 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Video Summarization via Multiple Feature Sets with Parallel Attention
Paper and Code


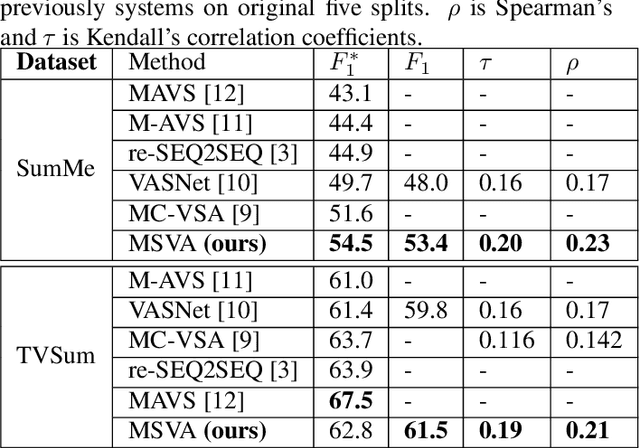

The assignment of importance scores to particular frames or (short) segments in a video is crucial for summarization, but also a difficult task. Previous work utilizes only one source of visual features. In this paper, we suggest a novel model architecture that combines three feature sets for visual content and motion to predict importance scores. The proposed architecture utilizes an attention mechanism before fusing motion features and features representing the (static) visual content, i.e., derived from an image classification model. Comprehensive experimental evaluations are reported for two well-known datasets, SumMe and TVSum. In this context, we identify methodological issues on how previous work used these benchmark datasets, and present a fair evaluation scheme with appropriate data splits that can be used in future work. When using static and motion features with parallel attention mechanism, we improve state-of-the-art results for SumMe, while being on par with the state of the art for the other dataset.