 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Value of Agent-Generated Tests for LLM-Based Software Engineering Agents
Feb 08, 2026Large Language Model (LLM) code agents increasingly resolve repository-level issues by iteratively editing code, invoking tools, and validating candidate patches. In these workflows, agents often write tests on the fly, a paradigm adopted by many high-ranking agents on the SWE-bench leaderboard. However, we observe that GPT-5.2, which writes almost no new tests, can even achieve performance comparable to top-ranking agents. This raises the critical question: whether such tests meaningfully improve issue resolution or merely mimic human testing practices while consuming a substantial interaction budget. To reveal the impact of agent-written tests, we present an empirical study that analyzes agent trajectories across six state-of-the-art LLMs on SWE-bench Verified. Our results show that while test writing is commonly adopted, but resolved and unresolved tasks within the same model exhibit similar test-writing frequencies Furthermore, these tests typically serve as observational feedback channels, where agents prefer value-revealing print statements significantly more than formal assertion-based checks. Based on these insights, we perform a controlled experiment by revising the prompts of four agents to either increase or reduce test writing. The results suggest that changes in the volume of agent-written tests do not significantly change final outcomes. Taken together, our study reveals that current test-writing practices may provide marginal utility in autonomous software engineering tasks.
Runtime Anomaly Detection for Drones: An Integrated Rule-Mining and Unsupervised-Learning Approach
May 03, 2025UAVs, commonly referred to as drones, have witnessed a remarkable surge in popularity due to their versatile applications. These cyber-physical systems depend on multiple sensor inputs, such as cameras, GPS receivers, accelerometers, and gyroscopes, with faults potentially leading to physical instability and serious safety concerns. To mitigate such risks, anomaly detection has emerged as a crucial safeguarding mechanism, capable of identifying the physical manifestations of emerging issues and allowing operators to take preemptive action at runtime. Recent anomaly detection methods based on LSTM neural networks have shown promising results, but three challenges persist: the need for models that can generalise across the diverse mission profiles of drones; the need for interpretability, enabling operators to understand the nature of detected problems; and the need for capturing domain knowledge that is difficult to infer solely from log data. Motivated by these challenges, this paper introduces RADD, an integrated approach to anomaly detection in drones that combines rule mining and unsupervised learning. In particular, we leverage rules (or invariants) to capture expected relationships between sensors and actuators during missions, and utilise unsupervised learning techniques to cover more subtle relationships that the rules may have missed. We implement this approach using the ArduPilot drone software in the Gazebo simulator, utilising 44 rules derived across the main phases of drone missions, in conjunction with an ensemble of five unsupervised learning models. We find that our integrated approach successfully detects 93.84% of anomalies over six types of faults with a low false positive rate (2.33%), and can be deployed effectively at runtime. Furthermore, RADD outperforms a state-of-the-art LSTM-based method in detecting the different types of faults evaluated in our study.
Unveiling Pitfalls: Understanding Why AI-driven Code Agents Fail at GitHub Issue Resolution
Mar 16, 2025



AI-driven software development has rapidly advanced with the emergence of software development agents that leverage large language models (LLMs) to tackle complex, repository-level software engineering tasks. These agents go beyond just generation of final code; they engage in multi-step reasoning, utilize various tools for code modification and debugging, and interact with execution environments to diagnose and iteratively resolve issues. However, most existing evaluations focus primarily on static analyses of final code outputs, yielding limited insights into the agents' dynamic problem-solving processes. To fill this gap, we conduct an in-depth empirical study on 3,977 solving-phase trajectories and 3,931 testing-phase logs from 8 top-ranked agents evaluated on 500 GitHub issues in the SWE-Bench benchmark. Our exploratory analysis shows that Python execution errors during the issue resolution phase correlate with lower resolution rates and increased reasoning overheads. We have identified the most prevalent errors -- such as ModuleNotFoundError and TypeError -- and highlighted particularly challenging errors like OSError and database-related issues (e.g., IntegrityError) that demand significantly more debugging effort. Furthermore, we have discovered 3 bugs in the SWE-Bench platform that affect benchmark fairness and accuracy; these issues have been reported to and confirmed by the maintainers. To promote transparency and foster future research, we publicly share our datasets and analysis scripts.
Transducer Tuning: Efficient Model Adaptation for Software Tasks Using Code Property Graphs
Dec 18, 2024
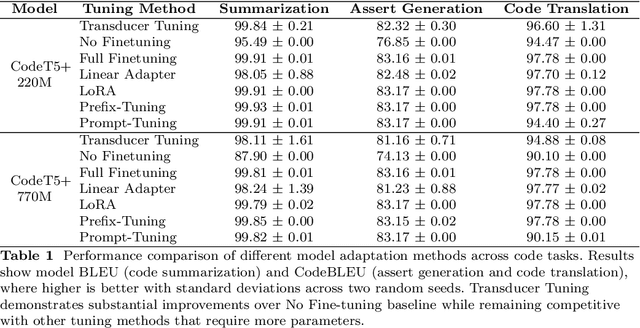
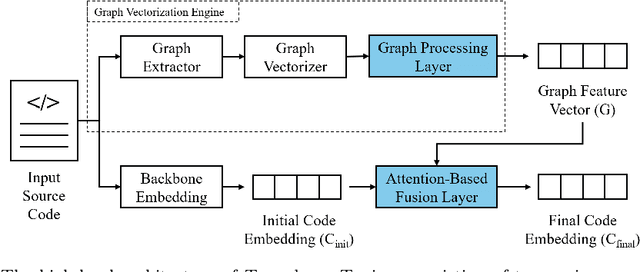
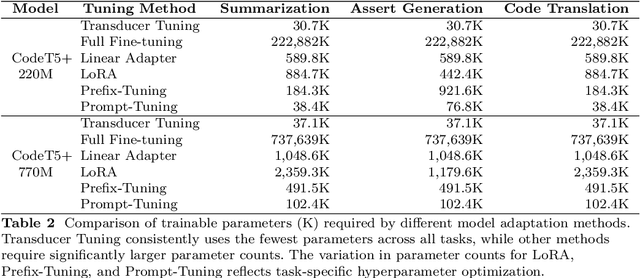
Large language models have demonstrated promising performance across various software engineering tasks. While fine-tuning is a common practice to adapt these models for downstream tasks, it becomes challenging in resource-constrained environments due to increased memory requirements from growing trainable parameters in increasingly large language models. We introduce \approach, a technique to adapt large models for downstream code tasks using Code Property Graphs (CPGs). Our approach introduces a modular component called \transducer that enriches code embeddings with structural and dependency information from CPGs. The Transducer comprises two key components: Graph Vectorization Engine (GVE) and Attention-Based Fusion Layer (ABFL). GVE extracts CPGs from input source code and transforms them into graph feature vectors. ABFL then fuses those graphs feature vectors with initial code embeddings from a large language model. By optimizing these transducers for different downstream tasks, our approach enhances the models without the need to fine-tune them for specific tasks. We have evaluated \approach on three downstream tasks: code summarization, assert generation, and code translation. Our results demonstrate competitive performance compared to full parameter fine-tuning while reducing up to 99\% trainable parameters to save memory. \approach also remains competitive against other fine-tuning approaches (e.g., LoRA, Prompt-Tuning, Prefix-Tuning) while using only 1.5\%-80\% of their trainable parameters. Our findings show that integrating structural and dependency information through Transducer Tuning enables more efficient model adaptation, making it easier for users to adapt large models in resource-constrained settings.
Evaluating Software Development Agents: Patch Patterns, Code Quality, and Issue Complexity in Real-World GitHub Scenarios
Oct 16, 2024In recent years, AI-based software engineering has progressed from pre-trained models to advanced agentic workflows, with Software Development Agents representing the next major leap. These agents, capable of reasoning, planning, and interacting with external environments, offer promising solutions to complex software engineering tasks. However, while much research has evaluated code generated by large language models (LLMs), comprehensive studies on agent-generated patches, particularly in real-world settings, are lacking. This study addresses that gap by evaluating 4,892 patches from 10 top-ranked agents on 500 real-world GitHub issues from SWE-Bench Verified, focusing on their impact on code quality. Our analysis shows no single agent dominated, with 170 issues unresolved, indicating room for improvement. Even for patches that passed unit tests and resolved issues, agents made different file and function modifications compared to the gold patches from repository developers, revealing limitations in the benchmark's test case coverage. Most agents maintained code reliability and security, avoiding new bugs or vulnerabilities; while some agents increased code complexity, many reduced code duplication and minimized code smells. Finally, agents performed better on simpler codebases, suggesting that breaking complex tasks into smaller sub-tasks could improve effectiveness. This study provides the first comprehensive evaluation of agent-generated patches on real-world GitHub issues, offering insights to advance AI-driven software development.
Promise and Peril of Collaborative Code Generation Models: Balancing Effectiveness and Memorization
Sep 18, 2024In the rapidly evolving field of machine learning, training models with datasets from various locations and organizations presents significant challenges due to privacy and legal concerns. The exploration of effective collaborative training settings capable of leveraging valuable knowledge from distributed and isolated datasets is increasingly crucial. This study investigates key factors that impact the effectiveness of collaborative training methods in code next-token prediction, as well as the correctness and utility of the generated code, demonstrating the promise of such methods. Additionally, we evaluate the memorization of different participant training data across various collaborative training settings, including centralized, federated, and incremental training, highlighting their potential risks in leaking data. Our findings indicate that the size and diversity of code datasets are pivotal factors influencing the success of collaboratively trained code models. We show that federated learning achieves competitive performance compared to centralized training while offering better data protection, as evidenced by lower memorization ratios in the generated code. However, federated learning can still produce verbatim code snippets from hidden training data, potentially violating privacy or copyright. Our study further explores effectiveness and memorization patterns in incremental learning, emphasizing the sequence in which individual participant datasets are introduced. We also identify cross-organizational clones as a prevalent challenge in both centralized and federated learning scenarios. Our findings highlight the persistent risk of data leakage during inference, even when training data remains unseen. We conclude with recommendations for practitioners and researchers to optimize multisource datasets, propelling cross-organizational collaboration forward.
Your Instructions Are Not Always Helpful: Assessing the Efficacy of Instruction Fine-tuning for Software Vulnerability Detection
Jan 15, 2024Software, while beneficial, poses potential cybersecurity risks due to inherent vulnerabilities. Detecting these vulnerabilities is crucial, and deep learning has shown promise as an effective tool for this task due to its ability to perform well without extensive feature engineering. However, a challenge in deploying deep learning for vulnerability detection is the limited availability of training data. Recent research highlights the deep learning efficacy in diverse tasks. This success is attributed to instruction fine-tuning, a technique that remains under-explored in the context of vulnerability detection. This paper investigates the capability of models, specifically a recent language model, to generalize beyond the programming languages used in their training data. It also examines the role of natural language instructions in enhancing this generalization. Our study evaluates the model performance on a real-world dataset to predict vulnerable code. We present key insights and lessons learned, contributing to understanding the deep learning application in software vulnerability detection.
MANDO: Multi-Level Heterogeneous Graph Embeddings for Fine-Grained Detection of Smart Contract Vulnerabilities
Aug 28, 2022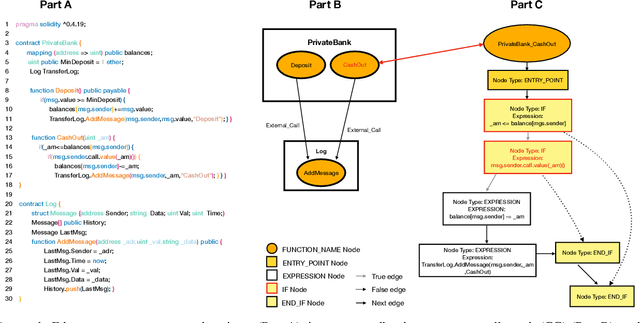
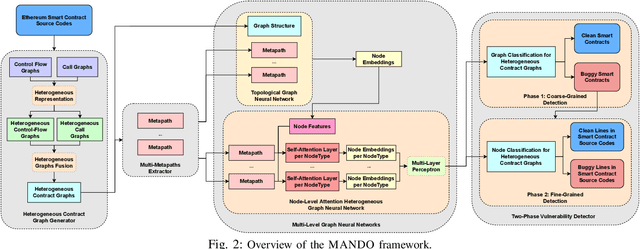
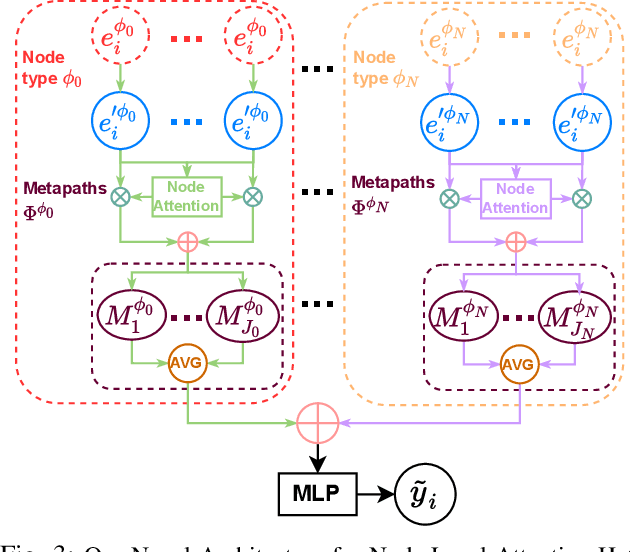

Learning heterogeneous graphs consisting of different types of nodes and edges enhances the results of homogeneous graph techniques. An interesting example of such graphs is control-flow graphs representing possible software code execution flows. As such graphs represent more semantic information of code, developing techniques and tools for such graphs can be highly beneficial for detecting vulnerabilities in software for its reliability. However, existing heterogeneous graph techniques are still insufficient in handling complex graphs where the number of different types of nodes and edges is large and variable. This paper concentrates on the Ethereum smart contracts as a sample of software codes represented by heterogeneous contract graphs built upon both control-flow graphs and call graphs containing different types of nodes and links. We propose MANDO, a new heterogeneous graph representation to learn such heterogeneous contract graphs' structures. MANDO extracts customized metapaths, which compose relational connections between different types of nodes and their neighbors. Moreover, it develops a multi-metapath heterogeneous graph attention network to learn multi-level embeddings of different types of nodes and their metapaths in the heterogeneous contract graphs, which can capture the code semantics of smart contracts more accurately and facilitate both fine-grained line-level and coarse-grained contract-level vulnerability detection. Our extensive evaluation of large smart contract datasets shows that MANDO improves the vulnerability detection results of other techniques at the coarse-grained contract level. More importantly, it is the first learning-based approach capable of identifying vulnerabilities at the fine-grained line-level, and significantly improves the traditional code analysis-based vulnerability detection approaches by 11.35% to 70.81% in terms of F1-score.
Investigating Math Word Problems using Pretrained Multilingual Language Models
May 19, 2021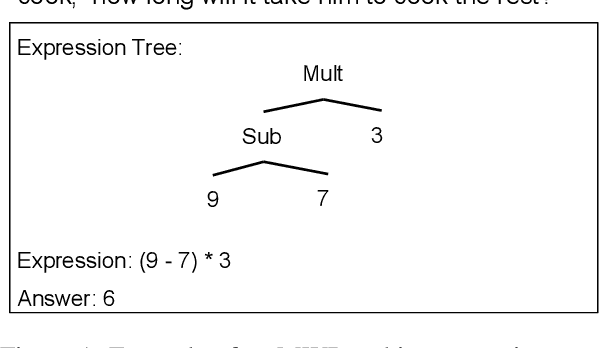
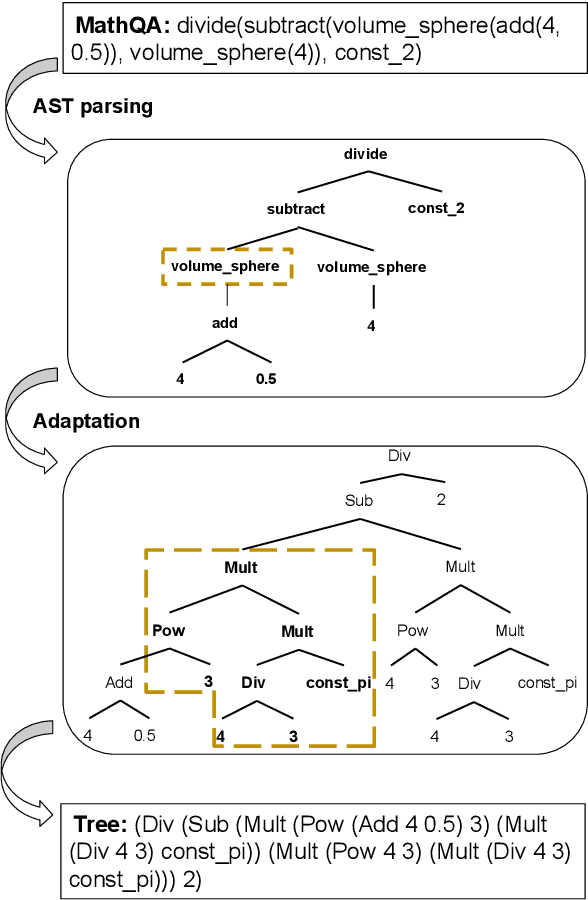
In this paper, we revisit math word problems~(MWPs) from the cross-lingual and multilingual perspective. We construct our MWP solvers over pretrained multilingual language models using sequence-to-sequence model with copy mechanism. We compare how the MWP solvers perform in cross-lingual and multilingual scenarios. To facilitate the comparison of cross-lingual performance, we first adapt the large-scale English dataset MathQA as a counterpart of the Chinese dataset Math23K. Then we extend several English datasets to bilingual datasets through machine translation plus human annotation. Our experiments show that the MWP solvers may not be transferred to a different language even if the target expressions have the same operator set and constants. But for both cross-lingual and multilingual cases, it can be better generalized if problem types exist on both source language and target language.
InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees
Dec 15, 2020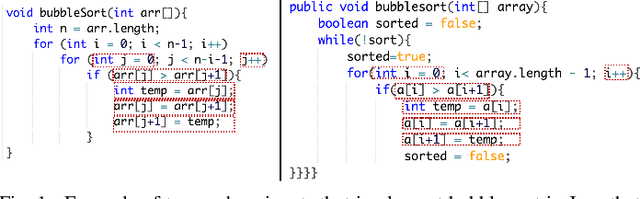

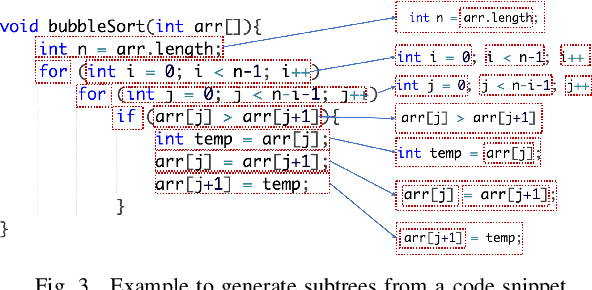
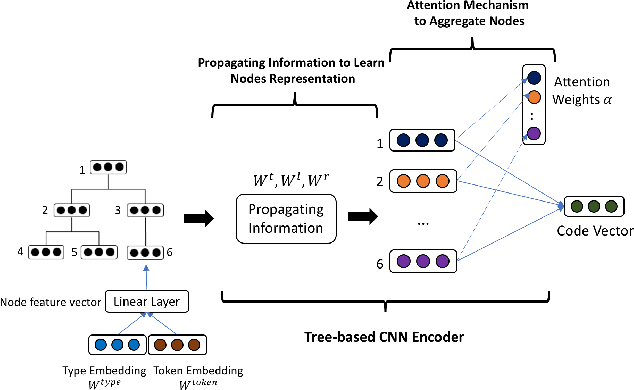
Building deep learning models on source code has found many successful software engineering applications, such as code search, code comment generation, bug detection, code migration, and so on. Current learning techniques, however, have a major drawback that these models are mostly trained on datasets labeled for particular downstream tasks, and code representations may not be suitable for other tasks. While some techniques produce representations from unlabeled code, they are far from satisfactory when applied to downstream tasks. Although certain techniques generate representations from unlabeled code when applied to downstream tasks they are far from satisfactory. This paper proposes InferCode to overcome the limitation by adapting the self-supervised learning mechanism to build source code model. The key novelty lies in training code representations by predicting automatically identified subtrees from the context of the ASTs. Subtrees in ASTs are treated with InferCode as the labels for training code representations without any human labeling effort or the overhead of expensive graph construction, and the trained representations are no longer tied to any specific downstream tasks or code units. We trained an InferCode model instance using the Tree-based CNN as the encoder of a large set of Java code and applied it to downstream unsupervised tasks such as code clustering, code clone detection, cross-language code search or reused under a transfer learning scheme to continue training the model weights for supervised tasks such as code classification and method name prediction. Compared to previous code learning techniques applied to the same downstream tasks, such as Code2Vec, Code2Seq, ASTNN, higher performance results are achieved using our pre-trained InferCode model with a significant margin for most tasks including those involving different programming languages.