 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText to Image Generation with Semantic-Spatial Aware GAN
Paper and Code

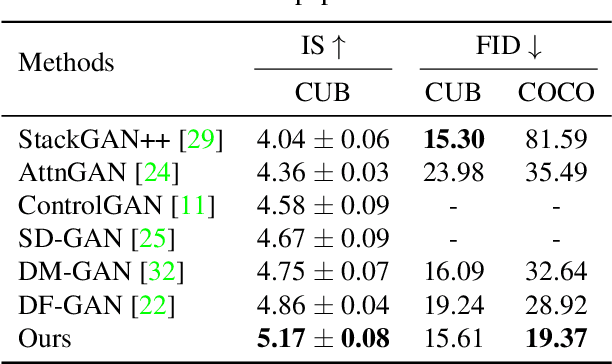


A text to image generation (T2I) model aims to generate photo-realistic images which are semantically consistent with the text descriptions. Built upon the recent advances in generative adversarial networks (GANs), existing T2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) The condition batch normalization methods are applied on the whole image feature maps equally, ignoring the local semantics; (2) The text encoder is fixed during training, which should be trained with the image generator jointly to learn better text representations for image generation. To address these limitations, we propose a novel framework Semantic-Spatial Aware GAN, which is trained in an end-to-end fashion so that the text encoder can exploit better text information. Concretely, we introduce a novel Semantic-Spatial Aware Convolution Network, which (1) learns semantic-adaptive transformation conditioned on text to effectively fuse text features and image features, and (2) learns a mask map in a weakly-supervised way that depends on the current text-image fusion process in order to guide the transformation spatially. Experiments on the challenging COCO and CUB bird datasets demonstrate the advantage of our method over the recent state-of-the-art approaches, regarding both visual fidelity and alignment with input text description. Code is available at https://github.com/wtliao/text2image.