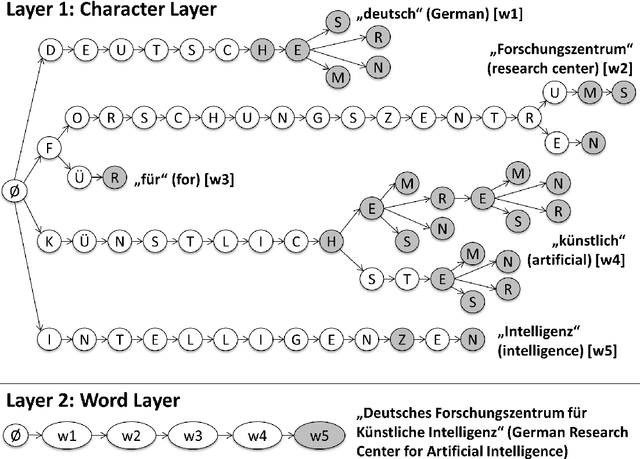

A growing number of applications users daily interact with have to operate in (near) real-time: chatbots, digital companions, knowledge work support systems -- just to name a few. To perform the services desired by the user, these systems have to analyze user activity logs or explicit user input extremely fast. In particular, text content (e.g. in form of text snippets) needs to be processed in an information extraction task. Regarding the aforementioned temporal requirements, this has to be accomplished in just a few milliseconds, which limits the number of methods that can be applied. Practically, only very fast methods remain, which on the other hand deliver worse results than slower but more sophisticated Natural Language Processing (NLP) pipelines. In this paper, we investigate and propose methods for real-time capable Named Entity Recognition (NER). As a first improvement step we address are word variations induced by inflection, for example present in the German language. Our approach is ontology-based and makes use of several language information sources like Wiktionary. We evaluated it using the German Wikipedia (about 9.4B characters), for which the whole NER process took considerably less than an hour. Since precision and recall are higher than with comparably fast methods, we conclude that the quality gap between high speed methods and sophisticated NLP pipelines can be narrowed a bit more without losing too much runtime performance.
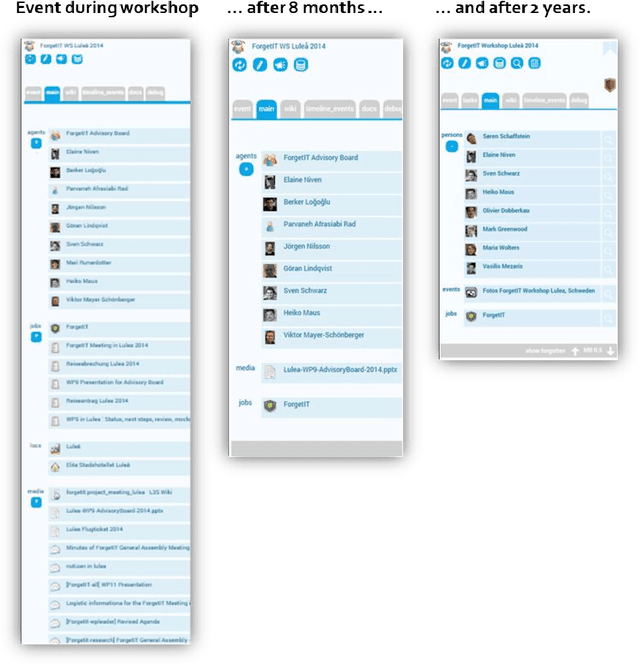
Managed Forgetting to Support Information Management and Knowledge Work
Nov 17, 2018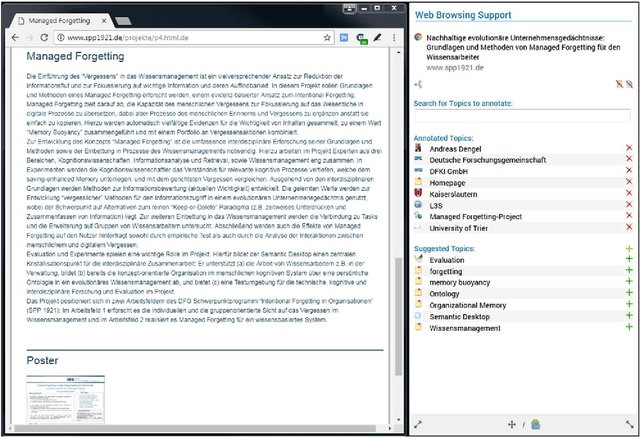
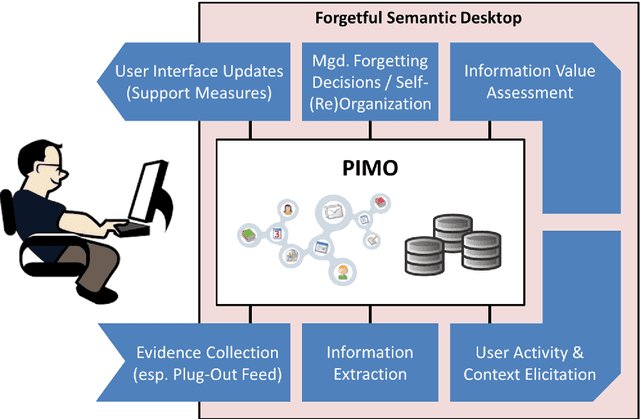
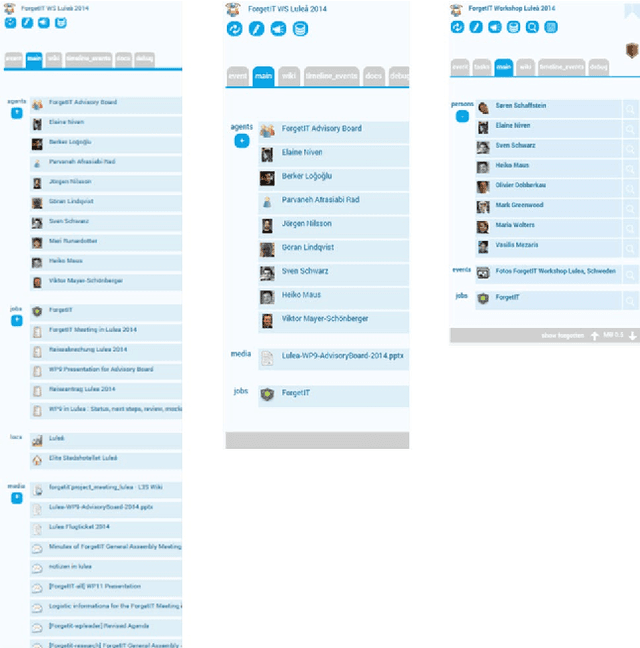
Trends like digital transformation even intensify the already overwhelming mass of information knowledge workers face in their daily life. To counter this, we have been investigating knowledge work and information management support measures inspired by human forgetting. In this paper, we give an overview of solutions we have found during the last five years as well as challenges that still need to be tackled. Additionally, we share experiences gained with the prototype of a first forgetful information system used 24/7 in our daily work for the last three years. We also address the untapped potential of more explicated user context as well as features inspired by Memory Inhibition, which is our current focus of research.
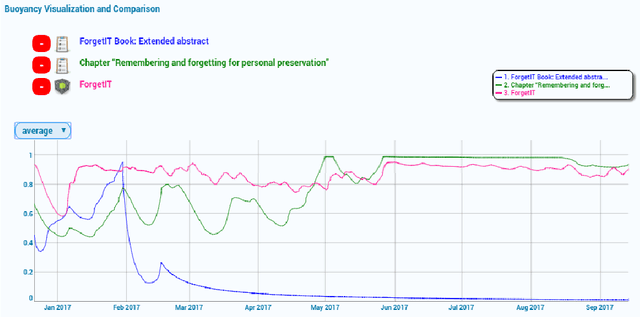
Advanced Memory Buoyancy for Forgetful Information Systems
Nov 17, 2018


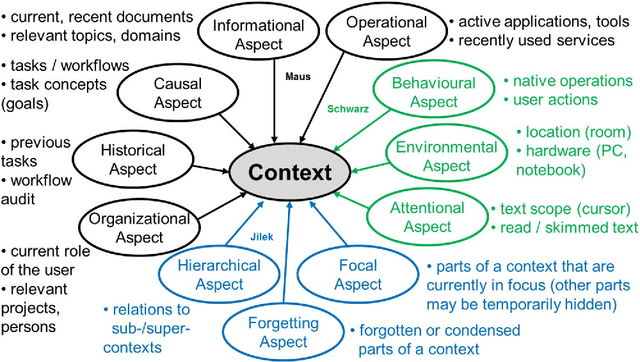
Knowledge workers face an ever increasing flood of information in their daily lives. To counter this and provide better support for information management and knowledge work in general, we have been investigating solutions inspired by human forgetting since 2013. These solutions are based on Semantic Desktop (SD) and Managed Forgetting (MF) technology. A key concept of the latter is the so-called Memory Buoyancy (MB), which is intended to represent an information item's current value for the user and allows to employ forgetting mechanisms. The SD thus continuously performs information value assessment updating MB and triggering respective MF measures. We extended an SD-based organizational memory system, which we have been using in daily work for over seven years now, with MF mechanisms directly embedding them in daily activities, too, and enabling us to test and optimize them in real-world scenarios. In this paper, we first present our initial version of MB and discuss success and failure stories we have been experiencing with it during three years of practical usage. We learned from cognitive psychology that our previous research on context can be beneficial for MF. Thus, we created an advanced MB version especially taking user context, and in particular context switches, into account. These enhancements as well as a first prototypical implementation are presented, too.
Towards Semantically Enhanced Data Understanding
Jun 13, 2018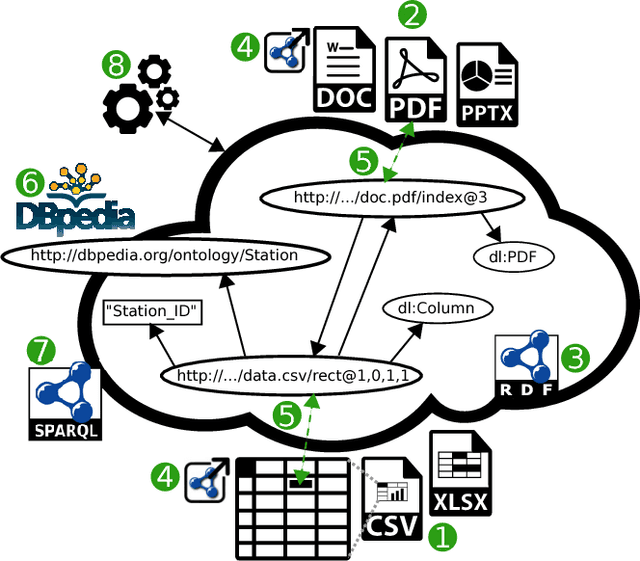
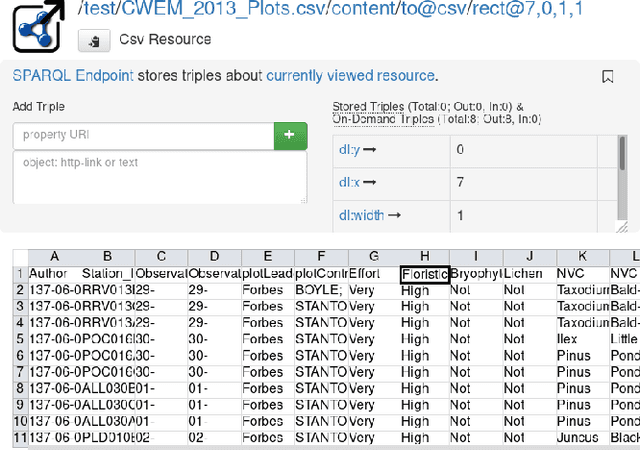
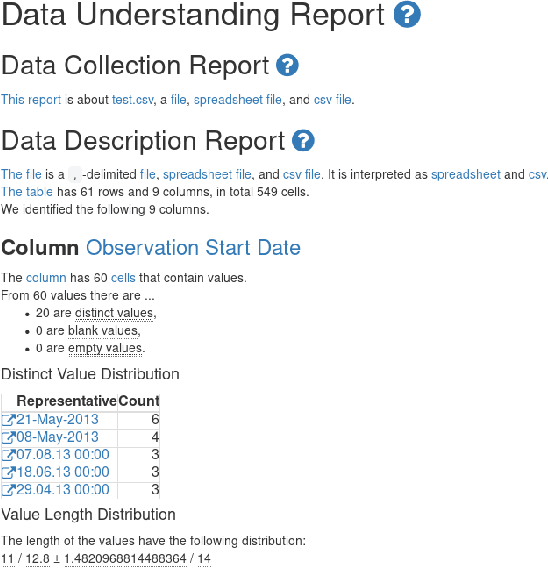
In the field of machine learning, data understanding is the practice of getting initial insights in unknown datasets. Such knowledge-intensive tasks require a lot of documentation, which is necessary for data scientists to grasp the meaning of the data. Usually, documentation is separate from the data in various external documents, diagrams, spreadsheets and tools which causes considerable look up overhead. Moreover, other supporting applications are not able to consume and utilize such unstructured data. That is why we propose a methodology that uses a single semantic model that interlinks data with its documentation. Hence, data scientists are able to directly look up the connected information about the data by simply following links. Equally, they can browse the documentation which always refers to the data. Furthermore, the model can be used by other approaches providing additional support, like searching, comparing, integrating or visualizing data. To showcase our approach we also demonstrate an early prototype.
Context Spaces as the Cornerstone of a Near-Transparent & Self-Reorganizing Semantic Desktop
May 06, 2018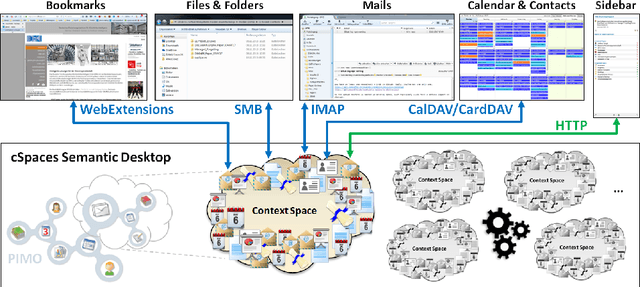
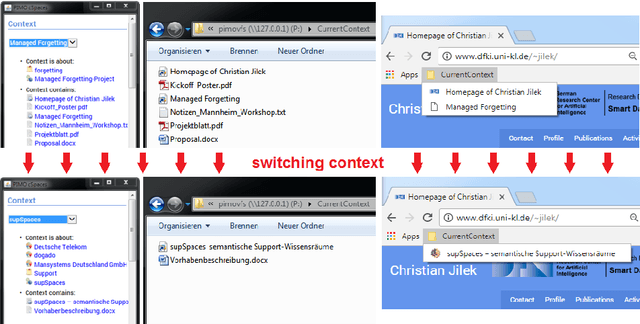
Existing Semantic Desktops are still reproached for being too complicated to use or not scaling well. Besides, a real "killer app" is still missing. In this paper, we present a new prototype inspired by NEPOMUK and its successors having a semantic graph and ontologies as its basis. In addition, we introduce the idea of context spaces that users can directly interact with and work on. To make them available in all applications without further ado, the system is transparently integrated using mostly standard protocols complemented by a sidebar for advanced features. By exploiting collected context information and applying Managed Forgetting features (like hiding, condensation or deletion), the system is able to dynamically reorganize itself, which also includes a kind of tidy-up-itself functionality. We therefore expect it to be more scalable while providing new levels of user support. An early prototype has been implemented and is presented in this demo.
* 5 pages, 2 figures (high-res versions in attachments), 1 demo video (in attachments)