 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalizability of Neural Program Analyzers with respect to Semantic-Preserving Program Transformations
Jul 31, 2020
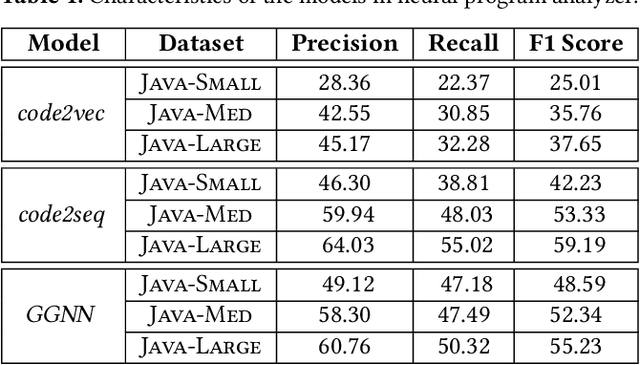
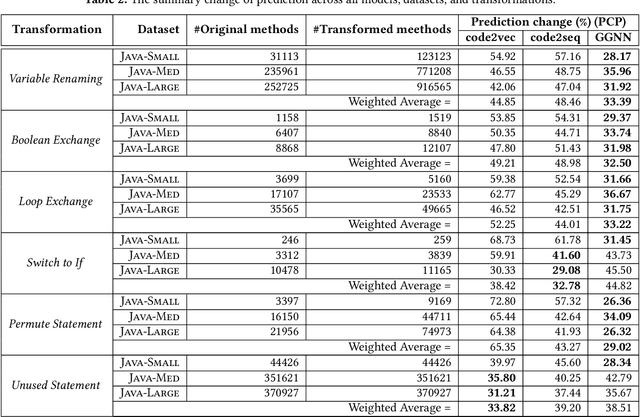
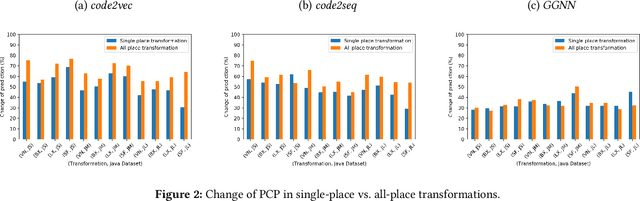
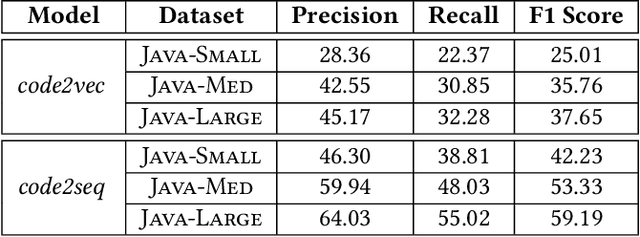
With the prevalence of publicly available source code repositories to train deep neural network models, neural program analyzers can do well in source code analysis tasks such as predicting method names in given programs that cannot be easily done by traditional program analyzers. Although such analyzers have been tested on various existing datasets, the extent in which they generalize to unforeseen source code is largely unknown. Since it is impossible to test neural program analyzers on all unforeseen programs, in this paper, we propose to evaluate the generalizability of neural program analyzers with respect to semantic-preserving transformations: a generalizable neural program analyzer should perform equally well on programs that are of the same semantics but of different lexical appearances and syntactical structures. More specifically, we compare the results of various neural program analyzers for the method name prediction task on programs before and after automated semantic-preserving transformations. We use three Java datasets of different sizes and three state-of-the-art neural network models for code, namely code2vec, code2seq, and Gated Graph Neural Networks (GGNN), to build nine such neural program analyzers for evaluation. Our results show that even with small semantically preserving changes to the programs, these neural program analyzers often fail to generalize their performance. Our results also suggest that neural program analyzers based on data and control dependencies in programs generalize better than neural program analyzers based only on abstract syntax trees. On the positive side, we observe that as the size of training dataset grows and diversifies the generalizability of correct predictions produced by the analyzers can be improved too.
Evaluation of Generalizability of Neural Program Analyzers under Semantic-Preserving Transformations
Apr 15, 2020


The abundance of publicly available source code repositories, in conjunction with the advances in neural networks, has enabled data-driven approaches to program analysis. These approaches, called neural program analyzers, use neural networks to extract patterns in the programs for tasks ranging from development productivity to program reasoning. Despite the growing popularity of neural program analyzers, the extent to which their results are generalizable is unknown. In this paper, we perform a large-scale evaluation of the generalizability of two popular neural program analyzers using seven semantically-equivalent transformations of programs. Our results caution that in many cases the neural program analyzers fail to generalize well, sometimes to programs with negligible textual differences. The results provide the initial stepping stones for quantifying robustness in neural program analyzers.