 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Explainability of Vision-Language Models in Art History
Feb 24, 2026Vision-Language Models (VLMs) transfer visual and textual data into a shared embedding space. In so doing, they enable a wide range of multimodal tasks, while also raising critical questions about the nature of machine 'understanding.' In this paper, we examine how Explainable Artificial Intelligence (XAI) methods can render the visual reasoning of a VLM - namely, CLIP - legible in art-historical contexts. To this end, we evaluate seven methods, combining zero-shot localization experiments with human interpretability studies. Our results indicate that, while these methods capture some aspects of human interpretation, their effectiveness hinges on the conceptual stability and representational availability of the examined categories.
A Dataset for Named Entity Recognition and Relation Extraction from Art-historical Image Descriptions
Feb 22, 2026This paper introduces FRAME (Fine-grained Recognition of Art-historical Metadata and Entities), a manually annotated dataset of art-historical image descriptions for Named Entity Recognition (NER) and Relation Extraction (RE). Descriptions were collected from museum catalogs, auction listings, open-access platforms, and scholarly databases, then filtered to ensure that each text focuses on a single artwork and contains explicit statements about its material, composition, or iconography. FRAME provides stand-off annotations in three layers: a metadata layer for object-level properties, a content layer for depicted subjects and motifs, and a co-reference layer linking repeated mentions. Across layers, entity spans are labeled with 37 types and connected by typed RE links between mentions. Entity types are aligned with Wikidata to support Named Entity Linking (NEL) and downstream knowledge-graph construction. The dataset is released as UIMA XMI Common Analysis Structure (CAS) files with accompanying images and bibliographic metadata, and can be used to benchmark and fine-tune NER and RE systems, including zero- and few-shot setups with Large Language Models (LLMs).
Poses of People in Art: A Data Set for Human Pose Estimation in Digital Art History
Jan 12, 2023



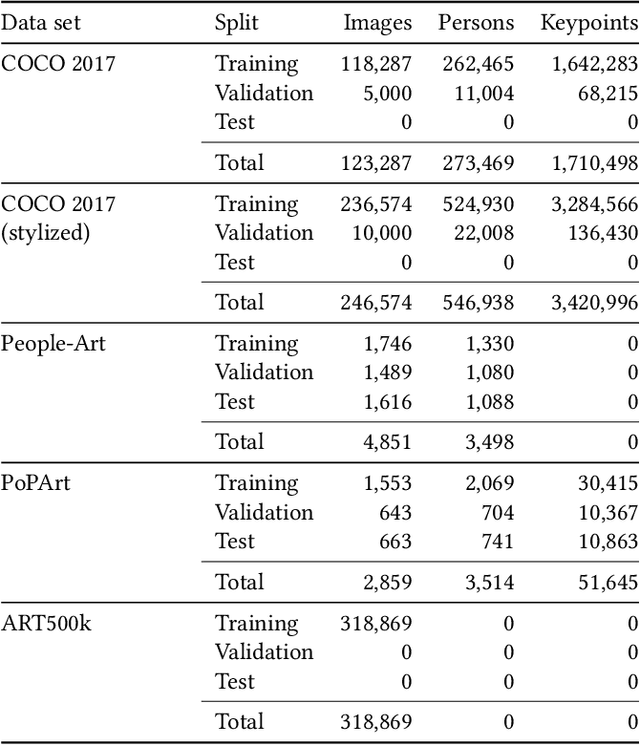
Throughout the history of art, the pose, as the holistic abstraction of the human body's expression, has proven to be a constant in numerous studies. However, due to the enormous amount of data that so far had to be processed by hand, its crucial role to the formulaic recapitulation of art-historical motifs since antiquity could only be highlighted selectively. This is true even for the now automated estimation of human poses, as domain-specific, sufficiently large data sets required for training computational models are either not publicly available or not indexed at a fine enough granularity. With the Poses of People in Art data set, we introduce the first openly licensed data set for estimating human poses in art and validating human pose estimators. It consists of 2,454 images from 22 art-historical depiction styles, including those that have increasingly turned away from lifelike representations of the body since the 19th century. A total of 10,749 human figures are precisely enclosed by rectangular bounding boxes, with a maximum of four per image labeled by up to 17 keypoints; among these are mainly joints such as elbows and knees. For machine learning purposes, the data set is divided into three subsets, training, validation, and testing, that follow the established JSON-based Microsoft COCO format, respectively. Each image annotation, in addition to mandatory fields, provides metadata from the art-historical online encyclopedia WikiArt. With this paper, we elaborate on the acquisition and constitution of the data set, address various application scenarios, and discuss prospects for a digitally supported art history. We show that the data set enables the investigation of body phenomena in art, whether at the level of individual figures, which can be captured in their subtleties, or entire figure constellations, whose position, distance, or proximity to one another is considered.
Semi-supervised Human Pose Estimation in Art-historical Images
Jul 11, 2022

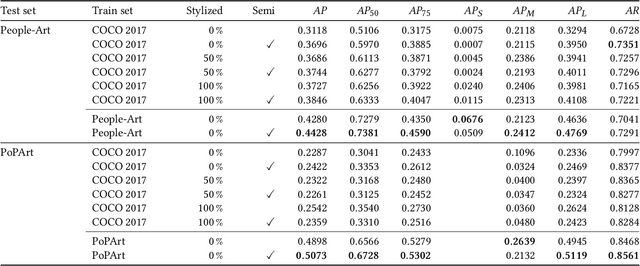
Gesture as language of non-verbal communication has been theoretically established since the 17th century. However, its relevance for the visual arts has been expressed only sporadically. This may be primarily due to the sheer overwhelming amount of data that traditionally had to be processed by hand. With the steady progress of digitization, though, a growing number of historical artifacts have been indexed and made available to the public, creating a need for automatic retrieval of art-historical motifs with similar body constellations or poses. Since the domain of art differs significantly from existing real-world data sets for human pose estimation due to its style variance, this presents new challenges. In this paper, we propose a novel approach to estimate human poses in art-historical images. In contrast to previous work that attempts to bridge the domain gap with pre-trained models or through style transfer, we suggest semi-supervised learning for both object and keypoint detection. Furthermore, we introduce a novel domain-specific art data set that includes both bounding box and keypoint annotations of human figures. Our approach achieves significantly better results than methods that use pre-trained models or style transfer.
iART: A Search Engine for Art-Historical Images to Support Research in the Humanities
Aug 03, 2021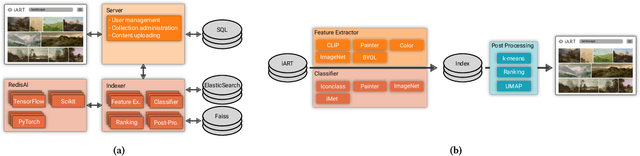
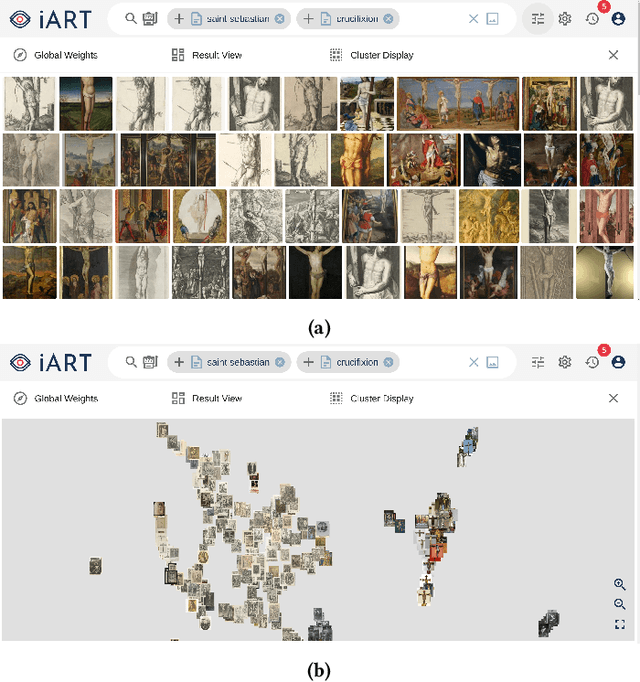
In this paper, we introduce iART: an open Web platform for art-historical research that facilitates the process of comparative vision. The system integrates various machine learning techniques for keyword- and content-based image retrieval as well as category formation via clustering. An intuitive GUI supports users to define queries and explore results. By using a state-of-the-art cross-modal deep learning approach, it is possible to search for concepts that were not previously detected by trained classification models. Art-historical objects from large, openly licensed collections such as Amsterdam Rijksmuseum and Wikidata are made available to users.