 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Cognitively Motivated Decision Fusion for Video Sentiment Analysis
Jan 12, 2021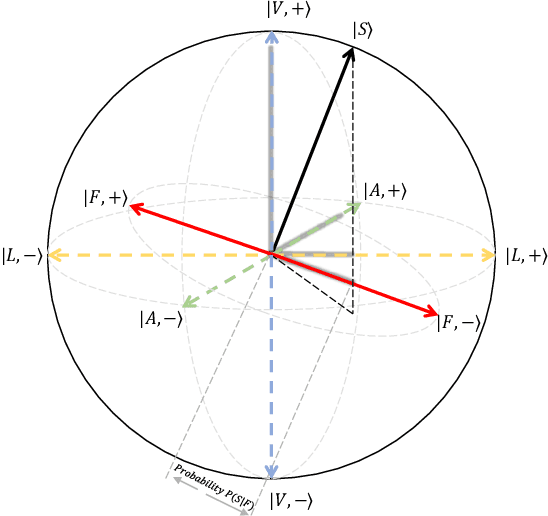
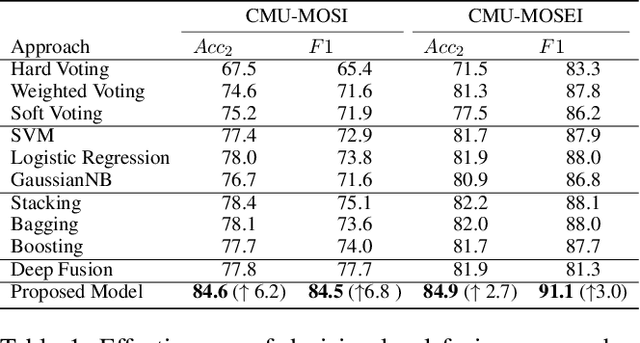
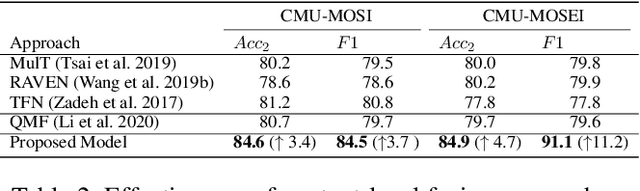
Video sentiment analysis as a decision-making process is inherently complex, involving the fusion of decisions from multiple modalities and the so-caused cognitive biases. Inspired by recent advances in quantum cognition, we show that the sentiment judgment from one modality could be incompatible with the judgment from another, i.e., the order matters and they cannot be jointly measured to produce a final decision. Thus the cognitive process exhibits "quantum-like" biases that cannot be captured by classical probability theories. Accordingly, we propose a fundamentally new, quantum cognitively motivated fusion strategy for predicting sentiment judgments. In particular, we formulate utterances as quantum superposition states of positive and negative sentiment judgments, and uni-modal classifiers as mutually incompatible observables, on a complex-valued Hilbert space with positive-operator valued measures. Experiments on two benchmarking datasets illustrate that our model significantly outperforms various existing decision level and a range of state-of-the-art content-level fusion approaches. The results also show that the concept of incompatibility allows effective handling of all combination patterns, including those extreme cases that are wrongly predicted by all uni-modal classifiers.
Kernel Method based on Non-Linear Coherent State
Jul 15, 2020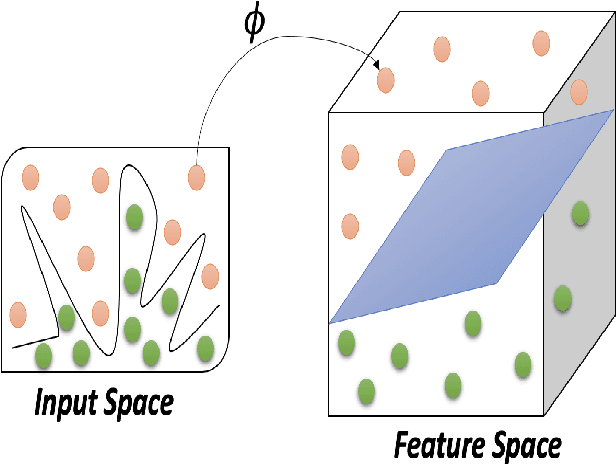
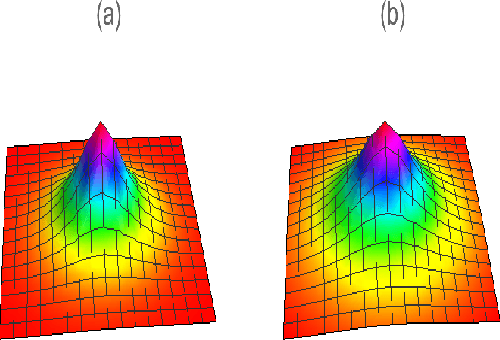
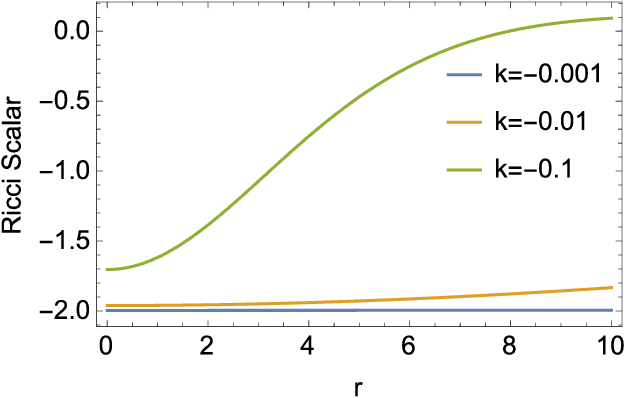
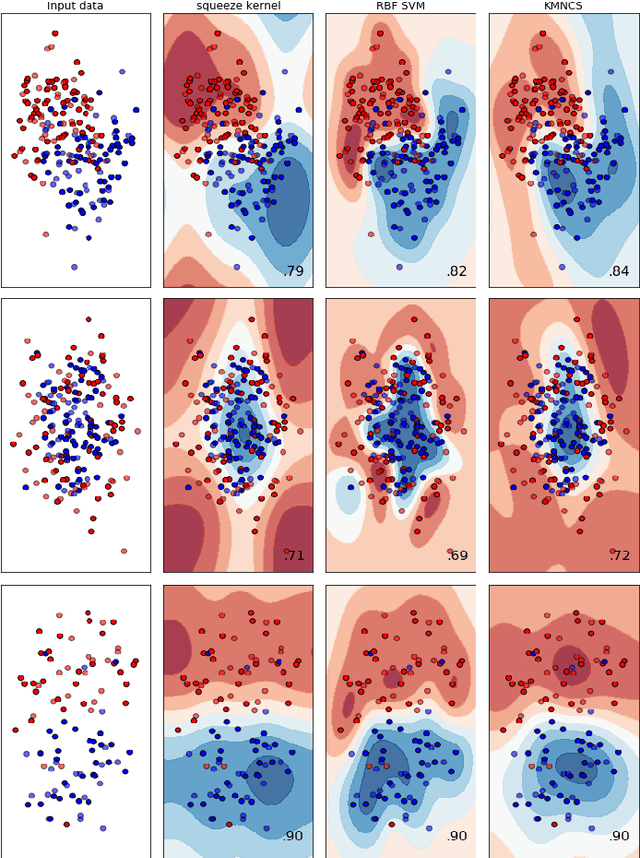
In this paper, by mapping datasets to a set of non-linear coherent states, the process of encoding inputs in quantum states as a non-linear feature map is re-interpreted. As a result of this fact that the Radial Basis Function is recovered when data is mapped to a complex Hilbert state represented by coherent states, non-linear coherent states can be considered as natural generalisation of associated kernels. By considering the non-linear coherent states of a quantum oscillator with variable mass, we propose a kernel function based on generalized hypergeometric functions, as orthogonal polynomial functions. The suggested kernel is implemented with support vector machine on two well known datasets (make circles, and make moons) and outperforms the baselines, even in the presence of high noise. In addition, we study impact of geometrical properties of feature space, obtaining by non-linear coherent states, on the SVM classification task, by using considering the Fubini-Study metric of associated coherent states.
CNM: An Interpretable Complex-valued Network for Matching
Apr 10, 2019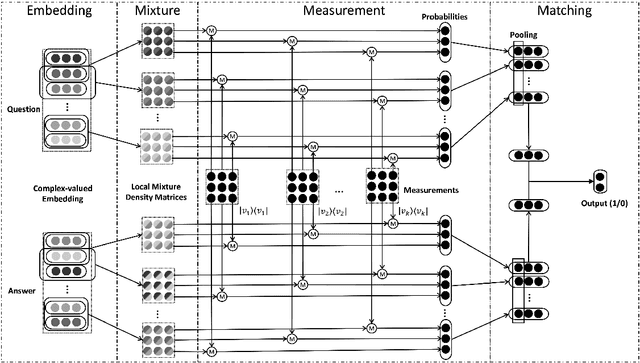
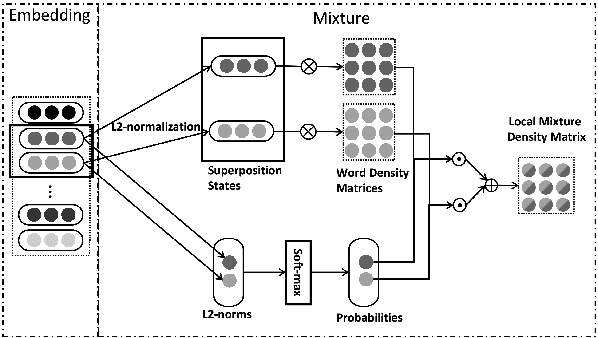
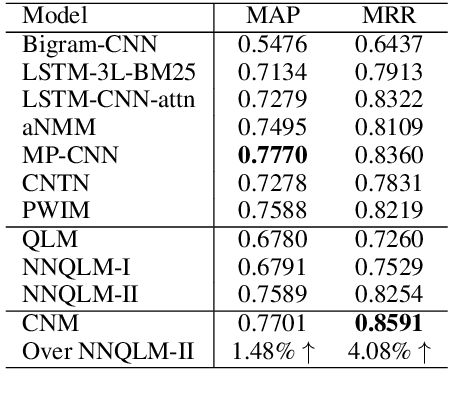
This paper seeks to model human language by the mathematical framework of quantum physics. With the well-designed mathematical formulations in quantum physics, this framework unifies different linguistic units in a single complex-valued vector space, e.g. words as particles in quantum states and sentences as mixed systems. A complex-valued network is built to implement this framework for semantic matching. With well-constrained complex-valued components, the network admits interpretations to explicit physical meanings. The proposed complex-valued network for matching (CNM) achieves comparable performances to strong CNN and RNN baselines on two benchmarking question answering (QA) datasets.
Binary Classifier Inspired by Quantum Theory
Mar 04, 2019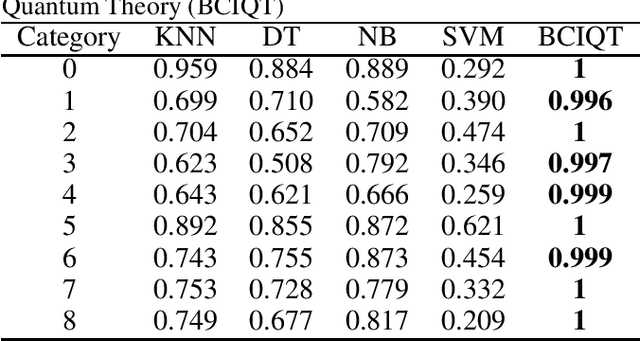
Machine Learning (ML) helps us to recognize patterns from raw data. ML is used in numerous domains i.e. biomedical, agricultural, food technology, etc. Despite recent technological advancements, there is still room for substantial improvement in prediction. Current ML models are based on classical theories of probability and statistics, which can now be replaced by Quantum Theory (QT) with the aim of improving the effectiveness of ML. In this paper, we propose the Binary Classifier Inspired by Quantum Theory (BCIQT) model, which outperforms the state of the art classification in terms of recall for every category.
Semantic Hilbert Space for Text Representation Learning
Feb 26, 2019

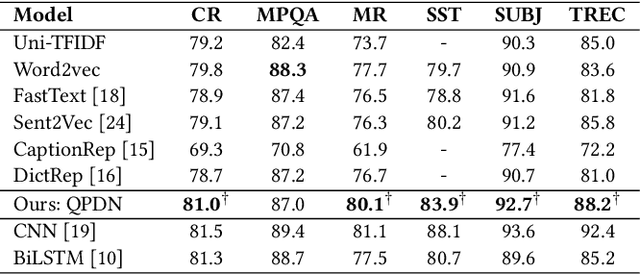
Capturing the meaning of sentences has long been a challenging task. Current models tend to apply linear combinations of word features to conduct semantic composition for bigger-granularity units e.g. phrases, sentences, and documents. However, the semantic linearity does not always hold in human language. For instance, the meaning of the phrase `ivory tower' can not be deduced by linearly combining the meanings of `ivory' and `tower'. To address this issue, we propose a new framework that models different levels of semantic units (e.g. sememe, word, sentence, and semantic abstraction) on a single \textit{Semantic Hilbert Space}, which naturally admits a non-linear semantic composition by means of a complex-valued vector word representation. An end-to-end neural network~\footnote{https://github.com/wabyking/qnn} is proposed to implement the framework in the text classification task, and evaluation results on six benchmarking text classification datasets demonstrate the effectiveness, robustness and self-explanation power of the proposed model. Furthermore, intuitive case studies are conducted to help end users to understand how the framework works.
Multi-class Classification Model Inspired by Quantum Detection Theory
Oct 10, 2018Machine Learning has become very famous currently which assist in identifying the patterns from the raw data. Technological advancement has led to substantial improvement in Machine Learning which, thus helping to improve prediction. Current Machine Learning models are based on Classical Theory, which can be replaced by Quantum Theory to improve the effectiveness of the model. In the previous work, we developed binary classifier inspired by Quantum Detection Theory. In this extended abstract, our main goal is to develop multi-class classifier. We generally use the terminology multinomial classification or multi-class classification when we have a classification problem for classifying observations or instances into one of three or more classes.
Probability Ranking in Vector Spaces
Aug 30, 2011
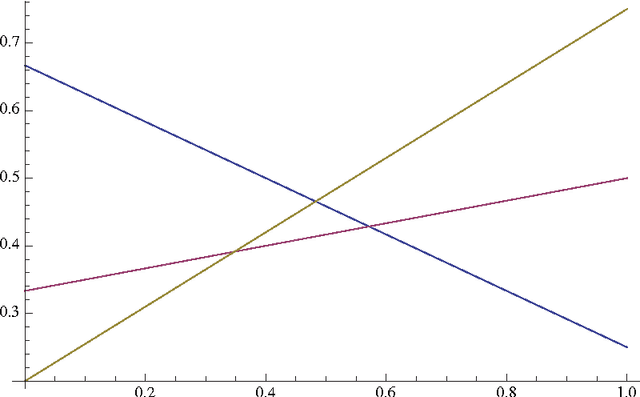
The Probability Ranking Principle states that the document set with the highest values of probability of relevance optimizes information retrieval effectiveness given the probabilities are estimated as accurately as possible. The key point of the principle is the separation of the document set into two subsets with a given level of fallout and with the highest recall. The paper introduces the separation between two vector subspaces and shows that the separation yields a more effective performance than the optimal separation into subsets with the same available evidence, the performance being measured with recall and fallout. The result is proved mathematically and exemplified experimentally.
Getting Beyond the State of the Art of Information Retrieval with Quantum Theory
Aug 29, 2011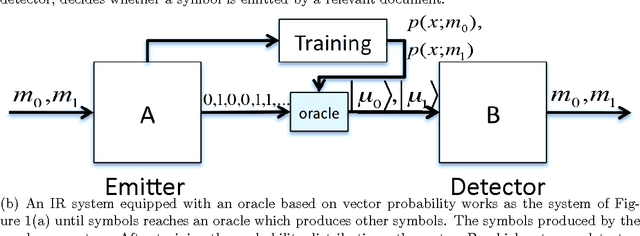
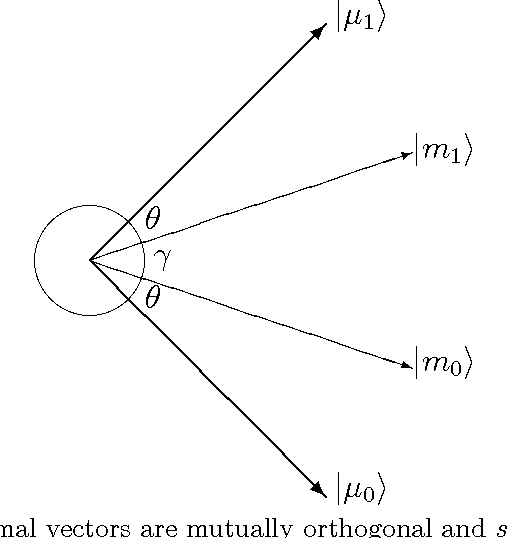
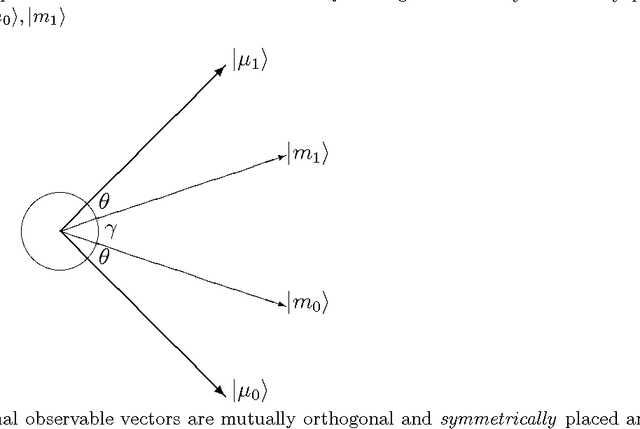
According to the probability ranking principle, the document set with the highest values of probability of relevance optimizes information retrieval effectiveness given the probabilities are estimated as accurately as possible. The key point of this principle is the separation of the document set into two subsets with a given level of fallout and with the highest recall. If subsets of set measures are replaced by subspaces and space measures, we obtain an alternative theory stemming from Quantum Theory. That theory is named after vector probability because vectors represent event like sets do in classical probability. The paper shows that the separation into vector subspaces is more effective than the separation into subsets with the same available evidence. The result is proved mathematically and verified experimentally. In general, the paper suggests that quantum theory is not only a source of rhetoric inspiration, but is a sufficient condition to improve retrieval effectiveness in a principled way.
Improving Ranking Using Quantum Probability
Aug 28, 2011
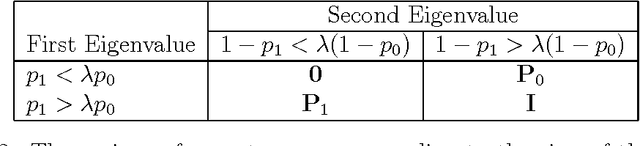
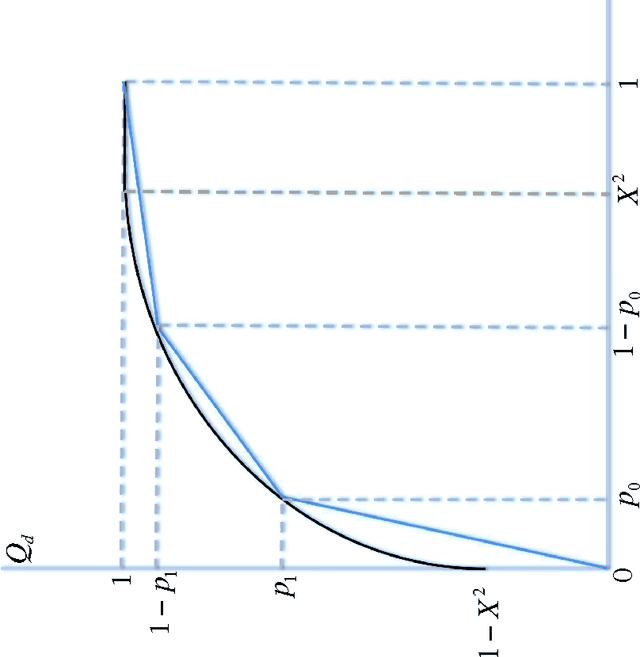
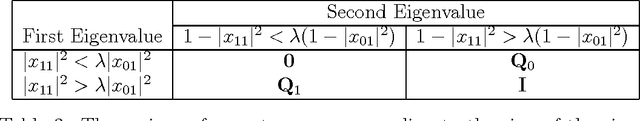
The paper shows that ranking information units by quantum probability differs from ranking them by classical probability provided the same data used for parameter estimation. As probability of detection (also known as recall or power) and probability of false alarm (also known as fallout or size) measure the quality of ranking, we point out and show that ranking by quantum probability yields higher probability of detection than ranking by classical probability provided a given probability of false alarm and the same parameter estimation data. As quantum probability provided more effective detectors than classical probability within other domains that data management, we conjecture that, the system that can implement subspace-based detectors shall be more effective than a system which implements a set-based detectors, the effectiveness being calculated as expected recall estimated over the probability of detection and expected fallout estimated over the probability of false alarm.