 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Human Pose Estimation in Art-historical Images
Jul 11, 2022
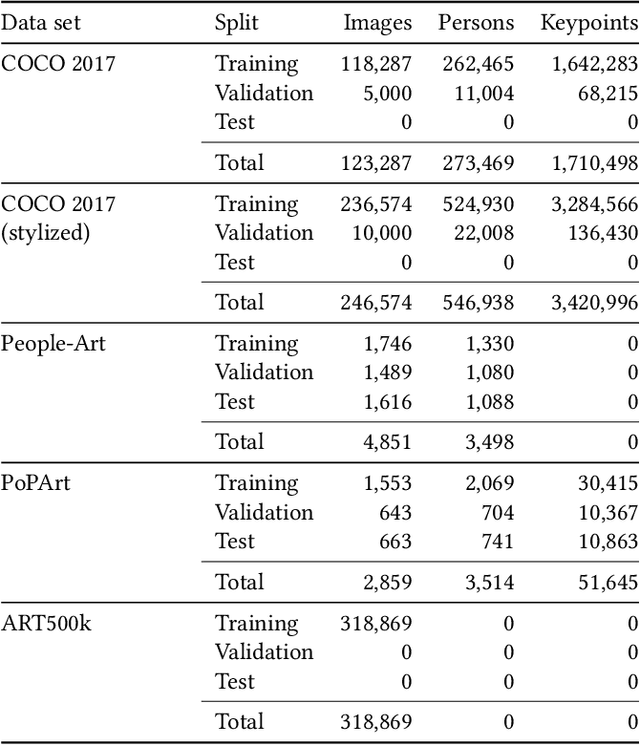

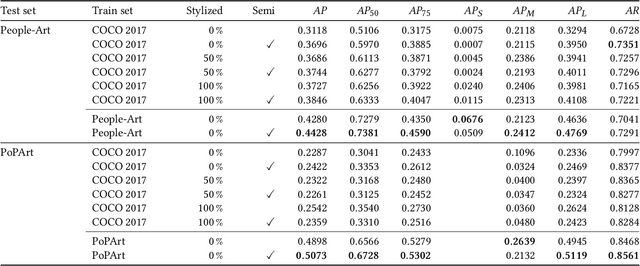
Gesture as language of non-verbal communication has been theoretically established since the 17th century. However, its relevance for the visual arts has been expressed only sporadically. This may be primarily due to the sheer overwhelming amount of data that traditionally had to be processed by hand. With the steady progress of digitization, though, a growing number of historical artifacts have been indexed and made available to the public, creating a need for automatic retrieval of art-historical motifs with similar body constellations or poses. Since the domain of art differs significantly from existing real-world data sets for human pose estimation due to its style variance, this presents new challenges. In this paper, we propose a novel approach to estimate human poses in art-historical images. In contrast to previous work that attempts to bridge the domain gap with pre-trained models or through style transfer, we suggest semi-supervised learning for both object and keypoint detection. Furthermore, we introduce a novel domain-specific art data set that includes both bounding box and keypoint annotations of human figures. Our approach achieves significantly better results than methods that use pre-trained models or style transfer.
iART: A Search Engine for Art-Historical Images to Support Research in the Humanities
Aug 03, 2021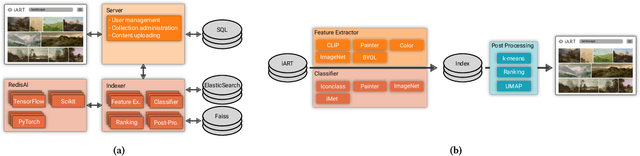
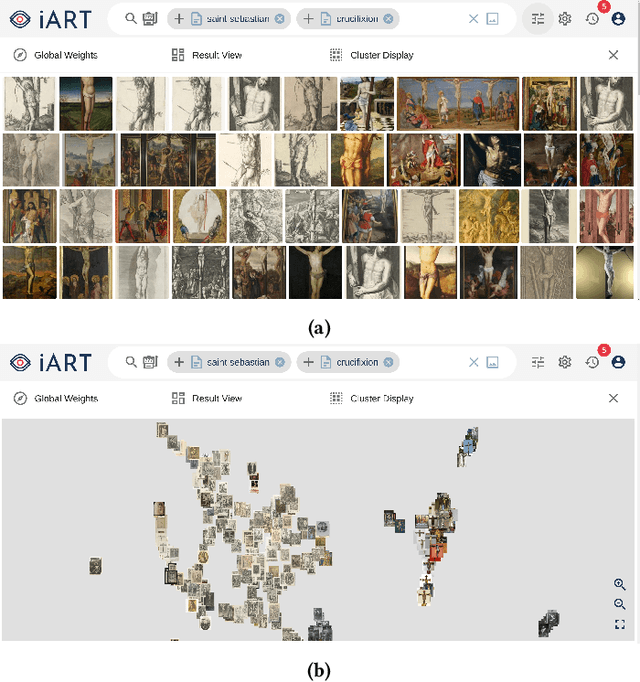
In this paper, we introduce iART: an open Web platform for art-historical research that facilitates the process of comparative vision. The system integrates various machine learning techniques for keyword- and content-based image retrieval as well as category formation via clustering. An intuitive GUI supports users to define queries and explore results. By using a state-of-the-art cross-modal deep learning approach, it is possible to search for concepts that were not previously detected by trained classification models. Art-historical objects from large, openly licensed collections such as Amsterdam Rijksmuseum and Wikidata are made available to users.
Unsupervised Training Data Generation of Handwritten Formulas using Generative Adversarial Networks with Self-Attention
Jun 17, 2021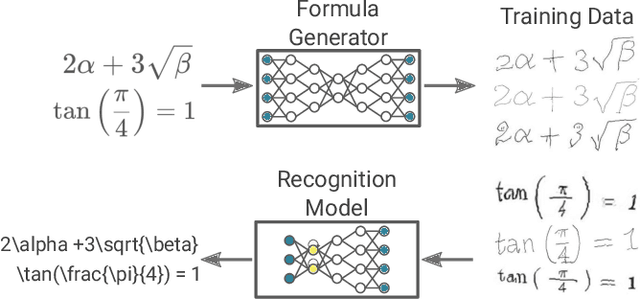
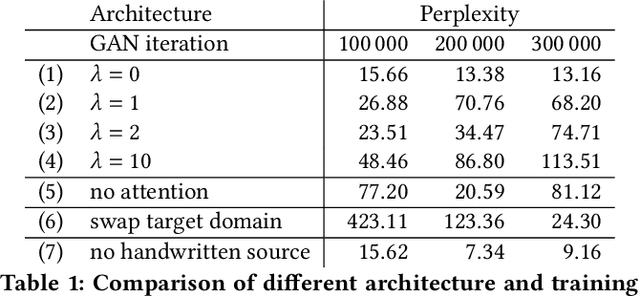
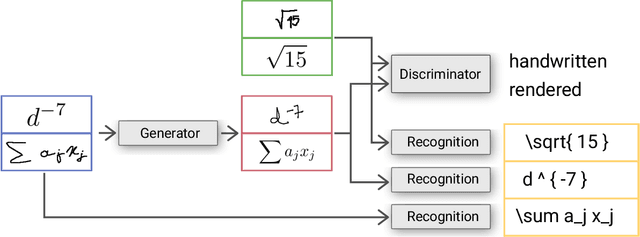
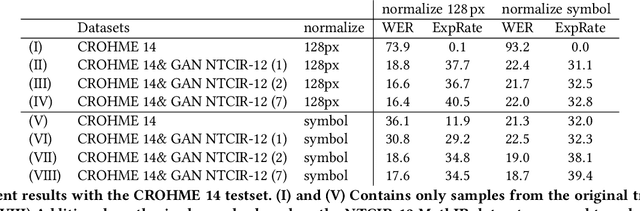
The recognition of handwritten mathematical expressions in images and video frames is a difficult and unsolved problem yet. Deep convectional neural networks are basically a promising approach, but typically require a large amount of labeled training data. However, such a large training dataset does not exist for the task of handwritten formula recognition. In this paper, we introduce a system that creates a large set of synthesized training examples of mathematical expressions which are derived from LaTeX documents. For this purpose, we propose a novel attention-based generative adversarial network to translate rendered equations to handwritten formulas. The datasets generated by this approach contain hundreds of thousands of formulas, making it ideal for pretraining or the design of more complex models. We evaluate our synthesized dataset and the recognition approach on the CROHME 2014 benchmark dataset. Experimental results demonstrate the feasibility of the approach.
QuTI! Quantifying Text-Image Consistency in Multimodal Documents
Apr 28, 2021
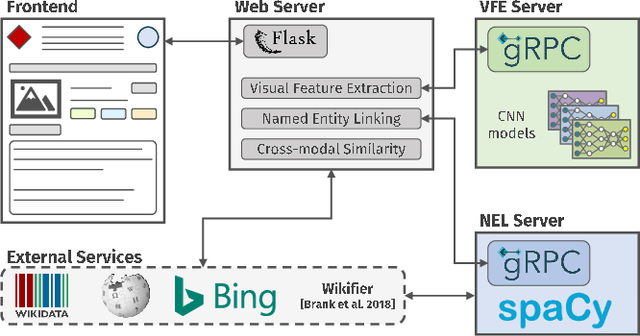
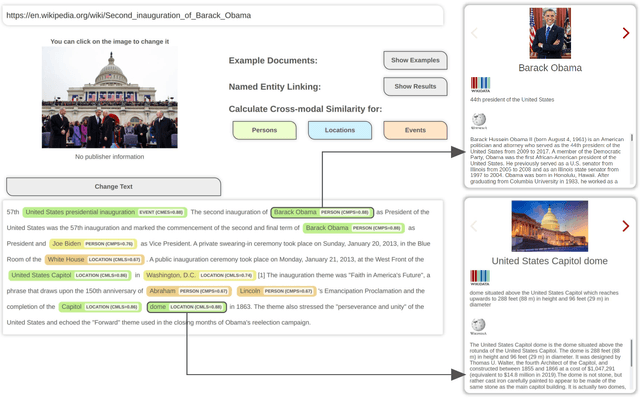
The World Wide Web and social media platforms have become popular sources for news and information. Typically, multimodal information, e.g., image and text is used to convey information more effectively and to attract attention. While in most cases image content is decorative or depicts additional information, it has also been leveraged to spread misinformation and rumors in recent years. In this paper, we present a Web-based demo application that automatically quantifies the cross-modal relations of entities (persons, locations, and events) in image and text. The applications are manifold. For example, the system can help users to explore multimodal articles more efficiently, or can assist human assessors and fact-checking efforts in the verification of the credibility of news stories, tweets, or other multimodal documents.
Ontology-driven Event Type Classification in Images
Nov 09, 2020

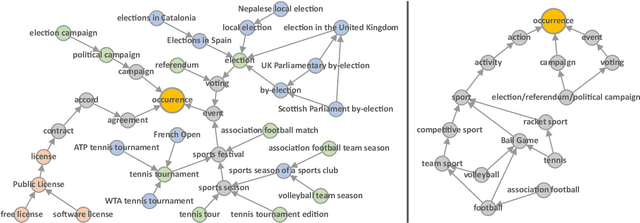

Event classification can add valuable information for semantic search and the increasingly important topic of fact validation in news. So far, only few approaches address image classification for newsworthy event types such as natural disasters, sports events, or elections. Previous work distinguishes only between a limited number of event types and relies on rather small datasets for training. In this paper, we present a novel ontology-driven approach for the classification of event types in images. We leverage a large number of real-world news events to pursue two objectives: First, we create an ontology based on Wikidata comprising the majority of event types. Second, we introduce a novel large-scale dataset that was acquired through Web crawling. Several baselines are proposed including an ontology-driven learning approach that aims to exploit structured information of a knowledge graph to learn relevant event relations using deep neural networks. Experimental results on existing as well as novel benchmark datasets demonstrate the superiority of the proposed ontology-driven approach.