 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Keypoint-less Camera Calibration for Sports Field Registration in Soccer
Jul 24, 2022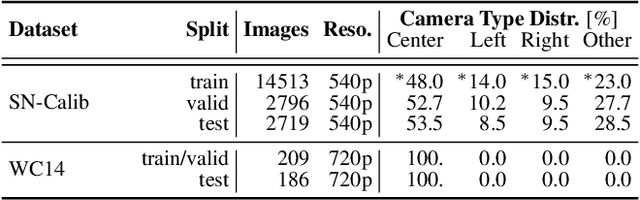
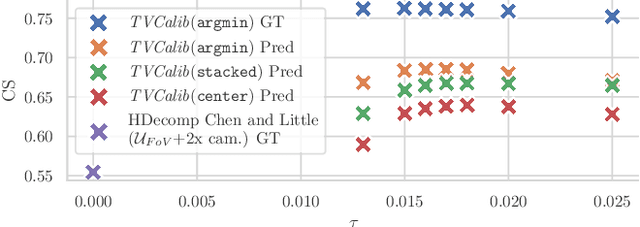

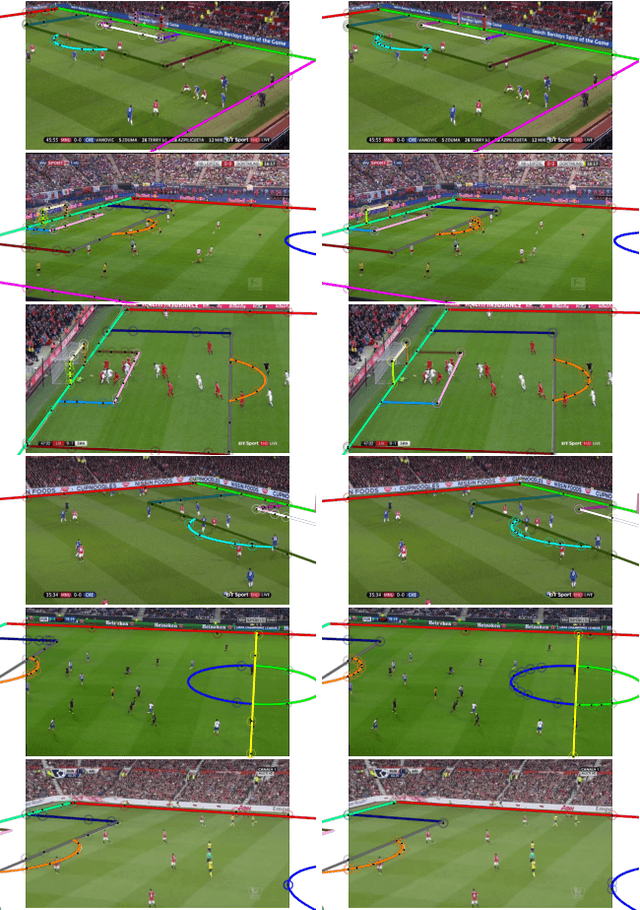
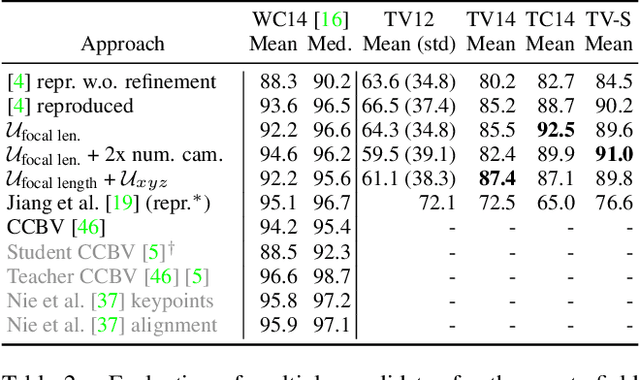
Sports field registration in broadcast videos is typically interpreted as the task of homography estimation, which provides a mapping between a planar field and the corresponding visible area of the image. In contrast to previous approaches, we consider the task as a camera calibration problem. First, we introduce a differentiable objective function that is able to learn the camera pose and focal length from segment correspondences (e.g., lines, point clouds), based on pixel-level annotations for segments of a known calibration object, i.e., the sports field. The calibration module iteratively minimizes the segment reprojection error induced by the estimated camera parameters. Second, we propose a novel approach for 3D sports field registration from broadcast soccer images. The calibration module does not require any training data and compared to the typical solution, which subsequently refines an initial estimation, our solution does it in one step. The proposed method is evaluated for sports field registration on two datasets and achieves superior results compared to two state-of-the-art approaches.
Extraction of Positional Player Data from Broadcast Soccer Videos
Oct 21, 2021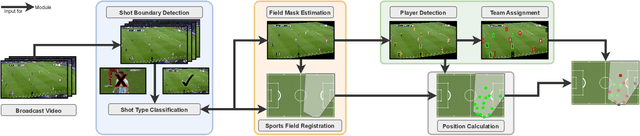

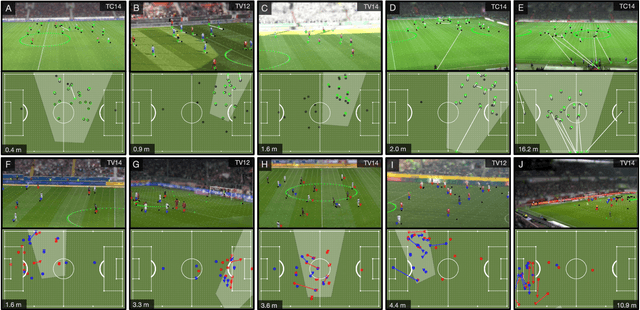
Computer-aided support and analysis are becoming increasingly important in the modern world of sports. The scouting of potential prospective players, performance as well as match analysis, and the monitoring of training programs rely more and more on data-driven technologies to ensure success. Therefore, many approaches require large amounts of data, which are, however, not easy to obtain in general. In this paper, we propose a pipeline for the fully-automated extraction of positional data from broadcast video recordings of soccer matches. In contrast to previous work, the system integrates all necessary sub-tasks like sports field registration, player detection, or team assignment that are crucial for player position estimation. The quality of the modules and the entire system is interdependent. A comprehensive experimental evaluation is presented for the individual modules as well as the entire pipeline to identify the influence of errors to subsequent modules and the overall result. In this context, we propose novel evaluation metrics to compare the output with ground-truth positional data.
A Unified Taxonomy and Multimodal Dataset for Events in Invasion Games
Aug 26, 2021
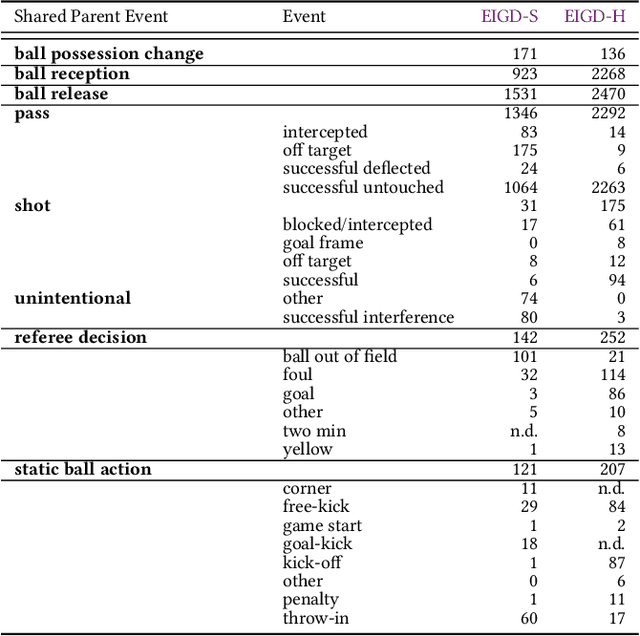


The automatic detection of events in complex sports games like soccer and handball using positional or video data is of large interest in research and industry. One requirement is a fundamental understanding of underlying concepts, i.e., events that occur on the pitch. Previous work often deals only with so-called low-level events based on well-defined rules such as free kicks, free throws, or goals. High-level events, such as passes, are less frequently approached due to a lack of consistent definitions. This introduces a level of ambiguity that necessities careful validation when regarding event annotations. Yet, this validation step is usually neglected as the majority of studies adopt annotations from commercial providers on private datasets of unknown quality and focuses on soccer only. To address these issues, we present (1) a universal taxonomy that covers a wide range of low and high-level events for invasion games and is exemplarily refined to soccer and handball, and (2) release two multi-modal datasets comprising video and positional data with gold-standard annotations to foster research in fine-grained and ball-centered event spotting. Experiments on human performance demonstrate the robustness of the proposed taxonomy, and that disagreements and ambiguities in the annotation increase with the complexity of the event. An I3D model for video classification is adopted for event spotting and reveals the potential for benchmarking. Datasets are available at: https://github.com/mm4spa/eigd
Interpretable Semantic Photo Geolocalization
Apr 30, 2021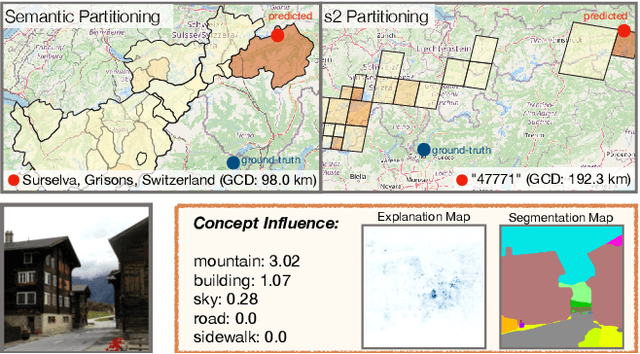

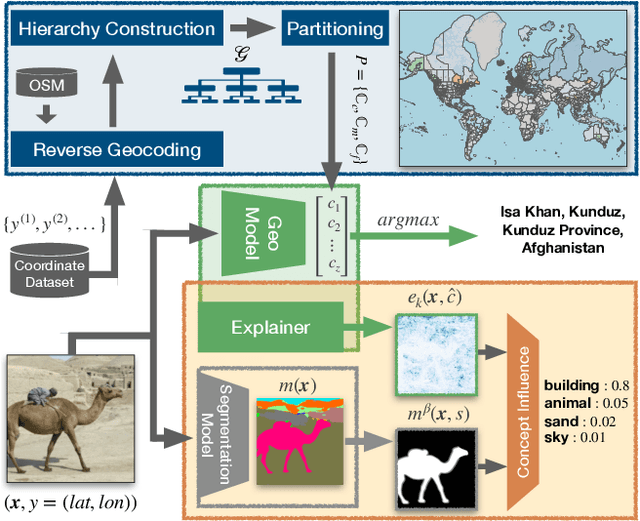
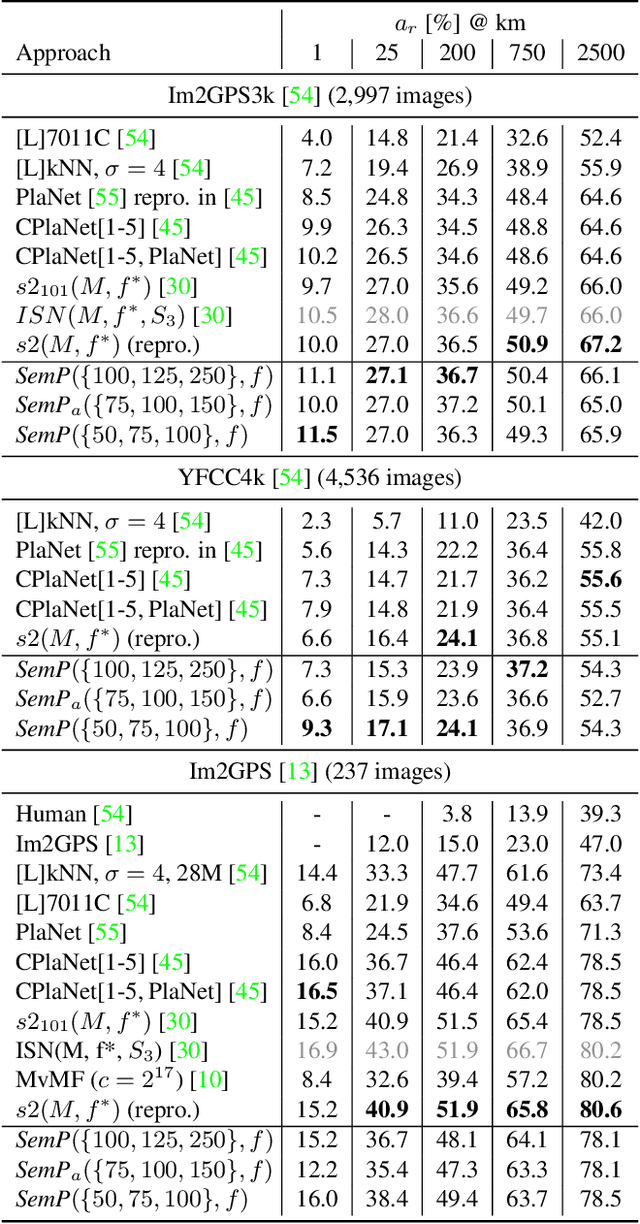
Planet-scale photo geolocalization is the complex task of estimating the location depicted in an image solely based on its visual content. Due to the success of convolutional neural networks (CNNs), current approaches achieve super-human performance. However, previous work has exclusively focused on optimizing geolocalization accuracy. Moreover, due to the black-box property of deep learning systems, their predictions are difficult to validate for humans. State-of-the-art methods treat the task as a classification problem, where the choice of the classes, that is the partitioning of the world map, is the key for success. In this paper, we present two contributions in order to improve the interpretability of a geolocalization model: (1) We propose a novel, semantic partitioning method which intuitively leads to an improved understanding of the predictions, while at the same time state-of-the-art results are achieved for geolocational accuracy on benchmark test sets; (2) We introduce a novel metric to assess the importance of semantic visual concepts for a certain prediction to provide additional interpretable information, which allows for a large-scale analysis of already trained models.
Multimodal Analytics for Real-world News using Measures of Cross-modal Entity Consistency
Mar 23, 2020
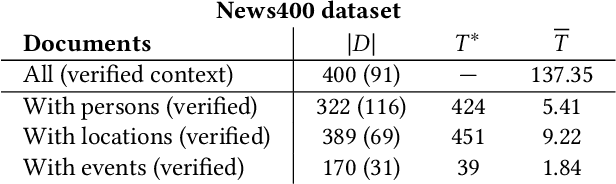
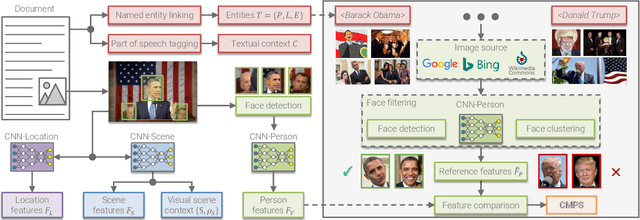

The World Wide Web has become a popular source for gathering information and news. Multimodal information, e.g., enriching text with photos, is typically used to convey the news more effectively or to attract attention. Photo content can range from decorative, depict additional important information, or can even contain misleading information. Therefore, automatic approaches to quantify cross-modal consistency of entity representation can support human assessors to evaluate the overall multimodal message, for instance, with regard to bias or sentiment. In some cases such measures could give hints to detect fake news, which is an increasingly important topic in today's society. In this paper, we introduce a novel task of cross-modal consistency verification in real-world news and present a multimodal approach to quantify the entity coherence between image and text. Named entity linking is applied to extract persons, locations, and events from news texts. Several measures are suggested to calculate cross-modal similarity for these entities using state of the art approaches. In contrast to previous work, our system automatically gathers example data from the Web and is applicable to real-world news. Results on two novel datasets that cover different languages, topics, and domains demonstrate the feasibility of our approach. Datasets and code are publicly available to foster research towards this new direction.
"Does 4-4-2 exist?" -- An Analytics Approach to Understand and Classify Football Team Formations in Single Match Situations
Sep 02, 2019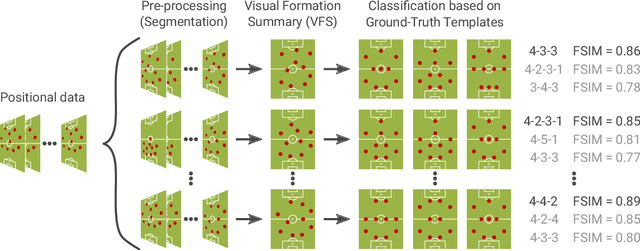

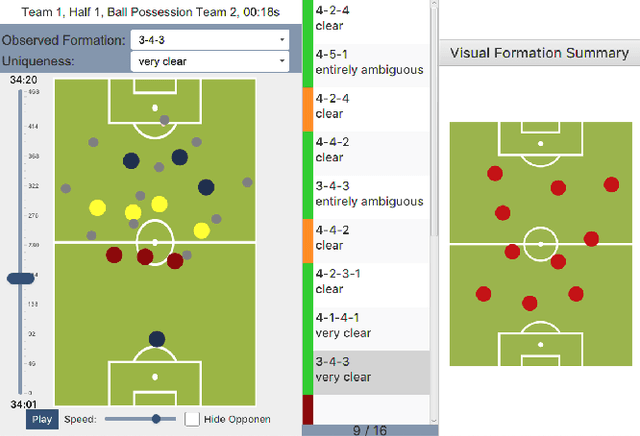

The chances to win a football match can be significantly increased if the right tactic is chosen and the behavior of the opposite team is well anticipated. For this reason, every professional football club employs a team of game analysts. However, at present game performance analysis is done manually and therefore highly time-consuming. Consequently, automated tools to support the analysis process are required. In this context, one of the main tasks is to summarize team formations by patterns such as 4-4-2. In this paper, we introduce an analytics approach that automatically classifies and visualizes the team formation based on the players' position data. We focus on single match situations instead of complete halftimes or matches to provide a more detailed analysis. A detailed analysis of individual match situations depending on ball possession and match segment length is provided. For this purpose, a visual summary is utilized that summarizes the team formation in a match segment. An expert annotation study is conducted that demonstrates 1) the complexity of the task and 2) the usefulness of the visualization of single situations to understand team formations. The suggested classification approach outperforms existing methods for formation classification. In particular, our approach gives insights about the shortcomings of using patterns like 4-4-2 to describe team formations.