 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAHM : Large Annotated Dataset for Multi-Domain and Multilingual Hate Speech Identification
Apr 03, 2023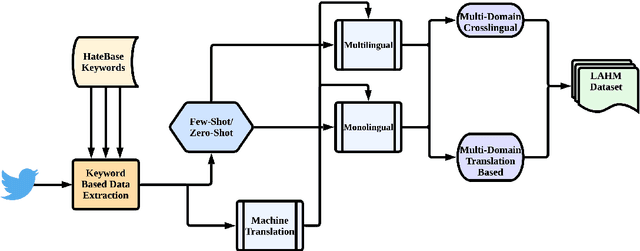
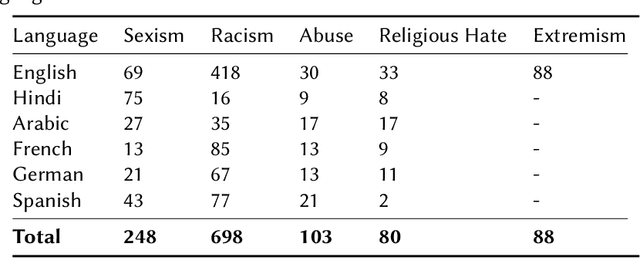
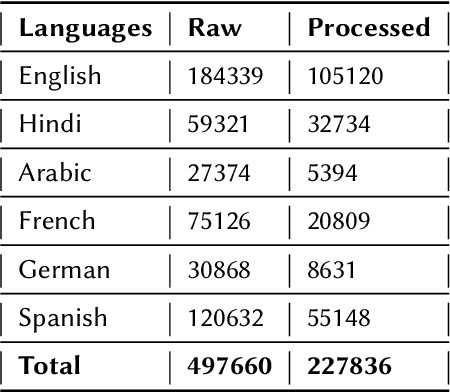
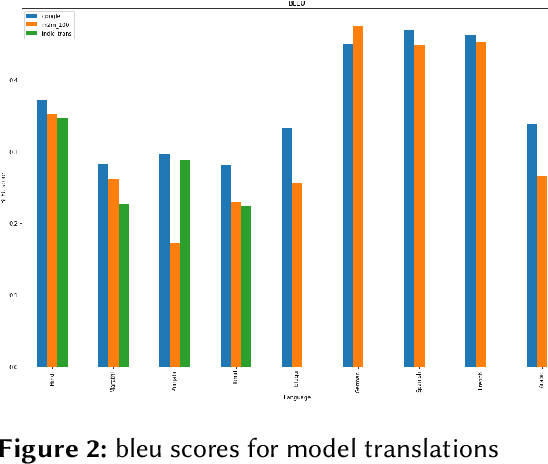
Current research on hate speech analysis is typically oriented towards monolingual and single classification tasks. In this paper, we present a new multilingual hate speech analysis dataset for English, Hindi, Arabic, French, German and Spanish languages for multiple domains across hate speech - Abuse, Racism, Sexism, Religious Hate and Extremism. To the best of our knowledge, this paper is the first to address the problem of identifying various types of hate speech in these five wide domains in these six languages. In this work, we describe how we created the dataset, created annotations at high level and low level for different domains and how we use it to test the current state-of-the-art multilingual and multitask learning approaches. We evaluate our dataset in various monolingual, cross-lingual and machine translation classification settings and compare it against open source English datasets that we aggregated and merged for this task. Then we discuss how this approach can be used to create large scale hate-speech datasets and how to leverage our annotations in order to improve hate speech detection and classification in general.