 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Longitudinal Multi-modal Dataset for Dementia Monitoring and Diagnosis
Paper and Code
Sep 03, 2021
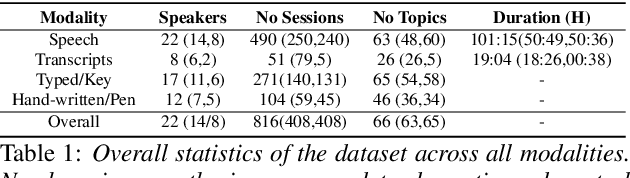
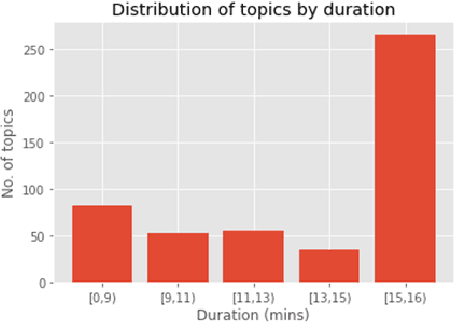
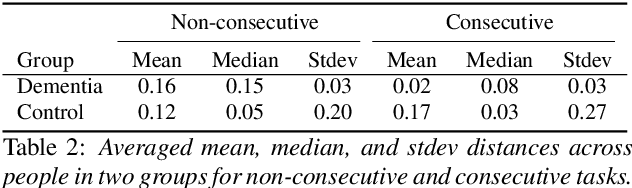
Dementia is a family of neurogenerative conditions affecting memory and cognition in an increasing number of individuals in our globally aging population. Automated analysis of language, speech and paralinguistic indicators have been gaining popularity as potential indicators of cognitive decline. Here we propose a novel longitudinal multi-modal dataset collected from people with mild dementia and age matched controls over a period of several months in a natural setting. The multi-modal data consists of spoken conversations, a subset of which are transcribed, as well as typed and written thoughts and associated extra-linguistic information such as pen strokes and keystrokes. We describe the dataset in detail and proceed to focus on a task using the speech modality. The latter involves distinguishing controls from people with dementia by exploiting the longitudinal nature of the data. Our experiments showed significant differences in how the speech varied from session to session in the control and dementia groups.