 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOL: Reducing the Maintenance Overhead for Integrating Hardware Support into AI Frameworks
Paper and Code
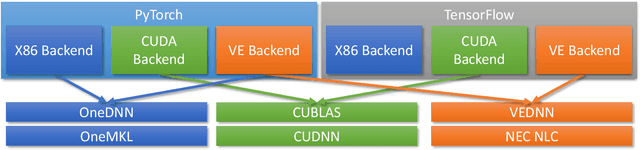
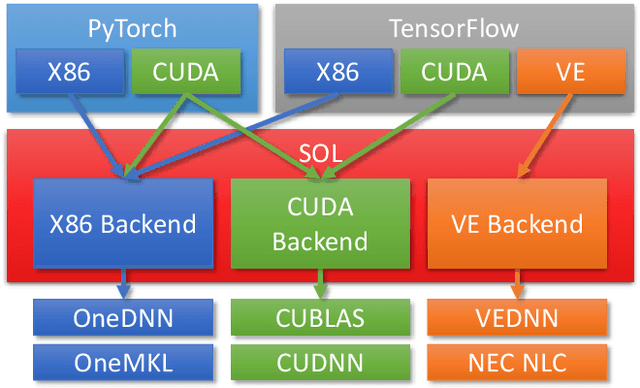
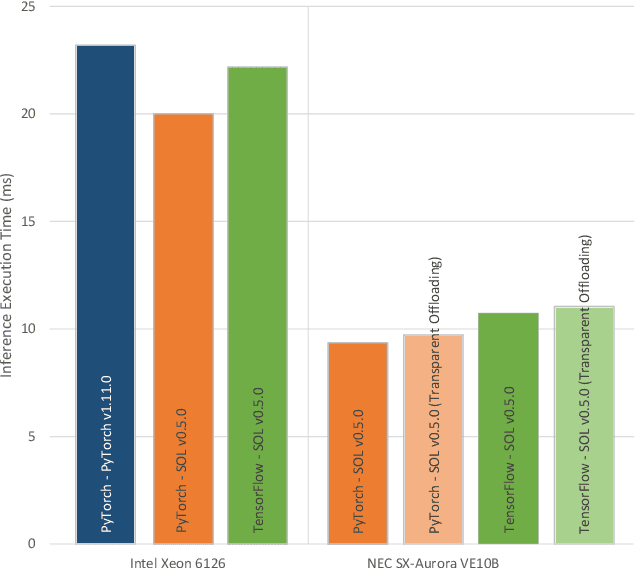

The increased interest in Artificial Intelligence (AI) raised the need for highly optimized and sophisticated AI frameworks. Starting with the Lua-based Torch many frameworks have emerged over time, such as Theano, Caffe, Chainer, CNTK, MxNet, PyTorch, DL4J, or TensorFlow. All of these provide a high level scripting API that allows users to easily design neural networks and run these on various kinds of hardware. What the user usually does not see is the high effort put into these frameworks to provide peak execution performance. While mainstream CPUs and GPUs have the "luxury" to have a wide spread user base in the open source community, less mainstream CPU, GPU or accelerator vendors need to put in a high effort to get their hardware supported by these frameworks. This includes not only the development of highly efficient compute libraries such as CUDNN, OneDNN or VEDNN but also supporting an ever growing number of simpler compute operations such as summation and multiplications. Each of these frameworks, nowadays, supports several hundred of unique operations, with tensors of various sizes, shapes and data types, which end up in thousands of compute kernels required for each device type. And the number of operations keeps increasing. That is why NEC Laboratories Europe started developing the SOL AI Optimization project already years ago, to deliver optimal performance to users while keeping the maintenance burden minimal.