 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Goals to Aspects, Revisited: An NFR Pattern Language for Agentic AI Systems
Feb 28, 2026Agentic AI systems exhibit numerous crosscutting concerns -- security, observability, cost management, fault tolerance -- that are poorly modularized in current implementations, contributing to the high failure rate of AI projects in reaching production. The goals-to-aspects methodology proposed at RE 2004 demonstrated that aspects can be systematically discovered from i* goal models by identifying non-functional soft-goals that crosscut functional goals. This paper revisits and extends that methodology to the agentic AI domain. We present a pattern language of 12 reusable patterns organized across four NFR categories (security, reliability, observability, cost management), each mapping an i* goal model to a concrete aspect implementation using an AOP framework for Rust. Four patterns address agent-specific crosscutting concerns absent from traditional AOP literature: tool-scope sandboxing, prompt injection detection, token budget management, and action audit trails. We extend the V-graph model to capture how agent tasks simultaneously contribute to functional goals and non-functional soft-goals. We validate the pattern language through a case study analyzing an open-source autonomous agent framework, demonstrating how goal-driven aspect discovery systematically identifies and modularizes crosscutting concerns. The pattern language offers a principled approach for engineering reliable agentic AI systems through early identification of crosscutting concerns.
Energy-bounded Learning for Robust Models of Code
Dec 20, 2021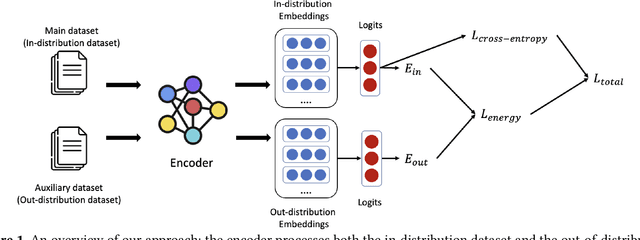



In programming, learning code representations has a variety of applications, including code classification, code search, comment generation, bug prediction, and so on. Various representations of code in terms of tokens, syntax trees, dependency graphs, code navigation paths, or a combination of their variants have been proposed, however, existing vanilla learning techniques have a major limitation in robustness, i.e., it is easy for the models to make incorrect predictions when the inputs are altered in a subtle way. To enhance the robustness, existing approaches focus on recognizing adversarial samples rather than on the valid samples that fall outside a given distribution, which we refer to as out-of-distribution (OOD) samples. Recognizing such OOD samples is the novel problem investigated in this paper. To this end, we propose to first augment the in=distribution datasets with out-of-distribution samples such that, when trained together, they will enhance the model's robustness. We propose the use of an energy-bounded learning objective function to assign a higher score to in-distribution samples and a lower score to out-of-distribution samples in order to incorporate such out-of-distribution samples into the training process of source code models. In terms of OOD detection and adversarial samples detection, our evaluation results demonstrate a greater robustness for existing source code models to become more accurate at recognizing OOD data while being more resistant to adversarial attacks at the same time. Furthermore, the proposed energy-bounded score outperforms all existing OOD detection scores by a large margin, including the softmax confidence score, the Mahalanobis score, and ODIN.
Quantum Cognitively Motivated Decision Fusion for Video Sentiment Analysis
Jan 12, 2021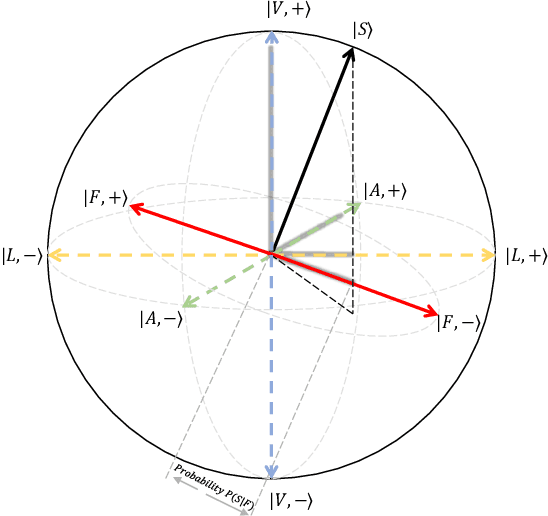
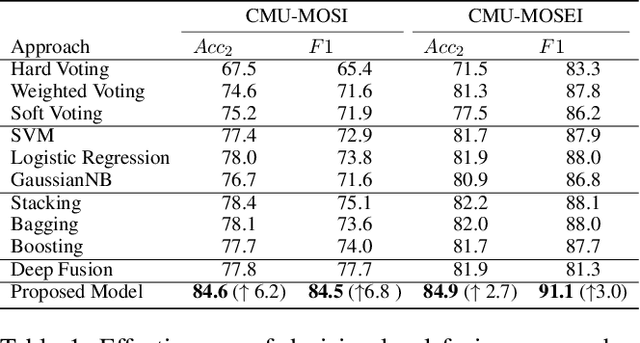
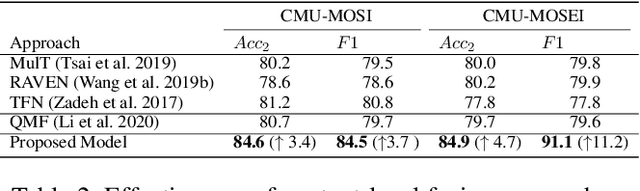
Video sentiment analysis as a decision-making process is inherently complex, involving the fusion of decisions from multiple modalities and the so-caused cognitive biases. Inspired by recent advances in quantum cognition, we show that the sentiment judgment from one modality could be incompatible with the judgment from another, i.e., the order matters and they cannot be jointly measured to produce a final decision. Thus the cognitive process exhibits "quantum-like" biases that cannot be captured by classical probability theories. Accordingly, we propose a fundamentally new, quantum cognitively motivated fusion strategy for predicting sentiment judgments. In particular, we formulate utterances as quantum superposition states of positive and negative sentiment judgments, and uni-modal classifiers as mutually incompatible observables, on a complex-valued Hilbert space with positive-operator valued measures. Experiments on two benchmarking datasets illustrate that our model significantly outperforms various existing decision level and a range of state-of-the-art content-level fusion approaches. The results also show that the concept of incompatibility allows effective handling of all combination patterns, including those extreme cases that are wrongly predicted by all uni-modal classifiers.
InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees
Dec 15, 2020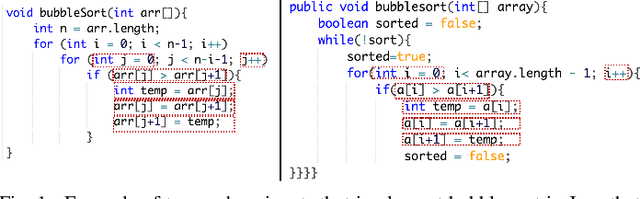

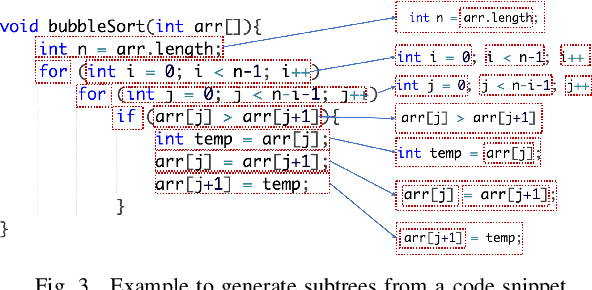
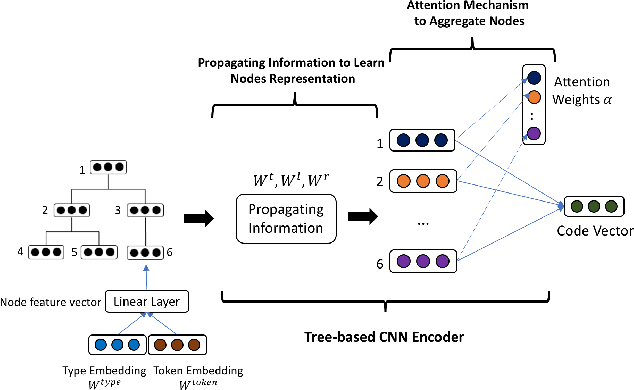
Building deep learning models on source code has found many successful software engineering applications, such as code search, code comment generation, bug detection, code migration, and so on. Current learning techniques, however, have a major drawback that these models are mostly trained on datasets labeled for particular downstream tasks, and code representations may not be suitable for other tasks. While some techniques produce representations from unlabeled code, they are far from satisfactory when applied to downstream tasks. Although certain techniques generate representations from unlabeled code when applied to downstream tasks they are far from satisfactory. This paper proposes InferCode to overcome the limitation by adapting the self-supervised learning mechanism to build source code model. The key novelty lies in training code representations by predicting automatically identified subtrees from the context of the ASTs. Subtrees in ASTs are treated with InferCode as the labels for training code representations without any human labeling effort or the overhead of expensive graph construction, and the trained representations are no longer tied to any specific downstream tasks or code units. We trained an InferCode model instance using the Tree-based CNN as the encoder of a large set of Java code and applied it to downstream unsupervised tasks such as code clustering, code clone detection, cross-language code search or reused under a transfer learning scheme to continue training the model weights for supervised tasks such as code classification and method name prediction. Compared to previous code learning techniques applied to the same downstream tasks, such as Code2Vec, Code2Seq, ASTNN, higher performance results are achieved using our pre-trained InferCode model with a significant margin for most tasks including those involving different programming languages.
TreeCaps: Tree-Based Capsule Networks for Source Code Processing
Sep 05, 2020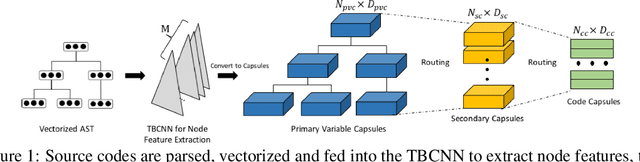
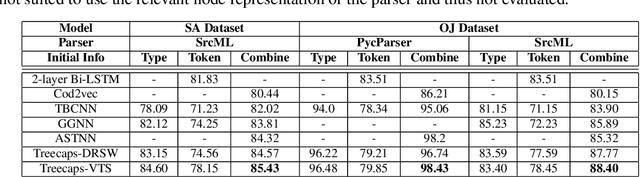
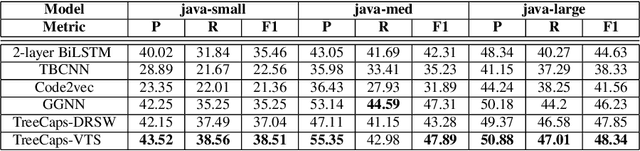
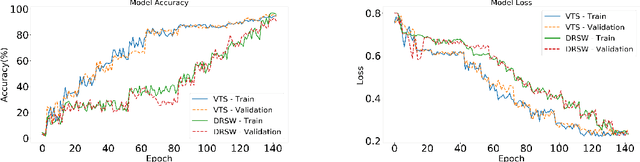
Recently program learning techniques have been proposed to process source code based on syntactical structures (e.g., Abstract Syntax Trees) and/or semantic information (e.g., Dependency Graphs). Although graphs may be better at capturing various viewpoints of code semantics than trees, constructing graph inputs from code needs static code semantic analysis that may not be accurate and introduces noise during learning. Although syntax trees are precisely defined according to the language grammar and easier to construct and process than graphs, previous tree-based learning techniques have not been able to learn semantic information from trees to achieve better accuracy than graph-based techniques. We propose a new learning technique, named TreeCaps, by fusing together capsule networks with tree-based convolutional neural networks, to achieve learning accuracy higher than existing graph-based techniques while it is based only on trees. TreeCaps introduces novel variable-to-static routing algorithms into the capsule networks to compensate for the loss of previous routing algorithms. Aside from accuracy, we also find that TreeCaps is the most robust to withstand those semantic-preserving program transformations that change code syntax without modifying the semantics. Evaluated on a large number of Java and C/C++ programs, TreeCaps models outperform prior deep learning models of program source code, in terms of both accuracy and robustness for program comprehension tasks such as code functionality classification and function name prediction
On the Generalizability of Neural Program Analyzers with respect to Semantic-Preserving Program Transformations
Jul 31, 2020
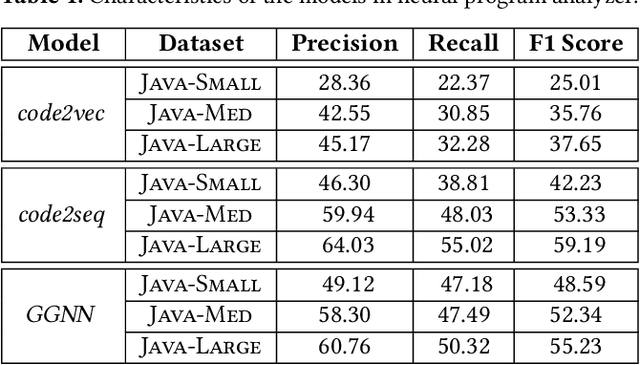
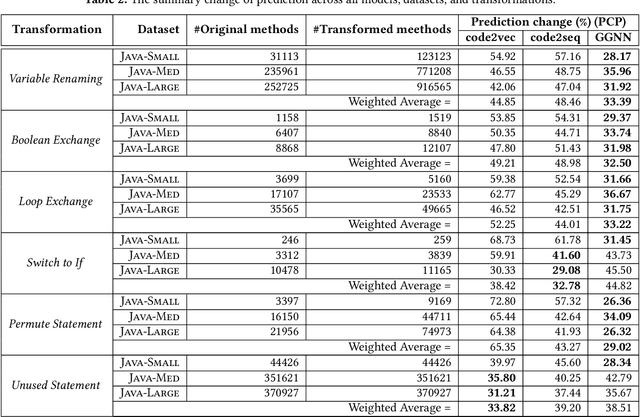
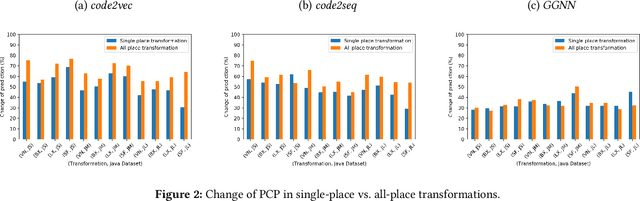
With the prevalence of publicly available source code repositories to train deep neural network models, neural program analyzers can do well in source code analysis tasks such as predicting method names in given programs that cannot be easily done by traditional program analyzers. Although such analyzers have been tested on various existing datasets, the extent in which they generalize to unforeseen source code is largely unknown. Since it is impossible to test neural program analyzers on all unforeseen programs, in this paper, we propose to evaluate the generalizability of neural program analyzers with respect to semantic-preserving transformations: a generalizable neural program analyzer should perform equally well on programs that are of the same semantics but of different lexical appearances and syntactical structures. More specifically, we compare the results of various neural program analyzers for the method name prediction task on programs before and after automated semantic-preserving transformations. We use three Java datasets of different sizes and three state-of-the-art neural network models for code, namely code2vec, code2seq, and Gated Graph Neural Networks (GGNN), to build nine such neural program analyzers for evaluation. Our results show that even with small semantically preserving changes to the programs, these neural program analyzers often fail to generalize their performance. Our results also suggest that neural program analyzers based on data and control dependencies in programs generalize better than neural program analyzers based only on abstract syntax trees. On the positive side, we observe that as the size of training dataset grows and diversifies the generalizability of correct predictions produced by the analyzers can be improved too.
SAR: Learning Cross-Language API Mappings with Little Knowledge
Jun 10, 2019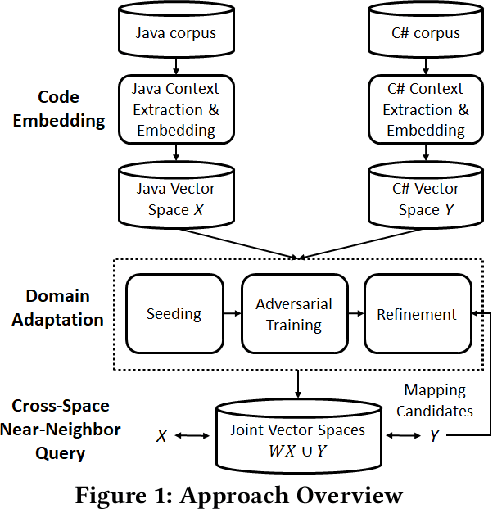
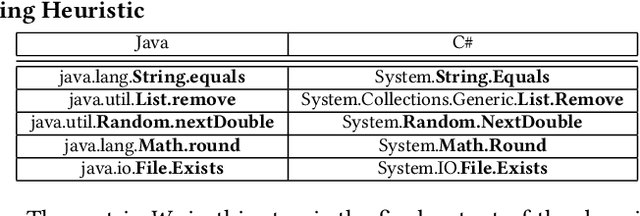
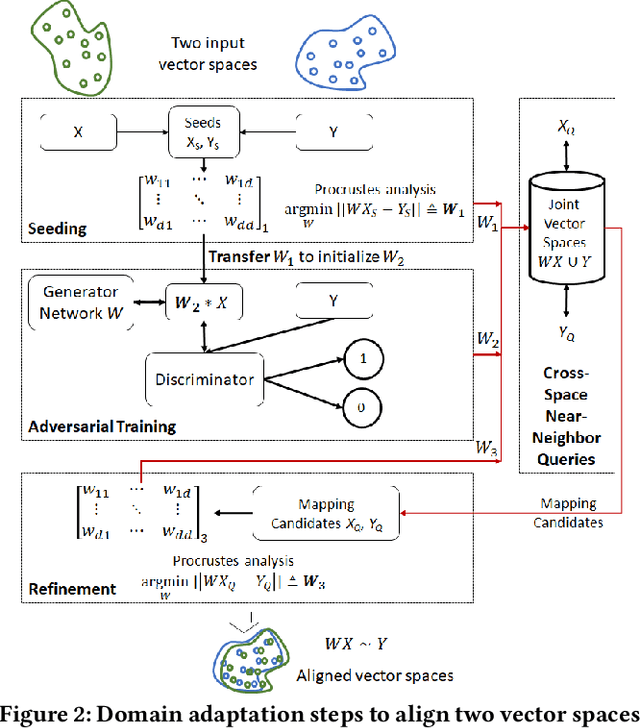
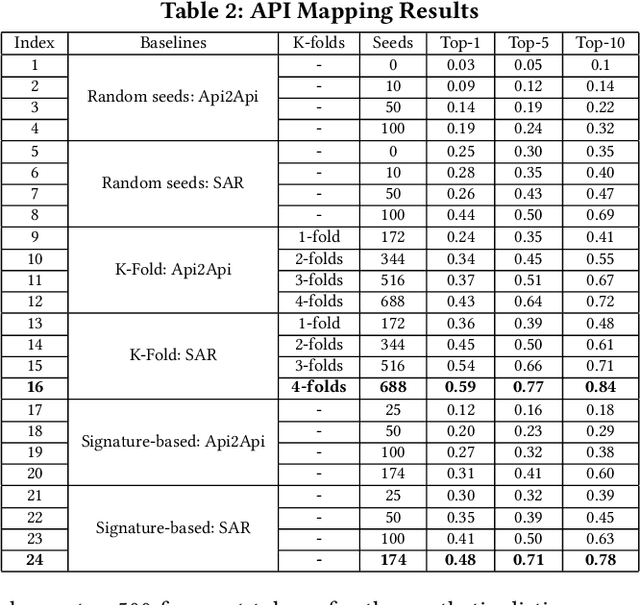
To save manual effort, developers often translate programs from one programming language to another, instead of implementing it from scratch. Translating application program interfaces (APIs) used in one language to functionally equivalent ones available in another language is an important aspect of program translation. Existing approaches facilitate the translation by automatically identifying the API mappings across programming languages. However, all these approaches still require large amount of manual effort in preparing parallel program corpora, ranging from pairs of APIs, to manually identified code in different languages that are considered as functionally equivalent. To minimize the manual effort in identifying parallel program corpora and API mappings, this paper aims at an automated approach to map APIs across languages with much less knowledge a priori needed than other existing approaches. The approach is based on an realization of the notion of domain adaption combined with code embedding, which can better align two vector spaces: taking as input large sets of programs, our approach first generates numeric vector representations of the programs, especially the APIs used in each language, and it adapts generative adversarial networks (GAN) to align the vectors from the spaces of two languages. For a better alignment, we initialize the GAN with parameters derived from optional API mapping seeds that can be identified accurately with a simple automatic signature-based matching heuristic. Then the cross-language API mappings can be identified via nearest-neighbors queries in the aligned vector spaces.
Cross-Language Learning for Program Classification using Bilateral Tree-Based Convolutional Neural Networks
Nov 29, 2017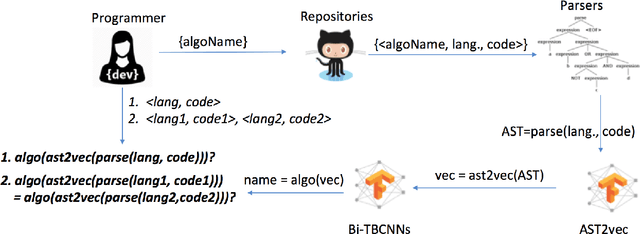

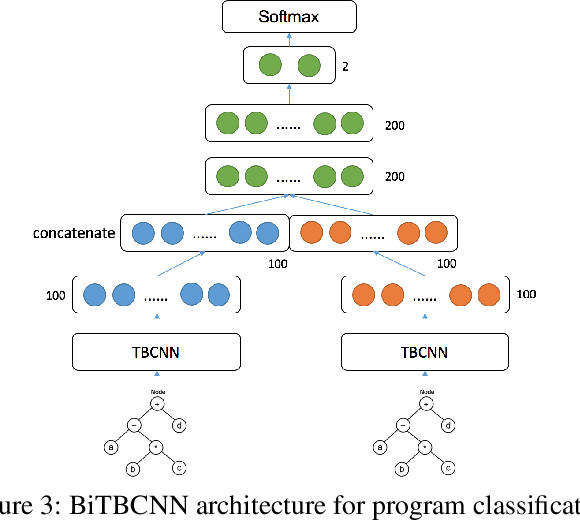
Towards the vision of translating code that implements an algorithm from one programming language into another, this paper proposes an approach for automated program classification using bilateral tree-based convolutional neural networks (BiTBCNNs). It is layered on top of two tree-based convolutional neural networks (TBCNNs), each of which recognizes the algorithm of code written in an individual programming language. The combination layer of the networks recognizes the similarities and differences among code in different programming languages. The BiTBCNNs are trained using the source code in different languages but known to implement the same algorithms and/or functionalities. For a preliminary evaluation, we use 3591 Java and 3534 C++ code snippets from 6 algorithms we crawled systematically from GitHub. We obtained over 90% accuracy in the cross-language binary classification task to tell whether any given two code snippets implement the same algorithm. Also, for the algorithm classification task, i.e., to predict which one of the six algorithm labels is implemented by an arbitrary C++ code snippet, we achieved over 80% precision.