 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Multichoice Dataset be Repurposed for Extractive Question Answering?
Apr 26, 2024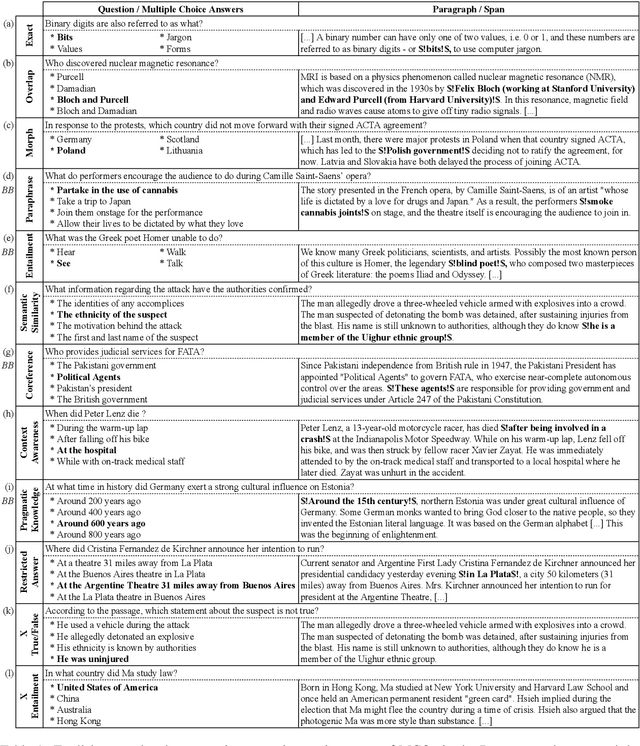

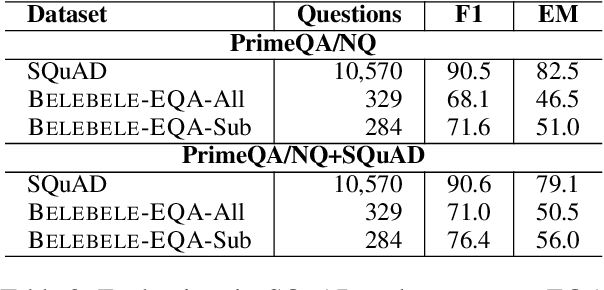
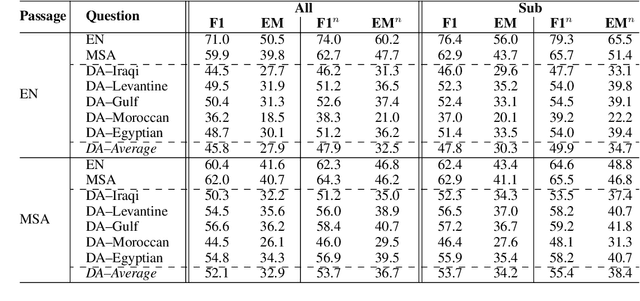
The rapid evolution of Natural Language Processing (NLP) has favored major languages such as English, leaving a significant gap for many others due to limited resources. This is especially evident in the context of data annotation, a task whose importance cannot be underestimated, but which is time-consuming and costly. Thus, any dataset for resource-poor languages is precious, in particular when it is task-specific. Here, we explore the feasibility of repurposing existing datasets for a new NLP task: we repurposed the Belebele dataset (Bandarkar et al., 2023), which was designed for multiple-choice question answering (MCQA), to enable extractive QA (EQA) in the style of machine reading comprehension. We present annotation guidelines and a parallel EQA dataset for English and Modern Standard Arabic (MSA). We also present QA evaluation results for several monolingual and cross-lingual QA pairs including English, MSA, and five Arabic dialects. Our aim is to enable others to adapt our approach for the 120+ other language variants in Belebele, many of which are deemed under-resourced. We also conduct a thorough analysis and share our insights from the process, which we hope will contribute to a deeper understanding of the challenges and the opportunities associated with task reformulation in NLP research.
Supply chain emission estimation using large language models
Aug 03, 2023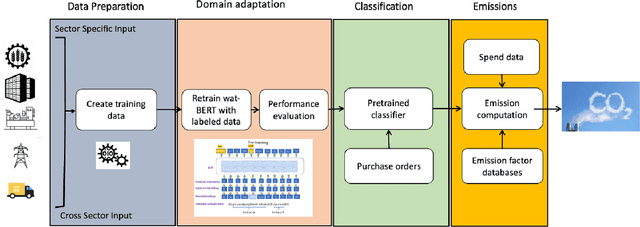



Large enterprises face a crucial imperative to achieve the Sustainable Development Goals (SDGs), especially goal 13, which focuses on combating climate change and its impacts. To mitigate the effects of climate change, reducing enterprise Scope 3 (supply chain emissions) is vital, as it accounts for more than 90\% of total emission inventories. However, tracking Scope 3 emissions proves challenging, as data must be collected from thousands of upstream and downstream suppliers.To address the above mentioned challenges, we propose a first-of-a-kind framework that uses domain-adapted NLP foundation models to estimate Scope 3 emissions, by utilizing financial transactions as a proxy for purchased goods and services. We compared the performance of the proposed framework with the state-of-art text classification models such as TF-IDF, word2Vec, and Zero shot learning. Our results show that the domain-adapted foundation model outperforms state-of-the-art text mining techniques and performs as well as a subject matter expert (SME). The proposed framework could accelerate the Scope 3 estimation at Enterprise scale and will help to take appropriate climate actions to achieve SDG 13.
Taxonomy grounded aggregation of classifiers with different label sets
Dec 01, 2015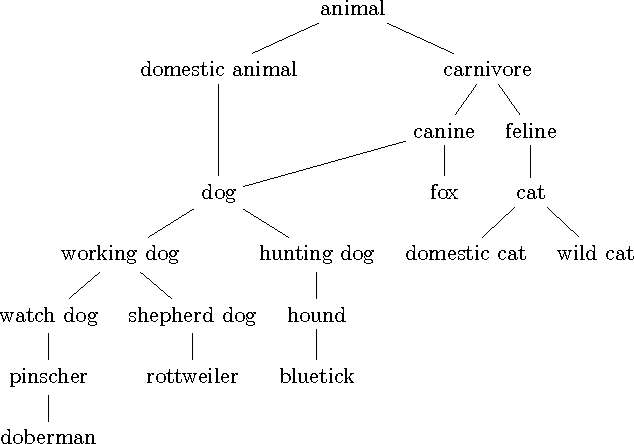
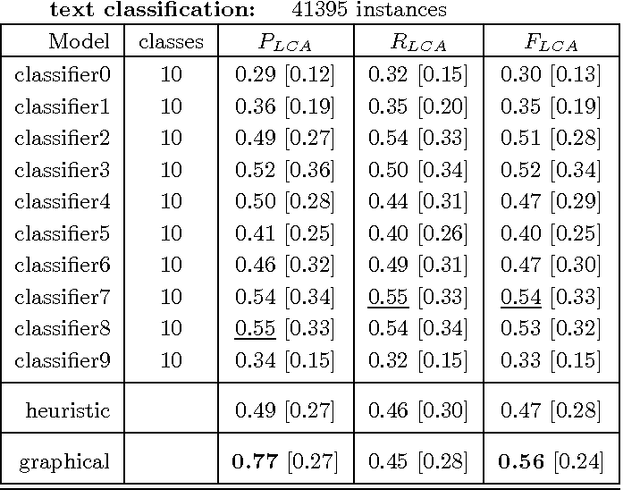
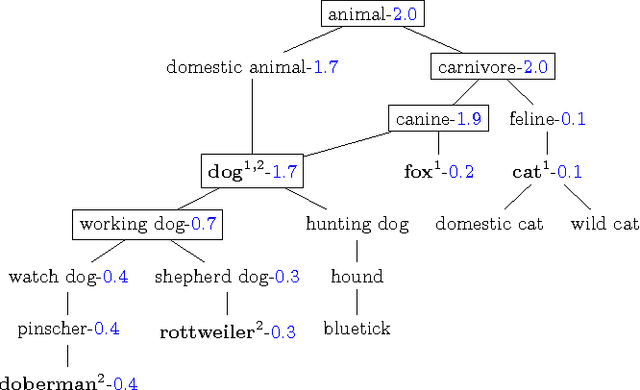
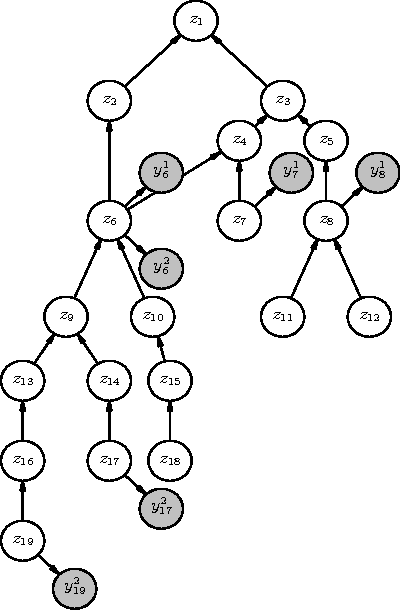
We describe the problem of aggregating the label predictions of diverse classifiers using a class taxonomy. Such a taxonomy may not have been available or referenced when the individual classifiers were designed and trained, yet mapping the output labels into the taxonomy is desirable to integrate the effort spent in training the constituent classifiers. A hierarchical taxonomy representing some domain knowledge may be different from, but partially mappable to, the label sets of the individual classifiers. We present a heuristic approach and a principled graphical model to aggregate the label predictions by grounding them into the available taxonomy. Our model aggregates the labels using the taxonomy structure as constraints to find the most likely hierarchically consistent class. We experimentally validate our proposed method on image and text classification tasks.