 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Semantic Photo Geolocalization
Paper and Code
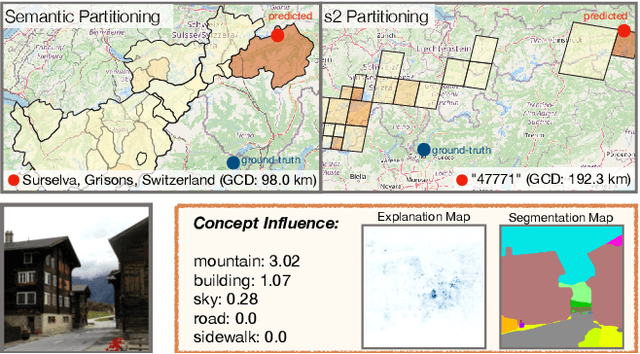

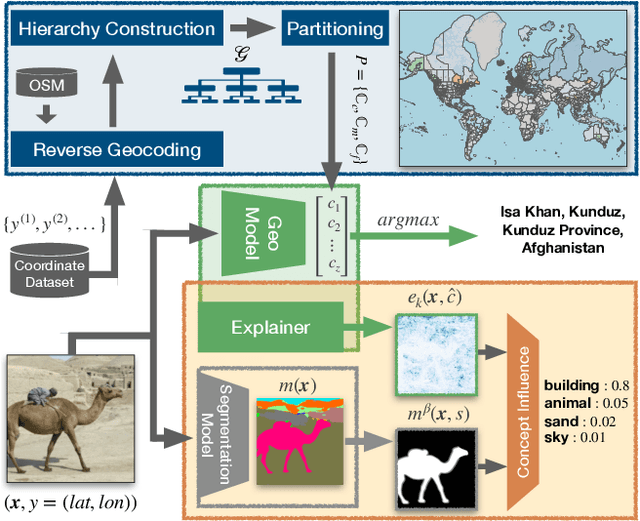
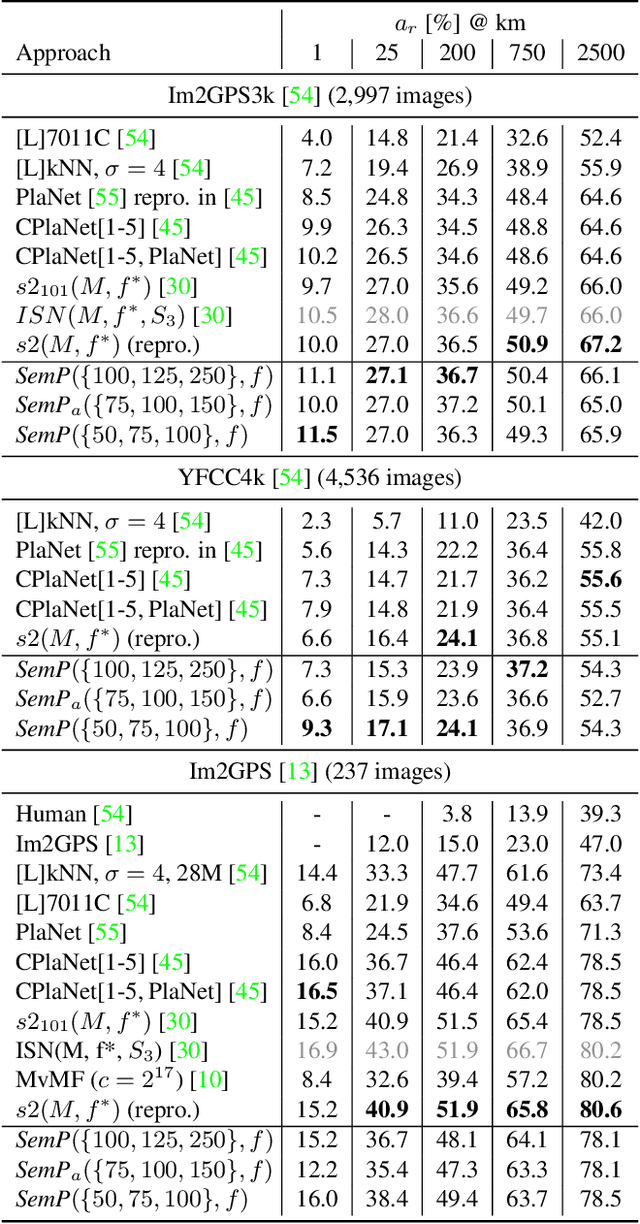
Planet-scale photo geolocalization is the complex task of estimating the location depicted in an image solely based on its visual content. Due to the success of convolutional neural networks (CNNs), current approaches achieve super-human performance. However, previous work has exclusively focused on optimizing geolocalization accuracy. Moreover, due to the black-box property of deep learning systems, their predictions are difficult to validate for humans. State-of-the-art methods treat the task as a classification problem, where the choice of the classes, that is the partitioning of the world map, is the key for success. In this paper, we present two contributions in order to improve the interpretability of a geolocalization model: (1) We propose a novel, semantic partitioning method which intuitively leads to an improved understanding of the predictions, while at the same time state-of-the-art results are achieved for geolocational accuracy on benchmark test sets; (2) We introduce a novel metric to assess the importance of semantic visual concepts for a certain prediction to provide additional interpretable information, which allows for a large-scale analysis of already trained models.