 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterspeeches up my sleeve! Intent Distribution Learning and Persistent Fusion for Intent-Conditioned Counterspeech Generation
May 23, 2023



Counterspeech has been demonstrated to be an efficacious approach for combating hate speech. While various conventional and controlled approaches have been studied in recent years to generate counterspeech, a counterspeech with a certain intent may not be sufficient in every scenario. Due to the complex and multifaceted nature of hate speech, utilizing multiple forms of counter-narratives with varying intents may be advantageous in different circumstances. In this paper, we explore intent-conditioned counterspeech generation. At first, we develop IntentCONAN, a diversified intent-specific counterspeech dataset with 6831 counterspeeches conditioned on five intents, i.e., informative, denouncing, question, positive, and humour. Subsequently, we propose QUARC, a two-stage framework for intent-conditioned counterspeech generation. QUARC leverages vector-quantized representations learned for each intent category along with PerFuMe, a novel fusion module to incorporate intent-specific information into the model. Our evaluation demonstrates that QUARC outperforms several baselines by an average of 10% across evaluation metrics. An extensive human evaluation supplements our hypothesis of better and more appropriate responses than comparative systems.
Leveraging Emotion-specific Features to Improve Transformer Performance for Emotion Classification
Apr 30, 2022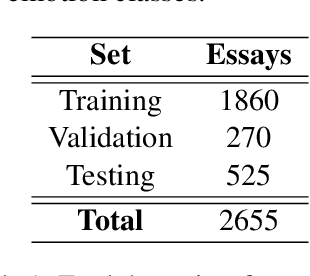
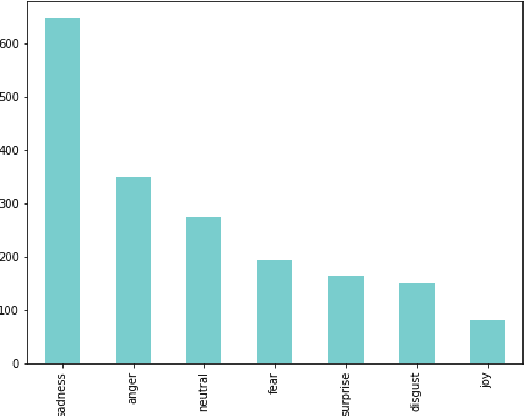
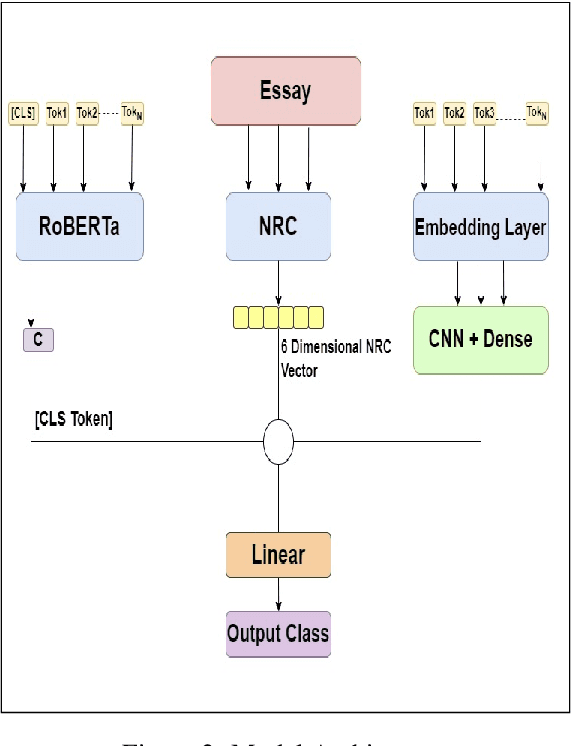
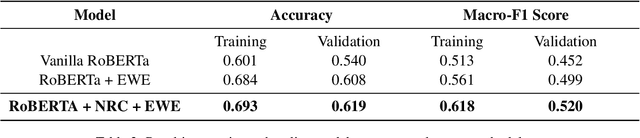
This paper describes the approach to the Emotion Classification shared task held at WASSA 2022 by team PVGs AI Club. This Track 2 sub-task focuses on building models which can predict a multi-class emotion label based on essays from news articles where a person, group or another entity is affected. Baseline transformer models have been demonstrating good results on sequence classification tasks, and we aim to improve this performance with the help of ensembling techniques, and by leveraging two variations of emotion-specific representations. We observe better results than our baseline models and achieve an accuracy of 0.619 and a macro F1 score of 0.520 on the emotion classification task.
Multitask Finetuning for Improving Neural Machine Translation in Indian Languages
Dec 03, 2021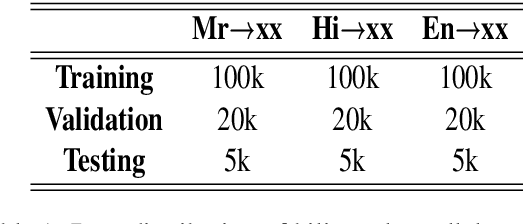
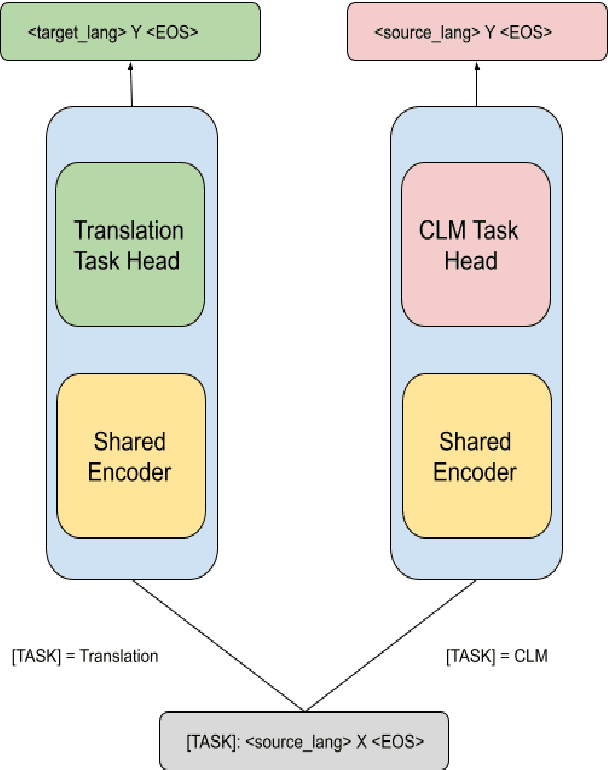


Transformer based language models have led to impressive results across all domains in Natural Language Processing. Pretraining these models on language modeling tasks and finetuning them on downstream tasks such as Text Classification, Question Answering and Neural Machine Translation has consistently shown exemplary results. In this work, we propose a Multitask Finetuning methodology which combines the Bilingual Machine Translation task with an auxiliary Causal Language Modeling task to improve performance on the former task on Indian Languages. We conduct an empirical study on three language pairs, Marathi-Hindi, Marathi-English and Hindi-English, where we compare the multitask finetuning approach to the standard finetuning approach, for which we use the mBART50 model. Our study indicates that the multitask finetuning method could be a better technique than standard finetuning, and could improve Bilingual Machine Translation across language pairs.
Combining Context-Free and Contextualized Representations for Arabic Sarcasm Detection and Sentiment Identification
Mar 09, 2021
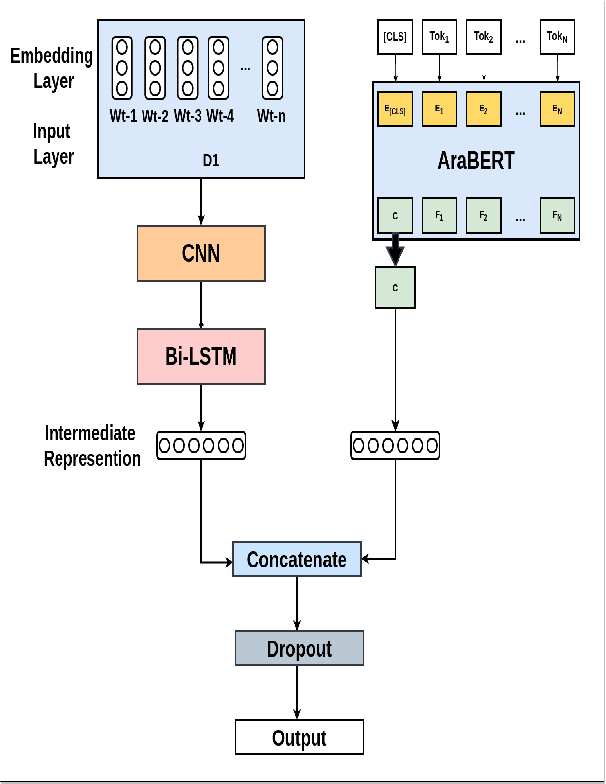
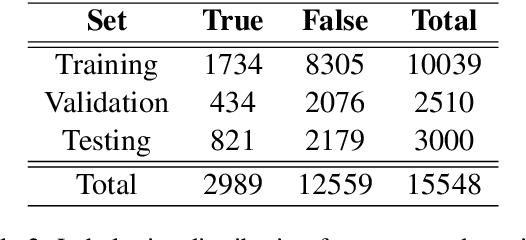
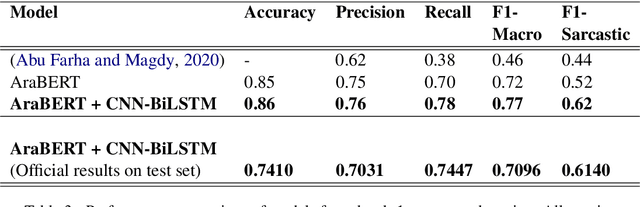
Since their inception, transformer-based language models have led to impressive performance gains across multiple natural language processing tasks. For Arabic, the current state-of-the-art results on most datasets are achieved by the AraBERT language model. Notwithstanding these recent advancements, sarcasm and sentiment detection persist to be challenging tasks in Arabic, given the language's rich morphology, linguistic disparity and dialectal variations. This paper proffers team SPPU-AASM's submission for the WANLP ArSarcasm shared-task 2021, which centers around the sarcasm and sentiment polarity detection of Arabic tweets. The study proposes a hybrid model, combining sentence representations from AraBERT with static word vectors trained on Arabic social media corpora. The proposed system achieves a F1-sarcastic score of 0.62 and a F-PN score of 0.715 for the sarcasm and sentiment detection tasks, respectively. Simulation results show that the proposed system outperforms multiple existing approaches for both the tasks, suggesting that the amalgamation of context-free and context-dependent text representations can help capture complementary facets of word meaning in Arabic. The system ranked second and tenth in the respective sub-tasks of sarcasm detection and sentiment identification.