 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Person Index Challenge: Extraction of Persons from Messy, Short Texts
Paper and Code

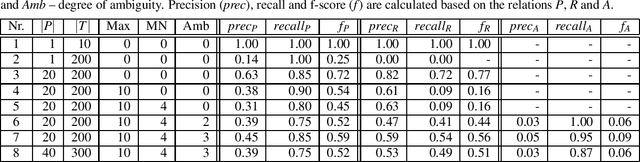
When persons are mentioned in texts with their first name, last name and/or middle names, there can be a high variation which of their names are used, how their names are ordered and if their names are abbreviated. If multiple persons are mentioned consecutively in very different ways, especially short texts can be perceived as "messy". Once ambiguous names occur, associations to persons may not be inferred correctly. Despite these eventualities, in this paper we ask how well an unsupervised algorithm can build a person index from short texts. We define a person index as a structured table that distinctly catalogs individuals by their names. First, we give a formal definition of the problem and describe a procedure to generate ground truth data for future evaluations. To give a first solution to this challenge, a baseline approach is implemented. By using our proposed evaluation strategy, we test the performance of the baseline and suggest further improvements. For future research the source code is publicly available.