 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackground Subtraction with Real-time Semantic Segmentation
Dec 12, 2018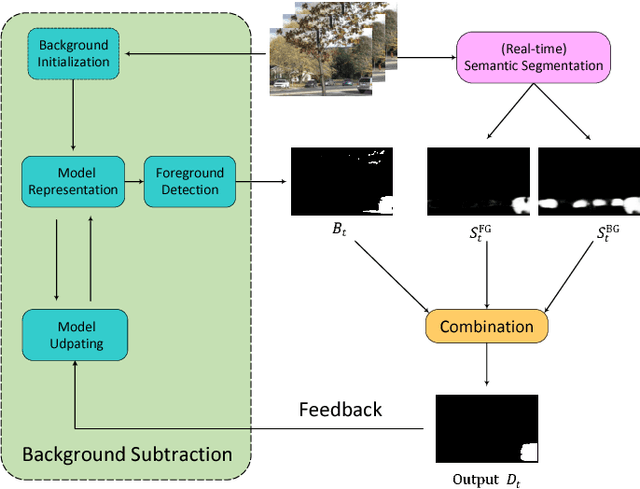
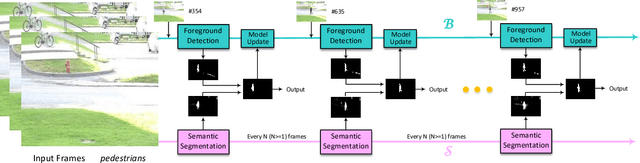


Accurate and fast foreground object extraction is very important for object tracking and recognition in video surveillance. Although many background subtraction (BGS) methods have been proposed in the recent past, it is still regarded as a tough problem due to the variety of challenging situations that occur in real-world scenarios. In this paper, we explore this problem from a new perspective and propose a novel background subtraction framework with real-time semantic segmentation (RTSS). Our proposed framework consists of two components, a traditional BGS segmenter $\mathcal{B}$ and a real-time semantic segmenter $\mathcal{S}$. The BGS segmenter $\mathcal{B}$ aims to construct background models and segments foreground objects. The real-time semantic segmenter $\mathcal{S}$ is used to refine the foreground segmentation outputs as feedbacks for improving the model updating accuracy. $\mathcal{B}$ and $\mathcal{S}$ work in parallel on two threads. For each input frame $I_t$, the BGS segmenter $\mathcal{B}$ computes a preliminary foreground/background (FG/BG) mask $B_t$. At the same time, the real-time semantic segmenter $\mathcal{S}$ extracts the object-level semantics ${S}_t$. Then, some specific rules are applied on ${B}_t$ and ${S}_t$ to generate the final detection ${D}_t$. Finally, the refined FG/BG mask ${D}_t$ is fed back to update the background model. Comprehensive experiments evaluated on the CDnet 2014 dataset demonstrate that our proposed method achieves state-of-the-art performance among all unsupervised background subtraction methods while operating at real-time, and even performs better than some deep learning based supervised algorithms. In addition, our proposed framework is very flexible and has the potential for generalization.
A Robust Local Binary Similarity Pattern for Foreground Object Detection
Oct 18, 2018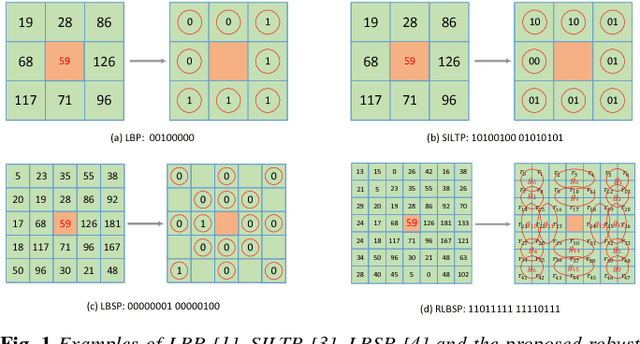

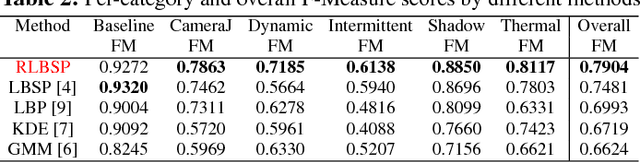
Accurate and fast extraction of the foreground object is one of the most significant issues to be solved due to its important meaning for object tracking and recognition in video surveillance. Although many foreground object detection methods have been proposed in the recent past, it is still regarded as a tough problem due to illumination variations and dynamic backgrounds challenges. In this paper, we propose a robust foreground object detection method with two aspects of contributions. First, we propose a robust texture operator named Robust Local Binary Similarity Pattern (RLBSP), which shows strong robustness to illumination variations and dynamic backgrounds. Second, a combination of color and texture features are used to characterize pixel representations, which compensate each other to make full use of their own advantages. Comprehensive experiments evaluated on the CDnet 2012 dataset demonstrate that the proposed method performs favorably against state-of-the-art methods.
Combining Background Subtraction Algorithms with Convolutional Neural Network
Jul 09, 2018Accurate and fast extraction of foreground object is a key prerequisite for a wide range of computer vision applications such as object tracking and recognition. Thus, enormous background subtraction methods for foreground object detection have been proposed in recent decades. However, it is still regarded as a tough problem due to a variety of challenges such as illumination variations, camera jitter, dynamic backgrounds, shadows, and so on. Currently, there is no single method that can handle all the challenges in a robust way. In this letter, we try to solve this problem from a new perspective by combining different state-of-the-art background subtraction algorithms to create a more robust and more advanced foreground detection algorithm. More specifically, an encoder-decoder fully convolutional neural network architecture is trained to automatically learn how to leverage the characteristics of different algorithms to fuse the results produced by different background subtraction algorithms and output a more precise result. Comprehensive experiments evaluated on the CDnet 2014 dataset demonstrate that the proposed method outperforms all the considered single background subtraction algorithm. And we show that our solution is more efficient than other combination strategies.