 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback-aligned Mixed LLMs for Machine Language-Molecule Translation
May 22, 2024The intersection of chemistry and Artificial Intelligence (AI) is an active area of research focused on accelerating scientific discovery. While using large language models (LLMs) with scientific modalities has shown potential, there are significant challenges to address, such as improving training efficiency and dealing with the out-of-distribution problem. Focussing on the task of automated language-molecule translation, we are the first to use state-of-the art (SOTA) human-centric optimisation algorithms in the cross-modal setting, successfully aligning cross-language-molecule modals. We empirically show that we can augment the capabilities of scientific LLMs without the need for extensive data or large models. We conduct experiments using only 10% of the available data to mitigate memorisation effects associated with training large models on extensive datasets. We achieve significant performance gains, surpassing the best benchmark model trained on extensive in-distribution data by a large margin and reach new SOTA levels. Additionally we are the first to propose employing non-linear fusion for mixing cross-modal LLMs which further boosts performance gains without increasing training costs or data needs. Finally, we introduce a fine-grained, domain-agnostic evaluation method to assess hallucination in LLMs and promote responsible use.
ALMol: Aligned Language-Molecule Translation LLMs through Offline Preference Contrastive Optimisation
May 15, 2024The field of chemistry and Artificial Intelligence (AI) intersection is an area of active research that aims to accelerate scientific discovery. The integration of large language models (LLMs) with scientific modalities has shown significant promise in this endeavour. However, challenges persist in effectively addressing training efficacy and the out-of-distribution problem, particularly as existing approaches rely on larger models and datasets. In this context, we focus on machine language-molecule translation and deploy a novel training approach called contrastive preference optimisation, which avoids generating translations that are merely adequate but not perfect. To ensure generalisability and mitigate memorisation effects, we conduct experiments using only 10\% of the data. Our results demonstrate that our models achieve up to a 32\% improvement compared to counterpart models. We also introduce a scalable fine-grained evaluation methodology that accommodates responsibility.
Reformulating NLP tasks to Capture Longitudinal Manifestation of Language Disorders in People with Dementia
Oct 15, 2023



Dementia is associated with language disorders which impede communication. Here, we automatically learn linguistic disorder patterns by making use of a moderately-sized pre-trained language model and forcing it to focus on reformulated natural language processing (NLP) tasks and associated linguistic patterns. Our experiments show that NLP tasks that encapsulate contextual information and enhance the gradient signal with linguistic patterns benefit performance. We then use the probability estimates from the best model to construct digital linguistic markers measuring the overall quality in communication and the intensity of a variety of language disorders. We investigate how the digital markers characterize dementia speech from a longitudinal perspective. We find that our proposed communication marker is able to robustly and reliably characterize the language of people with dementia, outperforming existing linguistic approaches; and shows external validity via significant correlation with clinical markers of behaviour. Finally, our proposed linguistic disorder markers provide useful insights into gradual language impairment associated with disease progression.
A Digital Language Coherence Marker for Monitoring Dementia
Oct 14, 2023



The use of spontaneous language to derive appropriate digital markers has become an emergent, promising and non-intrusive method to diagnose and monitor dementia. Here we propose methods to capture language coherence as a cost-effective, human-interpretable digital marker for monitoring cognitive changes in people with dementia. We introduce a novel task to learn the temporal logical consistency of utterances in short transcribed narratives and investigate a range of neural approaches. We compare such language coherence patterns between people with dementia and healthy controls and conduct a longitudinal evaluation against three clinical bio-markers to investigate the reliability of our proposed digital coherence marker. The coherence marker shows a significant difference between people with mild cognitive impairment, those with Alzheimer's Disease and healthy controls. Moreover our analysis shows high association between the coherence marker and the clinical bio-markers as well as generalisability potential to other related conditions.
A Longitudinal Multi-modal Dataset for Dementia Monitoring and Diagnosis
Sep 03, 2021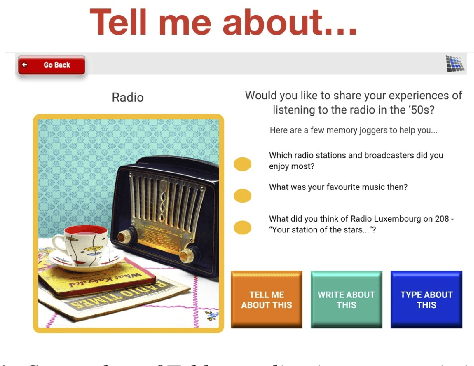
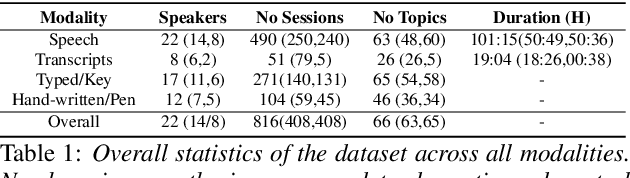
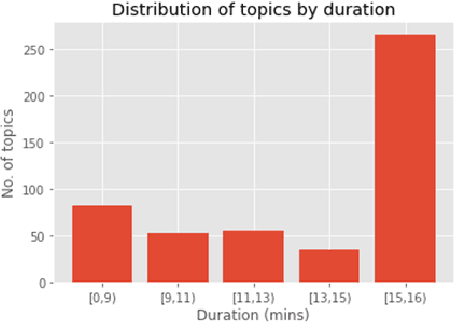
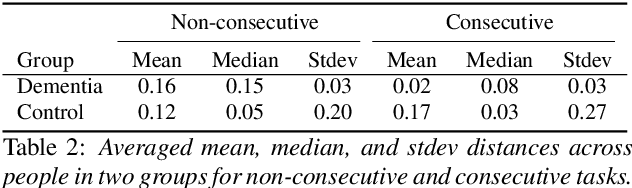
Dementia is a family of neurogenerative conditions affecting memory and cognition in an increasing number of individuals in our globally aging population. Automated analysis of language, speech and paralinguistic indicators have been gaining popularity as potential indicators of cognitive decline. Here we propose a novel longitudinal multi-modal dataset collected from people with mild dementia and age matched controls over a period of several months in a natural setting. The multi-modal data consists of spoken conversations, a subset of which are transcribed, as well as typed and written thoughts and associated extra-linguistic information such as pen strokes and keystrokes. We describe the dataset in detail and proceed to focus on a task using the speech modality. The latter involves distinguishing controls from people with dementia by exploiting the longitudinal nature of the data. Our experiments showed significant differences in how the speech varied from session to session in the control and dementia groups.
Quantum Cognitively Motivated Decision Fusion for Video Sentiment Analysis
Jan 12, 2021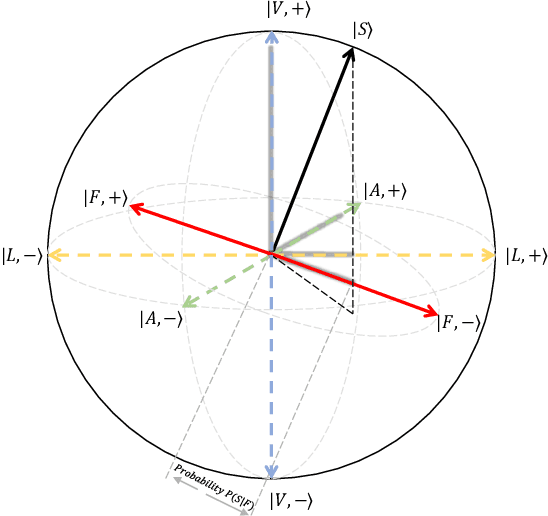
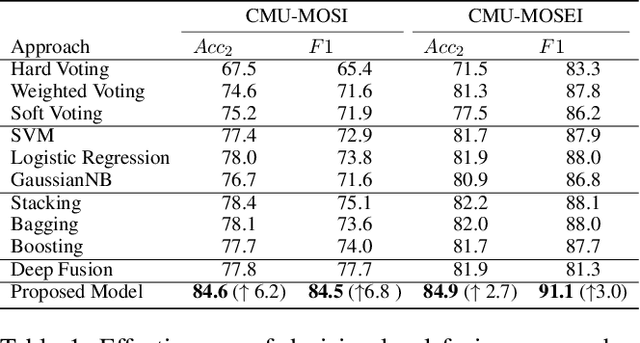
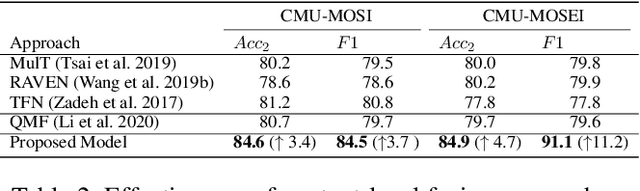
Video sentiment analysis as a decision-making process is inherently complex, involving the fusion of decisions from multiple modalities and the so-caused cognitive biases. Inspired by recent advances in quantum cognition, we show that the sentiment judgment from one modality could be incompatible with the judgment from another, i.e., the order matters and they cannot be jointly measured to produce a final decision. Thus the cognitive process exhibits "quantum-like" biases that cannot be captured by classical probability theories. Accordingly, we propose a fundamentally new, quantum cognitively motivated fusion strategy for predicting sentiment judgments. In particular, we formulate utterances as quantum superposition states of positive and negative sentiment judgments, and uni-modal classifiers as mutually incompatible observables, on a complex-valued Hilbert space with positive-operator valued measures. Experiments on two benchmarking datasets illustrate that our model significantly outperforms various existing decision level and a range of state-of-the-art content-level fusion approaches. The results also show that the concept of incompatibility allows effective handling of all combination patterns, including those extreme cases that are wrongly predicted by all uni-modal classifiers.