 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Visualization Types and Perspectives in Patents
Jul 19, 2023



Due to the swift growth of patent applications each year, information and multimedia retrieval approaches that facilitate patent exploration and retrieval are of utmost importance. Different types of visualizations (e.g., graphs, technical drawings) and perspectives (e.g., side view, perspective) are used to visualize details of innovations in patents. The classification of these images enables a more efficient search and allows for further analysis. So far, datasets for image type classification miss some important visualization types for patents. Furthermore, related work does not make use of recent deep learning approaches including transformers. In this paper, we adopt state-of-the-art deep learning methods for the classification of visualization types and perspectives in patent images. We extend the CLEF-IP dataset for image type classification in patents to ten classes and provide manual ground truth annotations. In addition, we derive a set of hierarchical classes from a dataset that provides weakly-labeled data for image perspectives. Experimental results have demonstrated the feasibility of the proposed approaches. Source code, models, and dataset will be made publicly available.
Unsupervised Video Summarization via Multi-source Features
May 26, 2021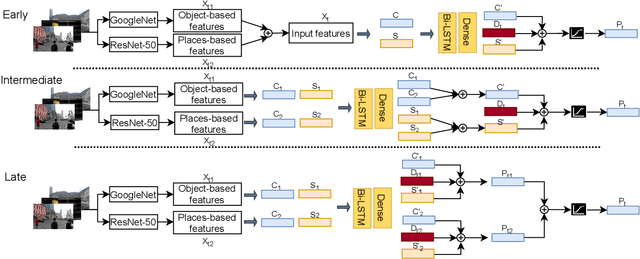
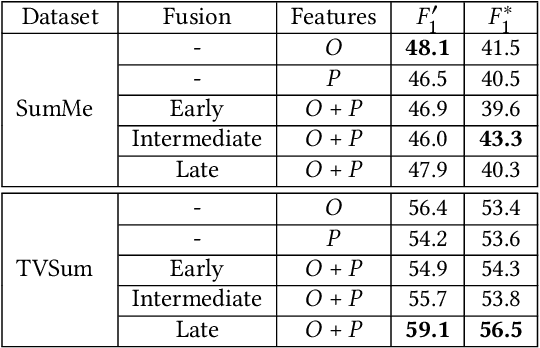
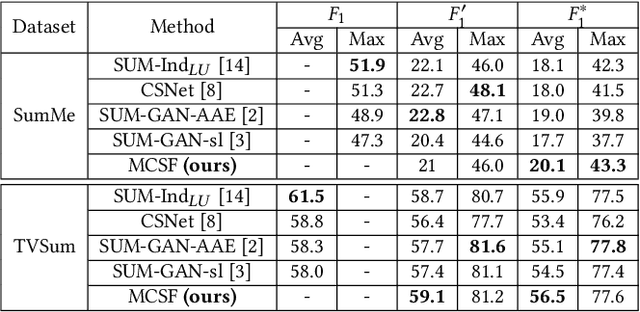

Video summarization aims at generating a compact yet representative visual summary that conveys the essence of the original video. The advantage of unsupervised approaches is that they do not require human annotations to learn the summarization capability and generalize to a wider range of domains. Previous work relies on the same type of deep features, typically based on a model pre-trained on ImageNet data. Therefore, we propose the incorporation of multiple feature sources with chunk and stride fusion to provide more information about the visual content. For a comprehensive evaluation on the two benchmarks TVSum and SumMe, we compare our method with four state-of-the-art approaches. Two of these approaches were implemented by ourselves to reproduce the reported results. Our evaluation shows that we obtain state-of-the-art results on both datasets, while also highlighting the shortcomings of previous work with regard to the evaluation methodology. Finally, we perform error analysis on videos for the two benchmark datasets to summarize and spot the factors that lead to misclassifications.
Supervised Video Summarization via Multiple Feature Sets with Parallel Attention
May 13, 2021

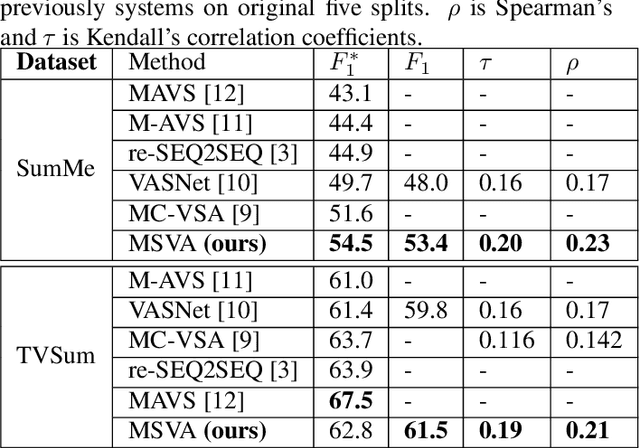

The assignment of importance scores to particular frames or (short) segments in a video is crucial for summarization, but also a difficult task. Previous work utilizes only one source of visual features. In this paper, we suggest a novel model architecture that combines three feature sets for visual content and motion to predict importance scores. The proposed architecture utilizes an attention mechanism before fusing motion features and features representing the (static) visual content, i.e., derived from an image classification model. Comprehensive experimental evaluations are reported for two well-known datasets, SumMe and TVSum. In this context, we identify methodological issues on how previous work used these benchmark datasets, and present a fair evaluation scheme with appropriate data splits that can be used in future work. When using static and motion features with parallel attention mechanism, we improve state-of-the-art results for SumMe, while being on par with the state of the art for the other dataset.
Classification of Important Segments in Educational Videos using Multimodal Features
Oct 26, 2020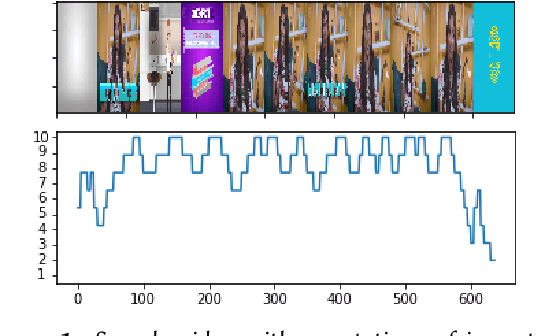
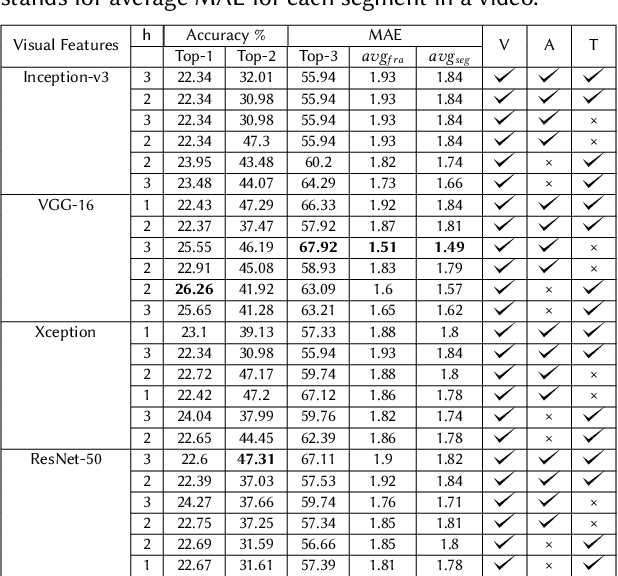
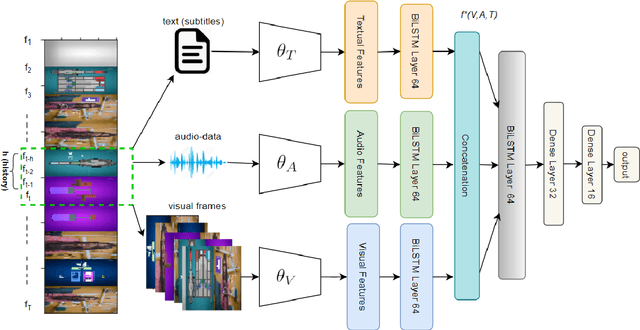
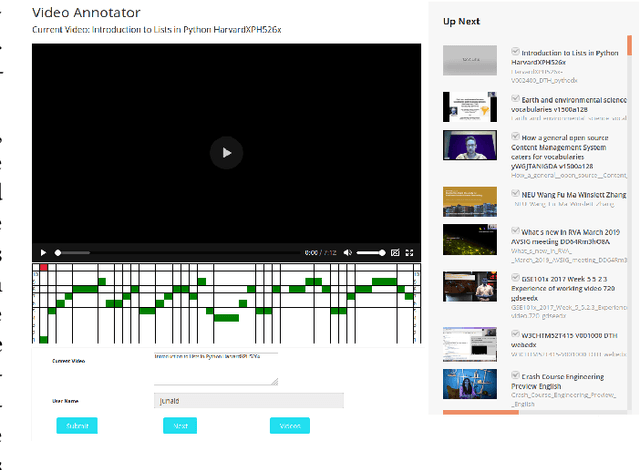
Videos are a commonly-used type of content in learning during Web search. Many e-learning platforms provide quality content, but sometimes educational videos are long and cover many topics. Humans are good in extracting important sections from videos, but it remains a significant challenge for computers. In this paper, we address the problem of assigning importance scores to video segments, that is how much information they contain with respect to the overall topic of an educational video. We present an annotation tool and a new dataset of annotated educational videos collected from popular online learning platforms. Moreover, we propose a multimodal neural architecture that utilizes state-of-the-art audio, visual and textual features. Our experiments investigate the impact of visual and temporal information, as well as the combination of multimodal features on importance prediction.