 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Relation Transformer: Incorporating pairwise object features into the Transformer architecture
Paper and Code
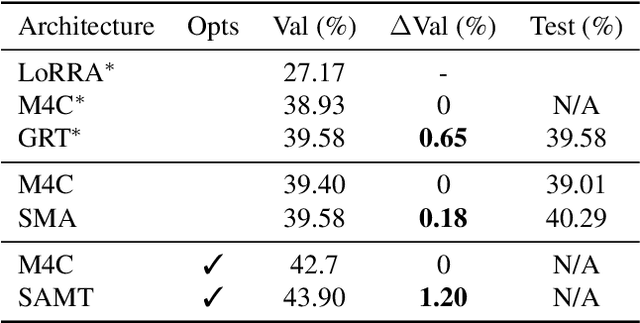
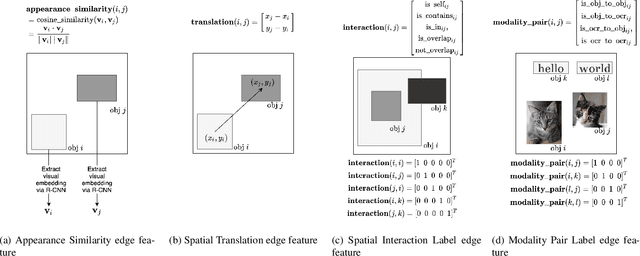

Previous studies such as VizWiz find that Visual Question Answering (VQA) systems that can read and reason about text in images are useful in application areas such as assisting visually-impaired people. TextVQA is a VQA dataset geared towards this problem, where the questions require answering systems to read and reason about visual objects and text objects in images. One key challenge in TextVQA is the design of a system that effectively reasons not only about visual and text objects individually, but also about the spatial relationships between these objects. This motivates the use of 'edge features', that is, information about the relationship between each pair of objects. Some current TextVQA models address this problem but either only use categories of relations (rather than edge feature vectors) or do not use edge features within the Transformer architectures. In order to overcome these shortcomings, we propose a Graph Relation Transformer (GRT), which uses edge information in addition to node information for graph attention computation in the Transformer. We find that, without using any other optimizations, the proposed GRT method outperforms the accuracy of the M4C baseline model by 0.65% on the val set and 0.57% on the test set. Qualitatively, we observe that the GRT has superior spatial reasoning ability to M4C.