Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoldly Going Where No Benchmark Has Gone Before: Exposing Bias and Shortcomings in Code Generation Evaluation
Paper and Code


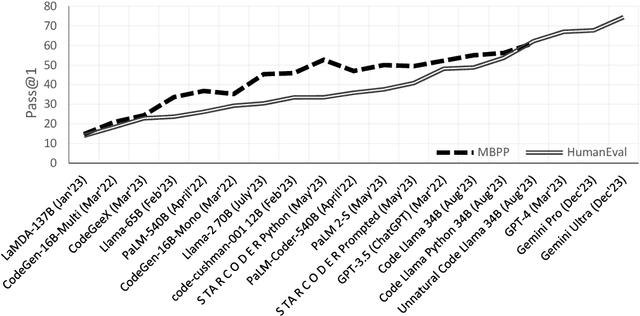
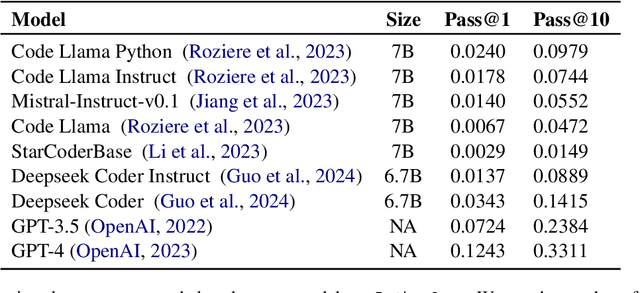
Motivated by the increasing popularity of code generation from human descriptions using large language models (LLMs), several benchmarks have been proposed to assess the capabilities of existing and emerging models. This study presents a large-scale human evaluation of HumanEval and MBPP, two widely used benchmarks for Python code generation, focusing on their diversity and difficulty. Our findings reveal a significant bias towards a limited number of programming concepts, with negligible or no representation of most concepts. Additionally, we identify a concerningly high proportion of easy programming questions, potentially leading to an overestimation of model performance on code generation tasks.
View paper on