 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification for Tree-shaped Structural Causal Models in Polynomial Time
Nov 23, 2023

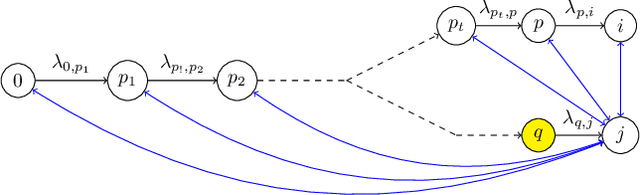
Linear structural causal models (SCMs) are used to express and analyse the relationships between random variables. Direct causal effects are represented as directed edges and confounding factors as bidirected edges. Identifying the causal parameters from correlations between the nodes is an open problem in artificial intelligence. In this paper, we study SCMs whose directed component forms a tree. Van der Zander et al. (AISTATS'22, PLMR 151, pp. 6770--6792, 2022) give a PSPACE-algorithm for the identification problem in this case, which is a significant improvement over the general Gr\"obner basis approach, which has doubly-exponential time complexity in the number of structural parameters. In this work, we present a randomized polynomial-time algorithm, which solves the identification problem for tree-shaped SCMs. For every structural parameter, our algorithms decides whether it is generically identifiable, generically 2-identifiable, or generically unidentifiable. (No other cases can occur.) In the first two cases, it provides one or two fractional affine square root terms of polynomials (FASTPs) for the corresponding parameter, respectively.
Adversarial Adaptation for French Named Entity Recognition
Jan 12, 2023

Named Entity Recognition (NER) is the task of identifying and classifying named entities in large-scale texts into predefined classes. NER in French and other relatively limited-resource languages cannot always benefit from approaches proposed for languages like English due to a dearth of large, robust datasets. In this paper, we present our work that aims to mitigate the effects of this dearth of large, labeled datasets. We propose a Transformer-based NER approach for French, using adversarial adaptation to similar domain or general corpora to improve feature extraction and enable better generalization. Our approach allows learning better features using large-scale unlabeled corpora from the same domain or mixed domains to introduce more variations during training and reduce overfitting. Experimental results on three labeled datasets show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of Transformer models, source datasets, and target corpora. We also show that adversarial adaptation to large-scale unlabeled corpora can help mitigate the performance dip incurred on using Transformer models pre-trained on smaller corpora.
Transformer-Based Named Entity Recognition for French Using Adversarial Adaptation to Similar Domain Corpora
Dec 05, 2022
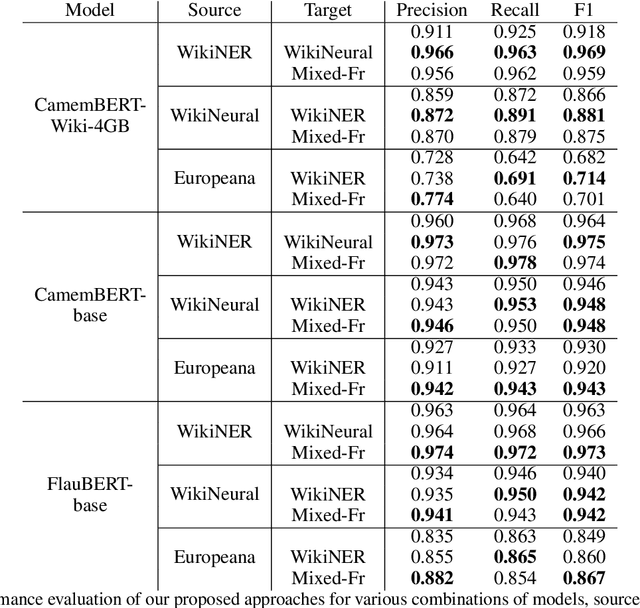
Named Entity Recognition (NER) involves the identification and classification of named entities in unstructured text into predefined classes. NER in languages with limited resources, like French, is still an open problem due to the lack of large, robust, labelled datasets. In this paper, we propose a transformer-based NER approach for French using adversarial adaptation to similar domain or general corpora for improved feature extraction and better generalization. We evaluate our approach on three labelled datasets and show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of transformer models, source datasets and target corpora.
A Spreader Ranking Algorithm for Extremely Low-budget Influence Maximization in Social Networks using Community Bridge Nodes
Nov 17, 2022



In recent years, social networking platforms have gained significant popularity among the masses like connecting with people and propagating ones thoughts and opinions. This has opened the door to user-specific advertisements and recommendations on these platforms, bringing along a significant focus on Influence Maximisation (IM) on social networks due to its wide applicability in target advertising, viral marketing, and personalized recommendations. The aim of IM is to identify certain nodes in the network which can help maximize the spread of certain information through a diffusion cascade. While several works have been proposed for IM, most were inefficient in exploiting community structures to their full extent. In this work, we propose a community structures-based approach, which employs a K-Shell algorithm in order to generate a score for the connections between seed nodes and communities for low-budget scenarios. Further, our approach employs entropy within communities to ensure the proper spread of information within the communities. We choose the Independent Cascade (IC) model to simulate information spread and evaluate it on four evaluation metrics. We validate our proposed approach on eight publicly available networks and find that it significantly outperforms the baseline approaches on these metrics, while still being relatively efficient.